 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Cognitive Gap: A Unified Memory Paradigm for 6G Agentic AI-RAN
May 11, 2026As 6G evolves, the radio access network must transcend traditional automation to embrace agentic AI capable of perception, reasoning, and evolution. A fundamental cognitive gap persists in current disaggregated architectures, where interfaces force the physical layer to compress high-dimensional states into low-dimensional metrics, trapping reasoning agents behind a semantic bottleneck. This article envisions a shift from interface-bound to memory-centric architectures. We propose a unified memory paradigm that dissolves the boundaries between sensing and reasoning by mapping biological memory hierarchies onto heterogeneous computing fabrics. Enabled by emerging coherent interconnects, this approach creates a cognitive continuum where microsecond-level reflexes, millisecond-level reasoning, and long-term evolution share state across time scales. By replacing message passing with zero-copy observability, we empower AI agents to bridge the gap between real-time responsiveness and long-horizon context for truly autonomous 6G networks.
Timely Parameter Updating in Over-the-Air Federated Learning
Dec 22, 2025Incorporating over-the-air computations (OAC) into the model training process of federated learning (FL) is an effective approach to alleviating the communication bottleneck in FL systems. Under OAC-FL, every client modulates its intermediate parameters, such as gradient, onto the same set of orthogonal waveforms and simultaneously transmits the radio signal to the edge server. By exploiting the superposition property of multiple-access channels, the edge server can obtain an automatically aggregated global gradient from the received signal. However, the limited number of orthogonal waveforms available in practical systems is fundamentally mismatched with the high dimensionality of modern deep learning models. To address this issue, we propose Freshness Freshness-mAgnItude awaRe top-k (FAIR-k), an algorithm that selects, in each communication round, the most impactful subset of gradients to be updated over the air. In essence, FAIR-k combines the complementary strengths of the Round-Robin and Top-k algorithms, striking a delicate balance between timeliness (freshness of parameter updates) and importance (gradient magnitude). Leveraging tools from Markov analysis, we characterize the distribution of parameter staleness under FAIR-k. Building on this, we establish the convergence rate of OAC-FL with FAIR-k, which discloses the joint effect of data heterogeneity, channel noise, and parameter staleness on the training efficiency. Notably, as opposed to conventional analyses that assume a universal Lipschitz constant across all the clients, our framework adopts a finer-grained model of the data heterogeneity. The analysis demonstrates that since FAIR-k promotes fresh (and fair) parameter updates, it not only accelerates convergence but also enhances communication efficiency by enabling an extended period of local training without significantly affecting overall training efficiency.
Rethinking Federated Learning Over the Air: The Blessing of Scaling Up
Aug 25, 2025Federated learning facilitates collaborative model training across multiple clients while preserving data privacy. However, its performance is often constrained by limited communication resources, particularly in systems supporting a large number of clients. To address this challenge, integrating over-the-air computations into the training process has emerged as a promising solution to alleviate communication bottlenecks. The system significantly increases the number of clients it can support in each communication round by transmitting intermediate parameters via analog signals rather than digital ones. This improvement, however, comes at the cost of channel-induced distortions, such as fading and noise, which affect the aggregated global parameters. To elucidate these effects, this paper develops a theoretical framework to analyze the performance of over-the-air federated learning in large-scale client scenarios. Our analysis reveals three key advantages of scaling up the number of participating clients: (1) Enhanced Privacy: The mutual information between a client's local gradient and the server's aggregated gradient diminishes, effectively reducing privacy leakage. (2) Mitigation of Channel Fading: The channel hardening effect eliminates the impact of small-scale fading in the noisy global gradient. (3) Improved Convergence: Reduced thermal noise and gradient estimation errors benefit the convergence rate. These findings solidify over-the-air model training as a viable approach for federated learning in networks with a large number of clients. The theoretical insights are further substantiated through extensive experimental evaluations.
