 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Autoregressive Training with Dynamic Oracles
Jun 13, 2024



Many tasks within NLP can be framed as sequential decision problems, ranging from sequence tagging to text generation. However, for many tasks, the standard training methods, including maximum likelihood (teacher forcing) and scheduled sampling, suffer from exposure bias and a mismatch between metrics employed during training and inference. DAgger provides a solution to mitigate these problems, yet it requires a metric-specific dynamic oracle algorithm, which does not exist for many common metrics like span-based F1, ROUGE, and BLEU. In this paper, we develop these novel dynamic oracles and show they maintain DAgger's no-regret guarantee for decomposable metrics like span-based F1. We evaluate the algorithm's performance on named entity recognition (NER), text summarization, and machine translation (MT). While DAgger with dynamic oracle yields less favorable results in our MT experiments, it outperforms the baseline techniques in NER and text summarization.
Towards modular and programmable architecture search
Sep 30, 2019
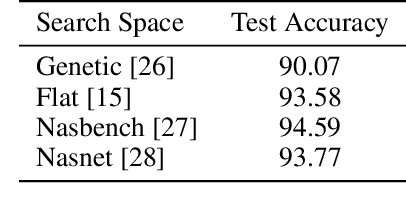

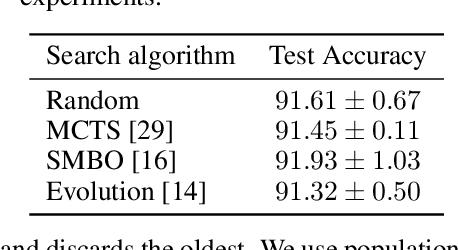
Neural architecture search methods are able to find high performance deep learning architectures with minimal effort from an expert. However, current systems focus on specific use-cases (e.g. convolutional image classifiers and recurrent language models), making them unsuitable for general use-cases that an expert might wish to write. Hyperparameter optimization systems are general-purpose but lack the constructs needed for easy application to architecture search. In this work, we propose a formal language for encoding search spaces over general computational graphs. The language constructs allow us to write modular, composable, and reusable search space encodings and to reason about search space design. We use our language to encode search spaces from the architecture search literature. The language allows us to decouple the implementations of the search space and the search algorithm, allowing us to expose search spaces to search algorithms through a consistent interface. Our experiments show the ease with which we can experiment with different combinations of search spaces and search algorithms without having to implement each combination from scratch. We release an implementation of our language with this paper.
Embedding Lexical Features via Low-Rank Tensors
Apr 02, 2016


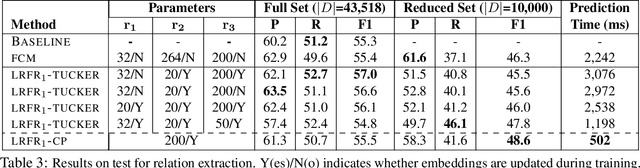
Modern NLP models rely heavily on engineered features, which often combine word and contextual information into complex lexical features. Such combination results in large numbers of features, which can lead to over-fitting. We present a new model that represents complex lexical features---comprised of parts for words, contextual information and labels---in a tensor that captures conjunction information among these parts. We apply low-rank tensor approximations to the corresponding parameter tensors to reduce the parameter space and improve prediction speed. Furthermore, we investigate two methods for handling features that include $n$-grams of mixed lengths. Our model achieves state-of-the-art results on tasks in relation extraction, PP-attachment, and preposition disambiguation.