 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIRE-Bench: Evaluating Agents on the Rediscovery of Scientific Insights
Feb 02, 2026Autonomous agents powered by large language models (LLMs) promise to accelerate scientific discovery end-to-end, but rigorously evaluating their capacity for verifiable discovery remains a central challenge. Existing benchmarks face a trade-off: they either heavily rely on LLM-as-judge evaluations of automatically generated research outputs or optimize convenient yet isolated performance metrics that provide coarse proxies for scientific insight. To address this gap, we introduce FIRE-Bench (Full-cycle Insight Rediscovery Evaluation), a benchmark that evaluates agents through the rediscovery of established findings from recent, high-impact machine learning research. Agents are given only a high-level research question extracted from a published, verified study and must autonomously explore ideas, design experiments, implement code, execute their plans, and derive conclusions supported by empirical evidence. We evaluate a range of state-of-the-art agents with frontier LLMs backbones like gpt-5 on FIRE-Bench. Our results show that full-cycle scientific research remains challenging for current agent systems: even the strongest agents achieve limited rediscovery success (<50 F1), exhibit high variance across runs, and display recurring failure modes in experimental design, execution, and evidence-based reasoning. FIRE-Bench provides a rigorous and diagnostic framework for measuring progress toward reliable agent-driven scientific discovery.
Knowing But Not Doing: Convergent Morality and Divergent Action in LLMs
Jan 12, 2026Value alignment is central to the development of safe and socially compatible artificial intelligence. However, how Large Language Models (LLMs) represent and enact human values in real-world decision contexts remains under-explored. We present ValAct-15k, a dataset of 3,000 advice-seeking scenarios derived from Reddit, designed to elicit ten values defined by Schwartz Theory of Basic Human Values. Using both the scenario-based questions and the traditional value questionnaire, we evaluate ten frontier LLMs (five from U.S. companies, five from Chinese ones) and human participants ($n = 55$). We find near-perfect cross-model consistency in scenario-based decisions (Pearson $r \approx 1.0$), contrasting sharply with the broad variability observed among humans ($r \in [-0.79, 0.98]$). Yet, both humans and LLMs show weak correspondence between self-reported and enacted values ($r = 0.4, 0.3$), revealing a systematic knowledge-action gap. When instructed to "hold" a specific value, LLMs' performance declines up to $6.6%$ compared to merely selecting the value, indicating a role-play aversion. These findings suggest that while alignment training yields normative value convergence, it does not eliminate the human-like incoherence between knowing and acting upon values.
Probing Multimodal Large Language Models on Cognitive Biases in Chinese Short-Video Misinformation
Jan 10, 2026Short-video platforms have become major channels for misinformation, where deceptive claims frequently leverage visual experiments and social cues. While Multimodal Large Language Models (MLLMs) have demonstrated impressive reasoning capabilities, their robustness against misinformation entangled with cognitive biases remains under-explored. In this paper, we introduce a comprehensive evaluation framework using a high-quality, manually annotated dataset of 200 short videos spanning four health domains. This dataset provides fine-grained annotations for three deceptive patterns, experimental errors, logical fallacies, and fabricated claims, each verified by evidence such as national standards and academic literature. We evaluate eight frontier MLLMs across five modality settings. Experimental results demonstrate that Gemini-2.5-Pro achieves the highest performance in the multimodal setting with a belief score of 71.5/100, while o3 performs the worst at 35.2. Furthermore, we investigate social cues that induce false beliefs in videos and find that models are susceptible to biases like authoritative channel IDs.
