 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Mitigating Risks of Generative AI in Financial Services
Apr 25, 2025To responsibly develop Generative AI (GenAI) products, it is critical to define the scope of acceptable inputs and outputs. What constitutes a "safe" response is an actively debated question. Academic work puts an outsized focus on evaluating models by themselves for general purpose aspects such as toxicity, bias, and fairness, especially in conversational applications being used by a broad audience. In contrast, less focus is put on considering sociotechnical systems in specialized domains. Yet, those specialized systems can be subject to extensive and well-understood legal and regulatory scrutiny. These product-specific considerations need to be set in industry-specific laws, regulations, and corporate governance requirements. In this paper, we aim to highlight AI content safety considerations specific to the financial services domain and outline an associated AI content risk taxonomy. We compare this taxonomy to existing work in this space and discuss implications of risk category violations on various stakeholders. We evaluate how existing open-source technical guardrail solutions cover this taxonomy by assessing them on data collected via red-teaming activities. Our results demonstrate that these guardrails fail to detect most of the content risks we discuss.
Pushing the Limits of Cross-Embodiment Learning for Manipulation and Navigation
Feb 29, 2024



Recent years in robotics and imitation learning have shown remarkable progress in training large-scale foundation models by leveraging data across a multitude of embodiments. The success of such policies might lead us to wonder: just how diverse can the robots in the training set be while still facilitating positive transfer? In this work, we study this question in the context of heterogeneous embodiments, examining how even seemingly very different domains, such as robotic navigation and manipulation, can provide benefits when included in the training data for the same model. We train a single goal-conditioned policy that is capable of controlling robotic arms, quadcopters, quadrupeds, and mobile bases. We then investigate the extent to which transfer can occur across navigation and manipulation on these embodiments by framing them as a single goal-reaching task. We find that co-training with navigation data can enhance robustness and performance in goal-conditioned manipulation with a wrist-mounted camera. We then deploy our policy trained only from navigation-only and static manipulation-only data on a mobile manipulator, showing that it can control a novel embodiment in a zero-shot manner. These results provide evidence that large-scale robotic policies can benefit from data collected across various embodiments. Further information and robot videos can be found on our project website http://extreme-cross-embodiment.github.io.
FastRLAP: A System for Learning High-Speed Driving via Deep RL and Autonomous Practicing
Apr 19, 2023
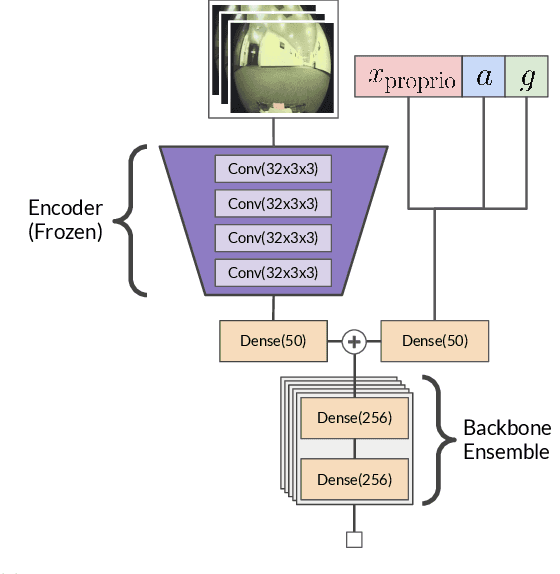
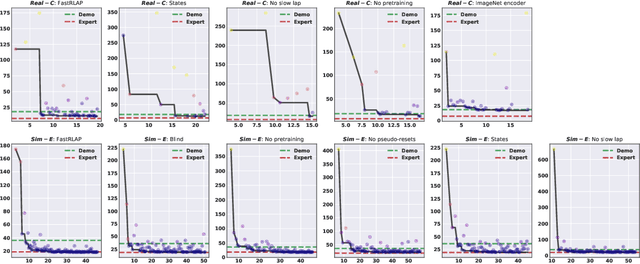

We present a system that enables an autonomous small-scale RC car to drive aggressively from visual observations using reinforcement learning (RL). Our system, FastRLAP (faster lap), trains autonomously in the real world, without human interventions, and without requiring any simulation or expert demonstrations. Our system integrates a number of important components to make this possible: we initialize the representations for the RL policy and value function from a large prior dataset of other robots navigating in other environments (at low speed), which provides a navigation-relevant representation. From here, a sample-efficient online RL method uses a single low-speed user-provided demonstration to determine the desired driving course, extracts a set of navigational checkpoints, and autonomously practices driving through these checkpoints, resetting automatically on collision or failure. Perhaps surprisingly, we find that with appropriate initialization and choice of algorithm, our system can learn to drive over a variety of racing courses with less than 20 minutes of online training. The resulting policies exhibit emergent aggressive driving skills, such as timing braking and acceleration around turns and avoiding areas which impede the robot's motion, approaching the performance of a human driver using a similar first-person interface over the course of training.
