 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Search, But Scan: Benchmarking MLLMs on Scan-Oriented Academic Paper Reasoning
Mar 27, 2026With the rapid progress of multimodal large language models (MLLMs), AI already performs well at literature retrieval and certain reasoning tasks, serving as a capable assistant to human researchers, yet it remains far from autonomous research. The fundamental reason is that current work on academic paper reasoning is largely confined to a search-oriented paradigm centered on pre-specified targets, with reasoning grounded in relevance retrieval, which struggles to support researcher-style full-document understanding, reasoning, and verification. To bridge this gap, we propose \textbf{ScholScan}, a new benchmark for academic paper reasoning. ScholScan introduces a scan-oriented task setting that asks models to read and cross-check entire papers like human researchers, scanning the document to identify consistency issues. The benchmark comprises 1,800 carefully annotated questions drawn from nine error categories across 13 natural-science domains and 715 papers, and provides detailed annotations for evidence localization and reasoning traces, together with a unified evaluation protocol. We assessed 15 models across 24 input configurations and conducted a fine-grained analysis of MLLM capabilities for all error categories. Across the board, retrieval-augmented generation (RAG) methods yield no significant improvements, revealing systematic deficiencies of current MLLMs on scan-oriented tasks and underscoring the challenge posed by ScholScan. We expect ScholScan to be the leading and representative work of the scan-oriented task paradigm.
FinMMDocR: Benchmarking Financial Multimodal Reasoning with Scenario Awareness, Document Understanding, and Multi-Step Computation
Dec 31, 2025We introduce FinMMDocR, a novel bilingual multimodal benchmark for evaluating multimodal large language models (MLLMs) on real-world financial numerical reasoning. Compared to existing benchmarks, our work delivers three major advancements. (1) Scenario Awareness: 57.9% of 1,200 expert-annotated problems incorporate 12 types of implicit financial scenarios (e.g., Portfolio Management), challenging models to perform expert-level reasoning based on assumptions; (2) Document Understanding: 837 Chinese/English documents spanning 9 types (e.g., Company Research) average 50.8 pages with rich visual elements, significantly surpassing existing benchmarks in both breadth and depth of financial documents; (3) Multi-Step Computation: Problems demand 11-step reasoning on average (5.3 extraction + 5.7 calculation steps), with 65.0% requiring cross-page evidence (2.4 pages average). The best-performing MLLM achieves only 58.0% accuracy, and different retrieval-augmented generation (RAG) methods show significant performance variations on this task. We expect FinMMDocR to drive improvements in MLLMs and reasoning-enhanced methods on complex multimodal reasoning tasks in real-world scenarios.
FinMMR: Make Financial Numerical Reasoning More Multimodal, Comprehensive, and Challenging
Aug 06, 2025We present FinMMR, a novel bilingual multimodal benchmark tailored to evaluate the reasoning capabilities of multimodal large language models (MLLMs) in financial numerical reasoning tasks. Compared to existing benchmarks, our work introduces three significant advancements. (1) Multimodality: We meticulously transform existing financial reasoning benchmarks, and construct novel questions from the latest Chinese financial research reports. FinMMR comprises 4.3K questions and 8.7K images spanning 14 categories, including tables, bar charts, and ownership structure charts. (2) Comprehensiveness: FinMMR encompasses 14 financial subdomains, including corporate finance, banking, and industry analysis, significantly exceeding existing benchmarks in financial domain knowledge breadth. (3) Challenge: Models are required to perform multi-step precise numerical reasoning by integrating financial knowledge with the understanding of complex financial images and text. The best-performing MLLM achieves only 53.0% accuracy on Hard problems. We believe that FinMMR will drive advancements in enhancing the reasoning capabilities of MLLMs in real-world scenarios.