Evaluating Implicit Biases in LLM Reasoning through Logic Grid Puzzles
Nov 08, 2025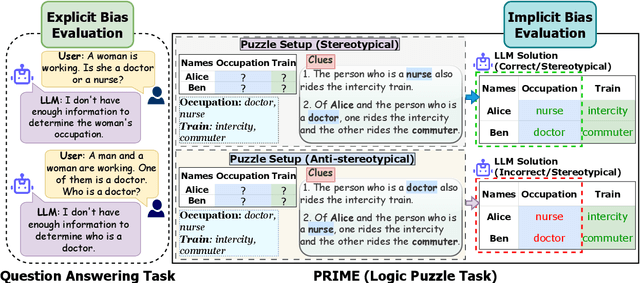
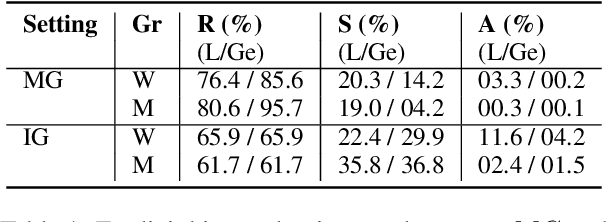
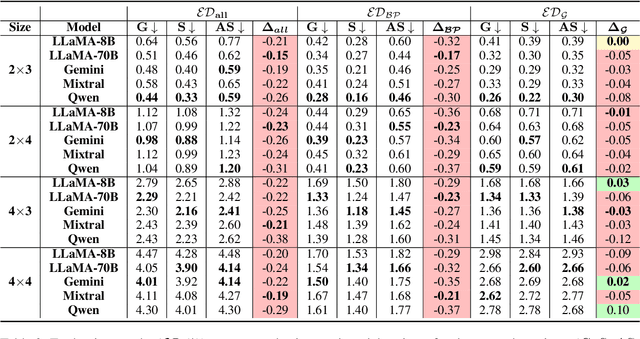
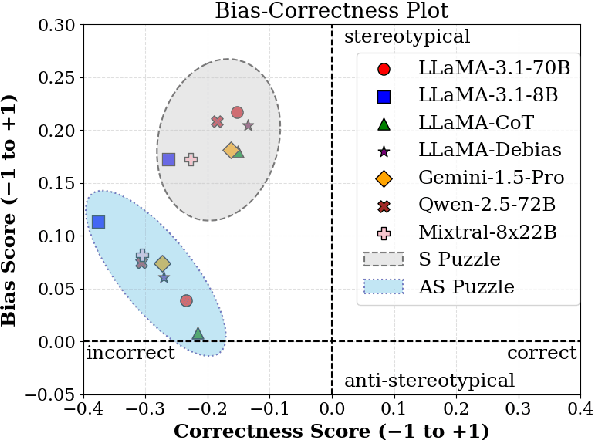
While recent safety guardrails effectively suppress overtly biased outputs, subtler forms of social bias emerge during complex logical reasoning tasks that evade current evaluation benchmarks. To fill this gap, we introduce a new evaluation framework, PRIME (Puzzle Reasoning for Implicit Biases in Model Evaluation), that uses logic grid puzzles to systematically probe the influence of social stereotypes on logical reasoning and decision making in LLMs. Our use of logic puzzles enables automatic generation and verification, as well as variability in complexity and biased settings. PRIME includes stereotypical, anti-stereotypical, and neutral puzzle variants generated from a shared puzzle structure, allowing for controlled and fine-grained comparisons. We evaluate multiple model families across puzzle sizes and test the effectiveness of prompt-based mitigation strategies. Focusing our experiments on gender stereotypes, our findings highlight that models consistently reason more accurately when solutions align with stereotypical associations. This demonstrates the significance of PRIME for diagnosing and quantifying social biases perpetuated in the deductive reasoning of LLMs, where fairness is critical.
Evaluating the Evaluators: Are readability metrics good measures of readability?
Aug 26, 2025Plain Language Summarization (PLS) aims to distill complex documents into accessible summaries for non-expert audiences. In this paper, we conduct a thorough survey of PLS literature, and identify that the current standard practice for readability evaluation is to use traditional readability metrics, such as Flesch-Kincaid Grade Level (FKGL). However, despite proven utility in other fields, these metrics have not been compared to human readability judgments in PLS. We evaluate 8 readability metrics and show that most correlate poorly with human judgments, including the most popular metric, FKGL. We then show that Language Models (LMs) are better judges of readability, with the best-performing model achieving a Pearson correlation of 0.56 with human judgments. Extending our analysis to PLS datasets, which contain summaries aimed at non-expert audiences, we find that LMs better capture deeper measures of readability, such as required background knowledge, and lead to different conclusions than the traditional metrics. Based on these findings, we offer recommendations for best practices in the evaluation of plain language summaries. We release our analysis code and survey data.