Energy-Efficient Federated Learning and Migration in Digital Twin Edge Networks
Mar 20, 2025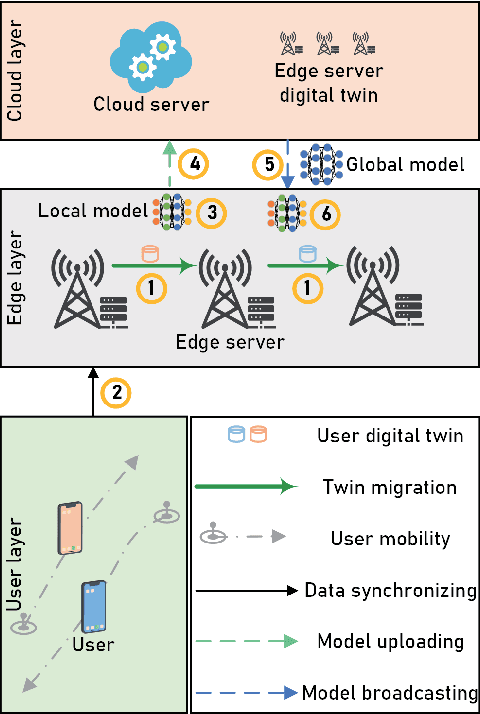
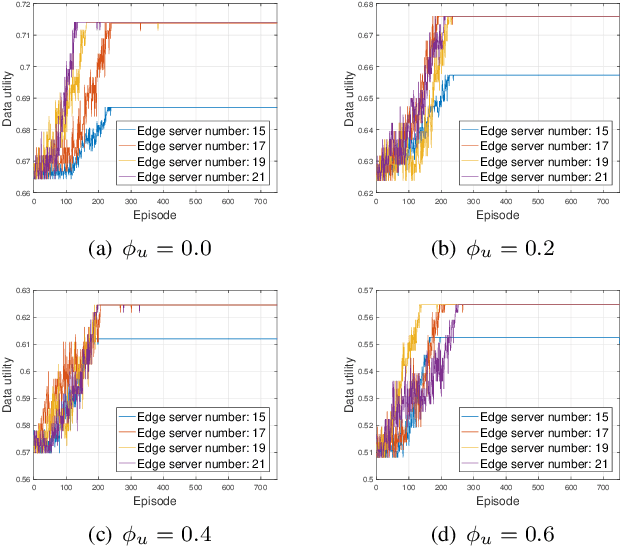
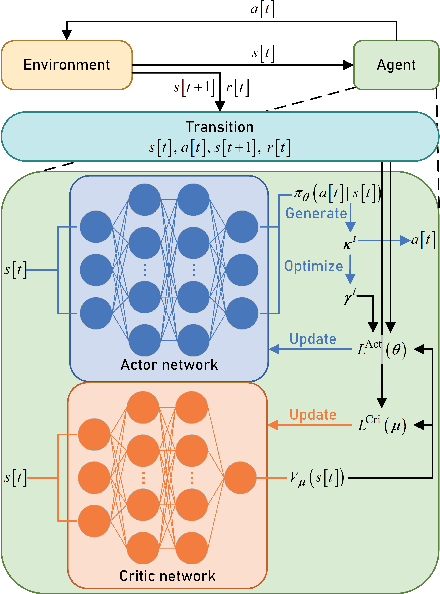
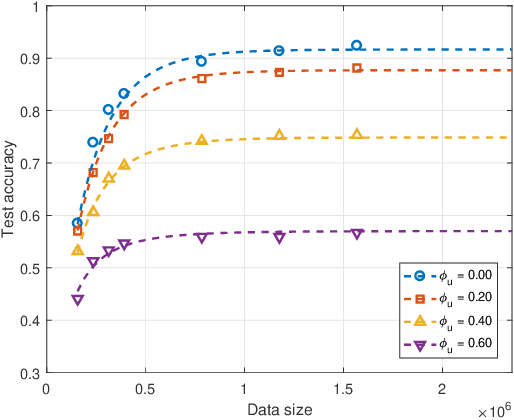
The digital twin edge network (DITEN) is a significant paradigm in the sixth-generation wireless system (6G) that aims to organize well-developed infrastructures to meet the requirements of evolving application scenarios. However, the impact of the interaction between the long-term DITEN maintenance and detailed digital twin tasks, which often entail privacy considerations, is commonly overlooked in current research. This paper addresses this issue by introducing a problem of digital twin association and historical data allocation for a federated learning (FL) task within DITEN. To achieve this goal, we start by introducing a closed-form function to predict the training accuracy of the FL task, referring to it as the data utility. Subsequently, we carry out comprehensive convergence analyses on the proposed FL methodology. Our objective is to jointly optimize the data utility of the digital twin-empowered FL task and the energy costs incurred by the long-term DITEN maintenance, encompassing FL model training, data synchronization, and twin migration. To tackle the aforementioned challenge, we present an optimization-driven learning algorithm that effectively identifies optimized solutions for the formulated problem. Numerical results demonstrate that our proposed algorithm outperforms various baseline approaches.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
MoE$^2$: Optimizing Collaborative Inference for Edge Large Language Models
Jan 16, 2025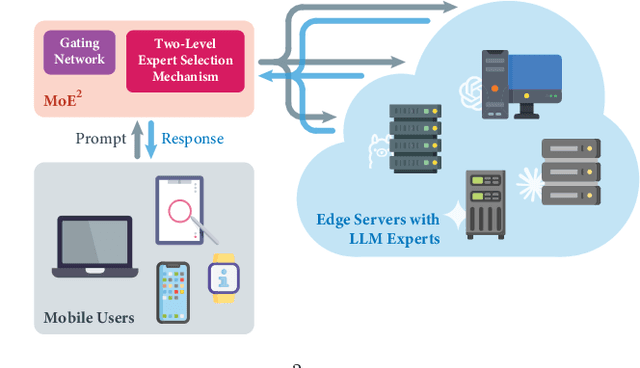



Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing tasks. Exploiting the heterogeneous capabilities of edge LLMs is crucial for diverse emerging applications, as it enables greater cost-effectiveness and reduced latency. In this work, we introduce \textit{Mixture-of-Edge-Experts (MoE$^2$)}, a novel collaborative inference framework for edge LLMs. We formulate the joint gating and expert selection problem to optimize inference performance under energy and latency constraints. Unlike conventional MoE problems, LLM expert selection is significantly more challenging due to the combinatorial nature and the heterogeneity of edge LLMs across various attributes. To