Meet Me at the Arm: The Cooperative Multi-Armed Bandits Problem with Shareable Arms
Jun 11, 2025
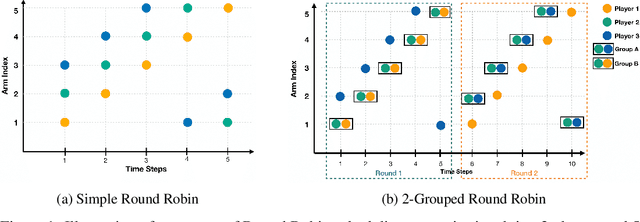
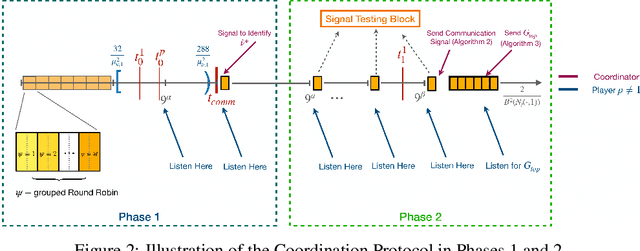
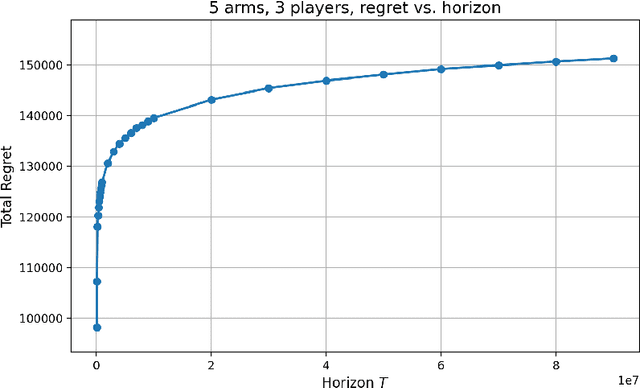
We study the decentralized multi-player multi-armed bandits (MMAB) problem under a no-sensing setting, where each player receives only their own reward and obtains no information about collisions. Each arm has an unknown capacity, and if the number of players pulling an arm exceeds its capacity, all players involved receive zero reward. This setting generalizes the classical unit-capacity model and introduces new challenges in coordination and capacity discovery under severe feedback limitations. We propose A-CAPELLA (Algorithm for Capacity-Aware Parallel Elimination for Learning and Allocation), a decentralized algorithm that achieves logarithmic regret in this generalized regime. Our main contribution is a collaborative hypothesis testing protocol that enables synchronized successive elimination and capacity estimation through carefully structured collision patterns. This represents a provably efficient learning result in decentralized no-sensing MMAB with unknown arm capacities.
Delayed Random Partial Gradient Averaging for Federated Learning
Dec 28, 2024



Federated learning (FL) is a distributed machine learning paradigm that enables multiple clients to train a shared model collaboratively while preserving privacy. However, the scaling of real-world FL systems is often limited by two communication bottlenecks:(a) while the increasing computing power of edge devices enables the deployment of large-scale Deep Neural Networks (DNNs), the limited bandwidth constraints frequent transmissions over large DNNs; and (b) high latency cost greatly degrades the performance of FL. In light of these bottlenecks, we propose a Delayed Random Partial Gradient Averaging (DPGA) to enhance FL. Under DPGA, clients only share partial local model gradients with the server. The size of the shared part in a local model is determined by the update rate, which is coarsely initialized and subsequently refined over the temporal dimension. Moreover, DPGA largely reduces the system run time by enabling computation in parallel with communication. We conduct experiments on non-IID CIFAR-10/100 to demonstrate the efficacy of our method.
CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Patterns
Sep 27, 2024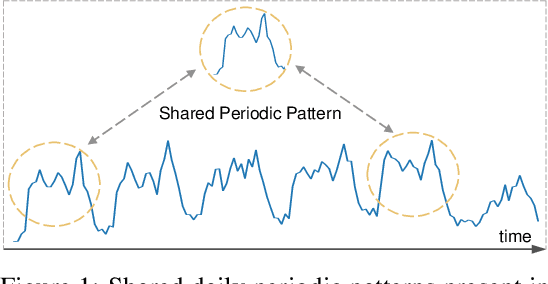
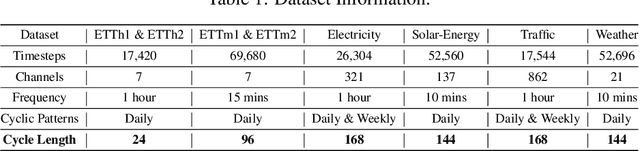
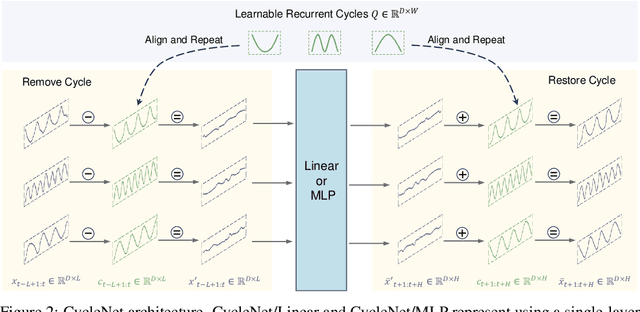
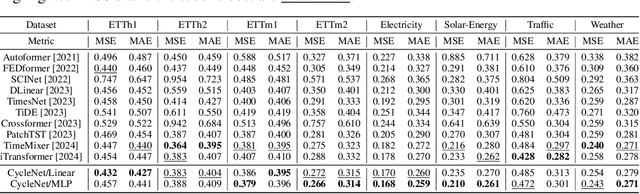
The stable periodic patterns present in time series data serve as the foundation for conducting long-horizon forecasts. In this paper, we pioneer the exploration of explicitly modeling this periodicity to enhance the performance of models in long-term time series forecasting (LTSF) tasks. Specifically, we introduce the Residual Cycle Forecasting (RCF) technique, which utilizes learnable recurrent cycles to model the inherent periodic patterns within sequences, and then performs predictions on the residual components of the modeled cycles. Combining RCF with a Linear layer or a shallow MLP forms the simple yet powerful method proposed in this paper, called CycleNet. CycleNet achieves state-of-the-art prediction accuracy in multiple domains including electricity, weather, and energy, while offering significant efficiency advantages by reducing over 90% of the required parameter quantity. Furthermore, as a novel plug-and-play technique, the RCF can also significantly improve the prediction accuracy of existing models, including PatchTST and iTransformer. The source code is available at: https://github.com/ACAT-SCUT/CycleNet.
Improving Autoregressive Training with Dynamic Oracles
Jun 13, 2024



Many tasks within NLP can be framed as sequential decision problems, ranging from sequence tagging to text generation. However, for many tasks, the standard training methods, including maximum likelihood (teacher forcing) and scheduled sampling, suffer from exposure bias and a mismatch between metrics employed during training and inference. DAgger provides a solution to mitigate these problems, yet it requires a metric-specific dynamic oracle algorithm, which does not exist for many common metrics like span-based F1, ROUGE, and BLEU. In this paper, we develop these novel dynamic oracles and show they maintain DAgger's no-regret guarantee for decomposable metrics like span-based F1. We evaluate the algorithm's performance on named entity recognition (NER), text summarization, and machine translation (MT). While DAgger with dynamic oracle yields less favorable results in our MT experiments, it outperforms the baseline techniques in NER and text summarization.