Offline Reinforcement Learning for Visual Navigation
Dec 16, 2022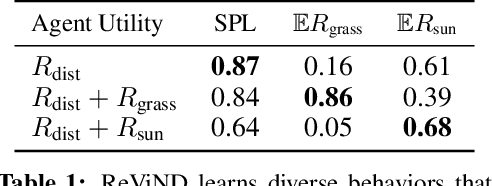
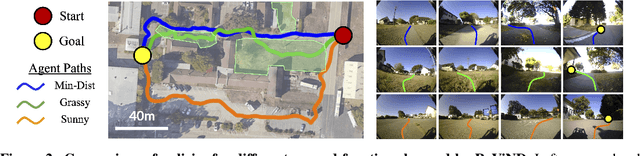
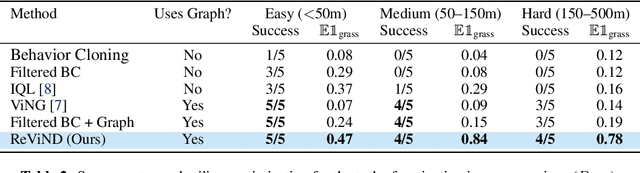
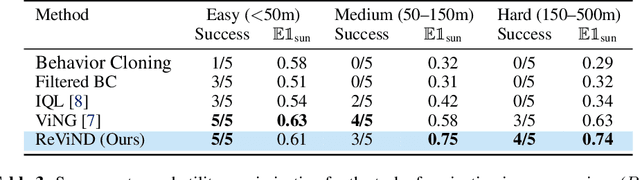
Reinforcement learning can enable robots to navigate to distant goals while optimizing user-specified reward functions, including preferences for following lanes, staying on paved paths, or avoiding freshly mowed grass. However, online learning from trial-and-error for real-world robots is logistically challenging, and methods that instead can utilize existing datasets of robotic navigation data could be significantly more scalable and enable broader generalization. In this paper, we present ReViND, the first offline RL system for robotic navigation that can leverage previously collected data to optimize user-specified reward functions in the real-world. We evaluate our system for off-road navigation without any additional data collection or fine-tuning, and show that it can navigate to distant goals using only offline training from this dataset, and exhibit behaviors that qualitatively differ based on the user-specified reward function.