this end, we propose a two-level expert selection mechanism through which we uncover an optimality-preserving property of gating parameters across expert selections. This property enables the decomposition of the training and selection processes, significantly reducing complexity. Furthermore, we leverage the objective's monotonicity and design a discrete monotonic optimization algorithm for optimal expert selection. We implement edge servers with NVIDIA Jetson AGX Orins and NVIDIA RTX 4090 GPUs, and perform extensive experiments. Our results validate that performance improvements of various LLM models and show that our MoE$^2$ method can achieve optimal trade-offs among different delay and energy budgets, and outperforms baselines under various system resource constraints.
Towards General Industrial Intelligence: A Survey on IIoT-Enhanced Continual Large Models
Sep 02, 2024



Currently, most applications in the Industrial Internet of Things (IIoT) still rely on CNN-based neural networks. Although Transformer-based large models (LMs), including language, vision, and multimodal models, have demonstrated impressive capabilities in AI-generated content (AIGC), their application in industrial domains, such as detection, planning, and control, remains relatively limited. Deploying pre-trained LMs in industrial environments often encounters the challenge of stability and plasticity due to the complexity of tasks, the diversity of data, and the dynamic nature of user demands. To address these challenges, the pre-training and fine-tuning strategy, coupled with continual learning, has proven to be an effective solution, enabling models to adapt to dynamic demands while continuously optimizing their inference and decision-making capabilities. This paper surveys the integration of LMs into IIoT-enhanced General Industrial Intelligence (GII), focusing on two key areas: LMs for GII and LMs on GII. The former focuses on leveraging LMs to provide optimized solutions for industrial application challenges, while the latter investigates continuous optimization of LMs learning and inference capabilities in collaborative scenarios involving industrial devices, edge computing, and cloud computing. This paper provides insights into the future development of GII, aiming to establish a comprehensive theoretical framework and research direction for GII, thereby advancing GII towards a more general and adaptive future.