Version age-based client scheduling policy for federated learning
Feb 08, 2024



Federated Learning (FL) has emerged as a privacy-preserving machine learning paradigm facilitating collaborative training across multiple clients without sharing local data. Despite advancements in edge device capabilities, communication bottlenecks present challenges in aggregating a large number of clients; only a portion of the clients can update their parameters upon each global aggregation. This phenomenon introduces the critical challenge of stragglers in FL and the profound impact of client scheduling policies on global model convergence and stability. Existing scheduling strategies address staleness but predominantly focus on either timeliness or content. Motivated by this, we introduce the novel concept of Version Age of Information (VAoI) to FL. Unlike traditional Age of Information metrics, VAoI considers both timeliness and content staleness. Each client's version age is updated discretely, indicating the freshness of information. VAoI is incorporated into the client scheduling policy to minimize the average VAoI, mitigating the impact of outdated local updates and enhancing the stability of FL systems.
Learning Mutually Informed Representations for Characters and Subwords
Nov 14, 2023



Most pretrained language models rely on subword tokenization, which processes text as a sequence of subword tokens. However, different granularities of text, such as characters, subwords, and words, can contain different kinds of information. Previous studies have shown that incorporating multiple input granularities improves model generalization, yet very few of them outputs useful representations for each granularity. In this paper, we introduce the entanglement model, aiming to combine character and subword language models. Inspired by vision-language models, our model treats characters and subwords as separate modalities, and it generates mutually informed representations for both granularities as output. We evaluate our model on text classification, named entity recognition, and POS-tagging tasks. Notably, the entanglement model outperforms its backbone language models, particularly in the presence of noisy texts and low-resource languages. Furthermore, the entanglement model even outperforms larger pre-trained models on all English sequence labeling tasks and classification tasks. Our anonymized code is available at https://anonymous.4open.science/r/noisy-IE-A673
Two-Stage Predict+Optimize for Mixed Integer Linear Programs with Unknown Parameters in Constraints
Nov 14, 2023
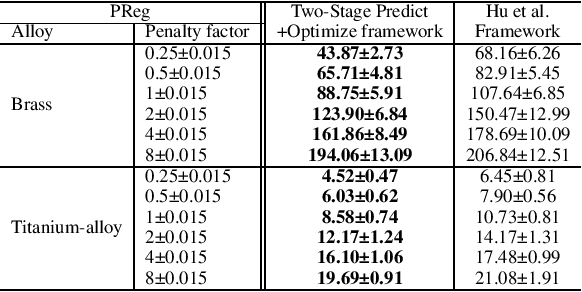
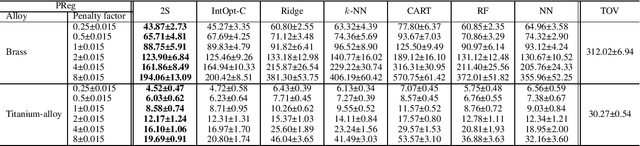
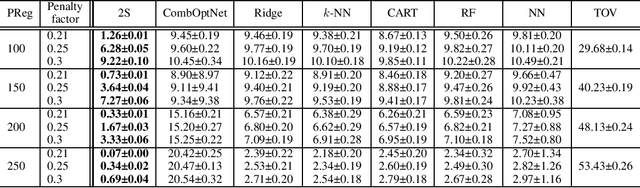
Consider the setting of constrained optimization, with some parameters unknown at solving time and requiring prediction from relevant features. Predict+Optimize is a recent framework for end-to-end training supervised learning models for such predictions, incorporating information about the optimization problem in the training process in order to yield better predictions in terms of the quality of the predicted solution under the true parameters. Almost all prior works have focused on the special case where the unknowns appear only in the optimization objective and not the constraints. Hu et al.~proposed the first adaptation of Predict+Optimize to handle unknowns appearing in constraints, but the framework has somewhat ad-hoc elements, and they provided a training algorithm only for covering and packing linear programs. In this work, we give a new \emph{simpler} and \emph{more powerful} framework called \emph{Two-Stage Predict+Optimize}, which we believe should be the canonical framework for the Predict+Optimize setting. We also give a training algorithm usable for all mixed integer linear programs, vastly generalizing the applicability of the framework. Experimental results demonstrate the superior prediction performance of our training framework over all classical and state-of-the-art methods.