GNM: A General Navigation Model to Drive Any Robot
Oct 07, 2022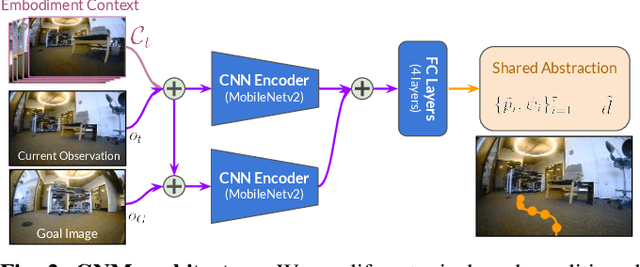

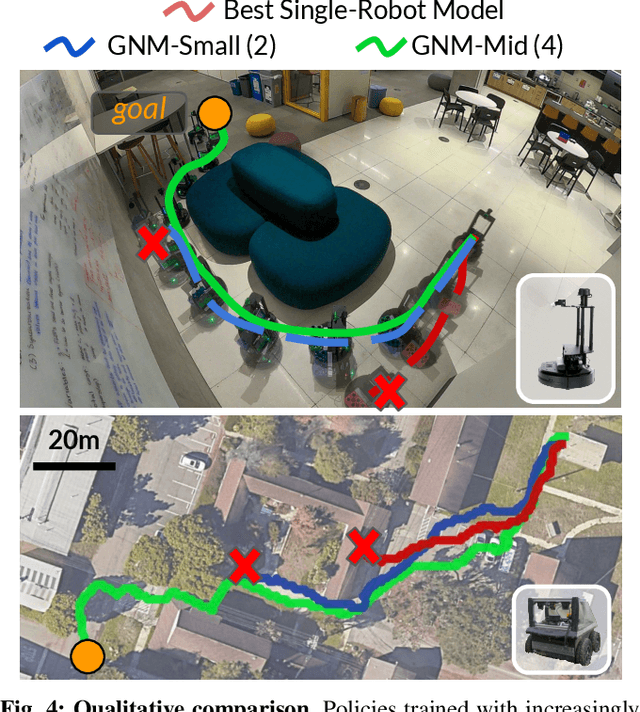
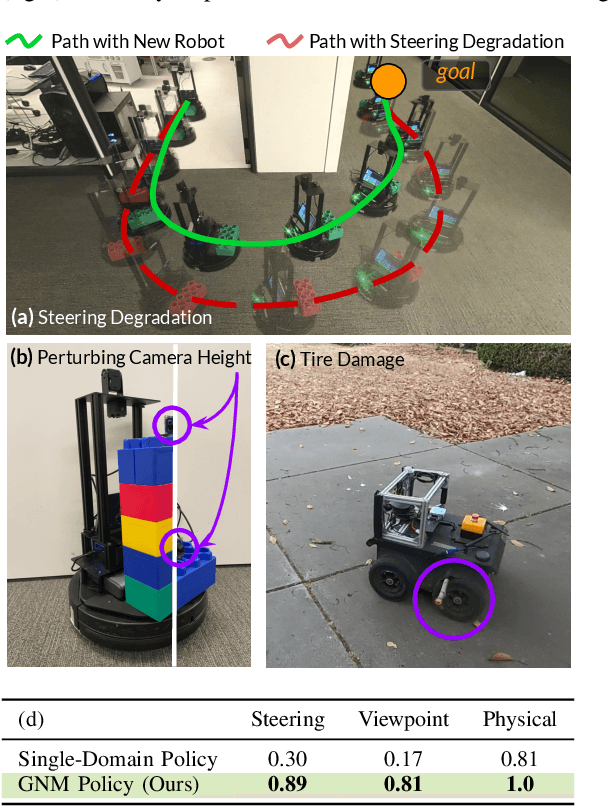
Learning provides a powerful tool for vision-based navigation, but the capabilities of learning-based policies are constrained by limited training data. If we could combine data from all available sources, including multiple kinds of robots, we could train more powerful navigation models. In this paper, we study how a general goal-conditioned model for vision-based navigation can be trained on data obtained from many distinct but structurally similar robots, and enable broad generalization across environments and embodiments. We analyze the necessary design decisions for effective data sharing across robots, including the use of temporal context and standardized action spaces, and demonstrate that an omnipolicy trained from heterogeneous datasets outperforms policies trained on any single dataset. We curate 60 hours of navigation trajectories from 6 distinct robots, and deploy the trained GNM on a range of new robots, including an underactuated quadrotor. We find that training on diverse data leads to robustness against degradation in sensing and actuation. Using a pre-trained navigation model with broad generalization capabilities can bootstrap applications on novel robots going forward, and we hope that the GNM represents a step in that direction. For more information on the datasets, code, and videos, please check out http://sites.google.com/view/drive-any-robot.