Trustworthy Image Semantic Communication with GenAI: Explainablity, Controllability, and Efficiency
Aug 07, 2024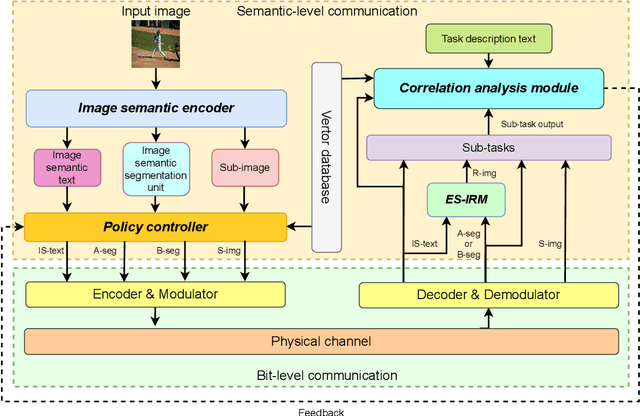
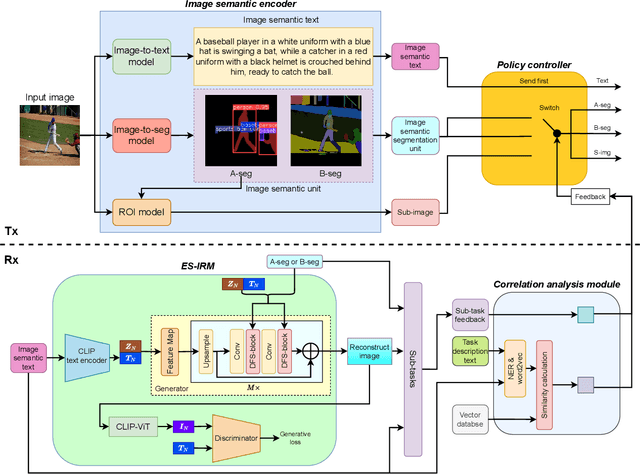

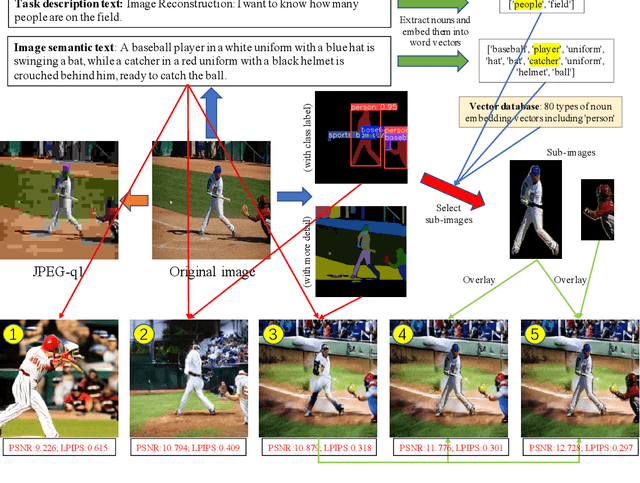
Image semantic communication (ISC) has garnered significant attention for its potential to achieve high efficiency in visual content transmission. However, existing ISC systems based on joint source-channel coding face challenges in interpretability, operability, and compatibility. To address these limitations, we propose a novel trustworthy ISC framework. This approach leverages text extraction and segmentation mapping techniques to convert images into explainable semantics, while employing Generative Artificial Intelligence (GenAI) for multiple downstream inference tasks. We also introduce a multi-rate ISC transmission protocol that dynamically adapts to both the received explainable semantic content and specific task requirements at the receiver. Simulation results demonstrate that our framework achieves explainable learning, decoupled training, and compatible transmission in various application scenarios. Finally, some intriguing research directions and application scenarios are identified.