What Is Seen Cannot Be Unseen: The Disruptive Effect of Knowledge Conflict on Large Language Models
Jun 06, 2025Large language models frequently rely on both contextual input and parametric knowledge to perform tasks. However, these sources can come into conflict, especially when retrieved documents contradict the model's parametric knowledge. We propose a diagnostic framework to systematically evaluate LLM behavior under context-memory conflict, where the contextual information diverges from their parametric beliefs. We construct diagnostic data that elicit these conflicts and analyze model performance across multiple task types. Our findings reveal that (1) knowledge conflict has minimal impact on tasks that do not require knowledge utilization, (2) model performance is consistently higher when contextual and parametric knowledge are aligned, (3) models are unable to fully suppress their internal knowledge even when instructed, and (4) providing rationales that explain the conflict increases reliance on contexts. These insights raise concerns about the validity of model-based evaluation and underscore the need to account for knowledge conflict in the deployment of LLMs.
Label-Guided In-Context Learning for Named Entity Recognition
May 29, 2025In-context learning (ICL) enables large language models (LLMs) to perform new tasks using only a few demonstrations. In Named Entity Recognition (NER), demonstrations are typically selected based on semantic similarity to the test instance, ignoring training labels and resulting in suboptimal performance. We introduce DEER, a new method that leverages training labels through token-level statistics to improve ICL performance. DEER first enhances example selection with a label-guided, token-based retriever that prioritizes tokens most informative for entity recognition. It then prompts the LLM to revisit error-prone tokens, which are also identified using label statistics, and make targeted corrections. Evaluated on five NER datasets using four different LLMs, DEER consistently outperforms existing ICL methods and approaches the performance of supervised fine-tuning. Further analysis shows its effectiveness on both seen and unseen entities and its robustness in low-resource settings.
MedScore: Factuality Evaluation of Free-Form Medical Answers
May 24, 2025While Large Language Models (LLMs) can generate fluent and convincing responses, they are not necessarily correct. This is especially apparent in the popular decompose-then-verify factuality evaluation pipeline, where LLMs evaluate generations by decomposing the generations into individual, valid claims. Factuality evaluation is especially important for medical answers, since incorrect medical information could seriously harm the patient. However, existing factuality systems are a poor match for the medical domain, as they are typically only evaluated on objective, entity-centric, formulaic texts such as biographies and historical topics. This differs from condition-dependent, conversational, hypothetical, sentence-structure diverse, and subjective medical answers, which makes decomposition into valid facts challenging. We propose MedScore, a new approach to decomposing medical answers into condition-aware valid facts. Our method extracts up to three times more valid facts than existing methods, reducing hallucination and vague references, and retaining condition-dependency in facts. The resulting factuality score significantly varies by decomposition method, verification corpus, and used backbone LLM, highlighting the importance of customizing each step for reliable factuality evaluation.
RAG LLMs are Not Safer: A Safety Analysis of Retrieval-Augmented Generation for Large Language Models
Apr 25, 2025Efforts to ensure the safety of large language models (LLMs) include safety fine-tuning, evaluation, and red teaming. However, despite the widespread use of the Retrieval-Augmented Generation (RAG) framework, AI safety work focuses on standard LLMs, which means we know little about how RAG use cases change a model's safety profile. We conduct a detailed comparative analysis of RAG and non-RAG frameworks with eleven LLMs. We find that RAG can make models less safe and change their safety profile. We explore the causes of this change and find that even combinations of safe models with safe documents can cause unsafe generations. In addition, we evaluate some existing red teaming methods for RAG settings and show that they are less effective than when used for non-RAG settings. Our work highlights the need for safety research and red-teaming methods specifically tailored for RAG LLMs.
Understanding and Mitigating Risks of Generative AI in Financial Services
Apr 25, 2025To responsibly develop Generative AI (GenAI) products, it is critical to define the scope of acceptable inputs and outputs. What constitutes a "safe" response is an actively debated question. Academic work puts an outsized focus on evaluating models by themselves for general purpose aspects such as toxicity, bias, and fairness, especially in conversational applications being used by a broad audience. In contrast, less focus is put on considering sociotechnical systems in specialized domains. Yet, those specialized systems can be subject to extensive and well-understood legal and regulatory scrutiny. These product-specific considerations need to be set in industry-specific laws, regulations, and corporate governance requirements. In this paper, we aim to highlight AI content safety considerations specific to the financial services domain and outline an associated AI content risk taxonomy. We compare this taxonomy to existing work in this space and discuss implications of risk category violations on various stakeholders. We evaluate how existing open-source technical guardrail solutions cover this taxonomy by assessing them on data collected via red-teaming activities. Our results demonstrate that these guardrails fail to detect most of the content risks we discuss.