Timeliness of Status Update System: The Effect of Parallel Transmission Using Heterogeneous Updating Devices
May 27, 2024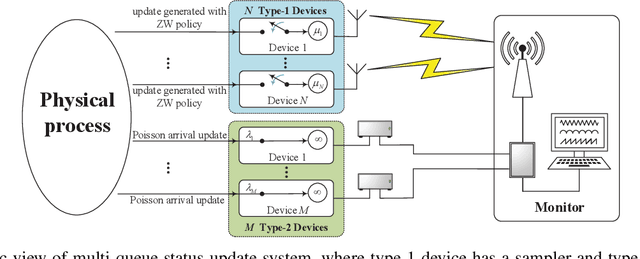
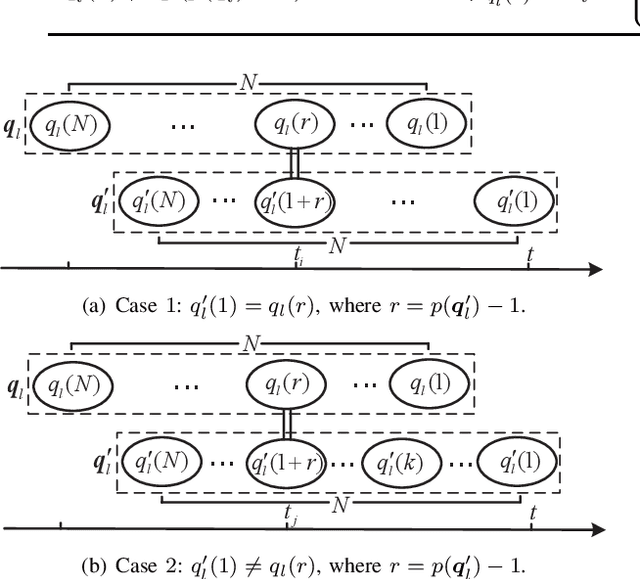
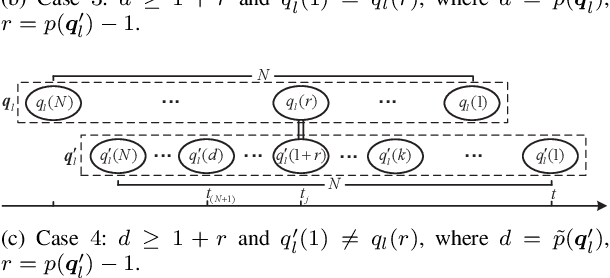
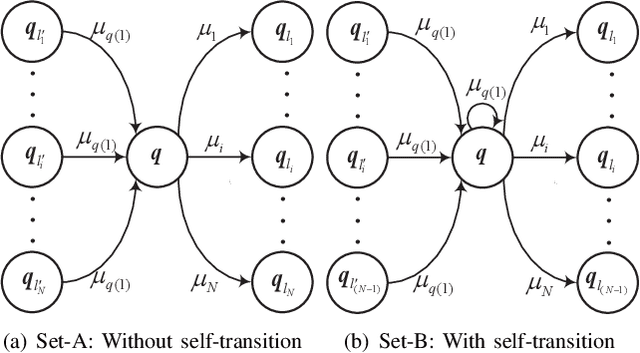
Timely status updating is the premise of emerging interaction-based applications in the Internet of Things (IoT). Using redundant devices to update the status of interest is a promising method to improve the timeliness of information. However, parallel status updating leads to out-of-order arrivals at the monitor, significantly challenging timeliness analysis. This work studies the Age of Information (AoI) of a multi-queue status update system where multiple devices monitor the same physical process. Specifically, two systems are considered: the Basic System, which only has type-1 devices that are ad hoc devices located close to the source, and the Hybrid System, which contains additional type-2 devices that are infrastructure-based devices located in fixed points compared to the Basic System. Using the Stochastic Hybrid Systems (SHS) framework, a mathematical model that combines discrete and continuous dynamics, we derive the expressions of the average AoI of the considered two systems in closed form. Numerical results verify the accuracy of the analysis. It is shown that when the number and parameters of the type-1 devices/type-2 devices are fixed, the logarithm of average AoI will linearly decrease with the logarithm of the total arrival rate of type-2 devices or that of the number of type-1 devices under specific condition. It has also been demonstrated that the proposed systems can significantly outperform the FCFS M/M/N status update system.
The Meta Distribution of the SIR in Joint Communication and Sensing Networks
Apr 02, 2024In this paper, we introduce a novel mathematical framework for assessing the performance of joint communication and sensing (JCAS) in wireless networks, employing stochastic geometry as an analytical tool. We focus on deriving the meta distribution of the signal-to-interference ratio (SIR) for JCAS networks. This approach enables a fine-grained quantification of individual user or radar performance intrinsic to these networks. Our work involves the modeling of JCAS networks and the derivation of mathematical expressions for the JCAS SIR meta distribution. Through simulations, we validate both our theoretical analysis and illustrate how the JCAS SIR meta distribution varies with the network deployment density.