 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Perception and Action: Spatially-Grounded Mid-Level Representations for Robot Generalization
Jun 06, 2025In this work, we investigate how spatially grounded auxiliary representations can provide both broad, high-level grounding as well as direct, actionable information to improve policy learning performance and generalization for dexterous tasks. We study these mid-level representations across three critical dimensions: object-centricity, pose-awareness, and depth-awareness. We use these interpretable mid-level representations to train specialist encoders via supervised learning, then feed them as inputs to a diffusion policy to solve dexterous bimanual manipulation tasks in the real world. We propose a novel mixture-of-experts policy architecture that combines multiple specialized expert models, each trained on a distinct mid-level representation, to improve policy generalization. This method achieves an average success rate that is 11% higher than a language-grounded baseline and 24 percent higher than a standard diffusion policy baseline on our evaluation tasks. Furthermore, we find that leveraging mid-level representations as supervision signals for policy actions within a weighted imitation learning algorithm improves the precision with which the policy follows these representations, yielding an additional performance increase of 10%. Our findings highlight the importance of grounding robot policies not only with broad perceptual tasks but also with more granular, actionable representations. For further information and videos, please visit https://mid-level-moe.github.io.
Pushing the Limits of Cross-Embodiment Learning for Manipulation and Navigation
Feb 29, 2024



Recent years in robotics and imitation learning have shown remarkable progress in training large-scale foundation models by leveraging data across a multitude of embodiments. The success of such policies might lead us to wonder: just how diverse can the robots in the training set be while still facilitating positive transfer? In this work, we study this question in the context of heterogeneous embodiments, examining how even seemingly very different domains, such as robotic navigation and manipulation, can provide benefits when included in the training data for the same model. We train a single goal-conditioned policy that is capable of controlling robotic arms, quadcopters, quadrupeds, and mobile bases. We then investigate the extent to which transfer can occur across navigation and manipulation on these embodiments by framing them as a single goal-reaching task. We find that co-training with navigation data can enhance robustness and performance in goal-conditioned manipulation with a wrist-mounted camera. We then deploy our policy trained only from navigation-only and static manipulation-only data on a mobile manipulator, showing that it can control a novel embodiment in a zero-shot manner. These results provide evidence that large-scale robotic policies can benefit from data collected across various embodiments. Further information and robot videos can be found on our project website http://extreme-cross-embodiment.github.io.
Browsing behavior exposes identities on the Web
Dec 24, 2023
How easy is it to uniquely identify a person based on their web browsing behavior? Here we show that when people navigate the Web, their online traces produce fingerprints that identify them. By merely knowing their most visited web domains, four data points are enough to identify 95% of the individuals. These digital fingerprints are stable and render high re-identifiability. We demonstrate that we can re-identify 90% of the individuals in separate time slices of data. Such a privacy threat persists even with limited information about individuals' browsing behavior, reinforcing existing concerns around online privacy.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Analysis of Weather and Time Features in Machine Learning-aided ERCOT Load Forecasting
Oct 13, 2023
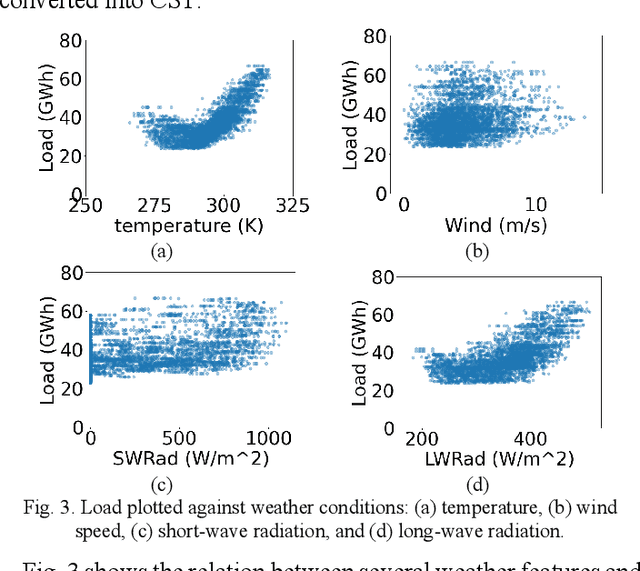
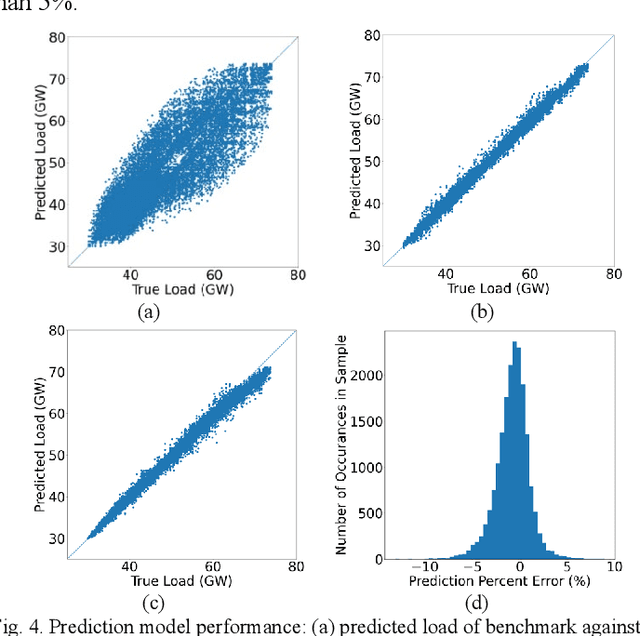

Accurate load forecasting is critical for efficient and reliable operations of the electric power system. A large part of electricity consumption is affected by weather conditions, making weather information an important determinant of electricity usage. Personal appliances and industry equipment also contribute significantly to electricity demand with temporal patterns, making time a useful factor to consider in load forecasting. This work develops several machine learning (ML) models that take various time and weather information as part of the input features to predict the short-term system-wide total load. Ablation studies were also performed to investigate and compare the impacts of different weather factors on the prediction accuracy. Actual load and historical weather data for the same region were processed and then used to train the ML models. It is interesting to observe that using all available features, each of which may be correlated to the load, is unlikely to achieve the best forecasting performance; features with redundancy may even decrease the inference capabilities of ML models. This indicates the importance of feature selection for ML models. Overall, case studies demonstrated the effectiveness of ML models trained with different weather and time input features for ERCOT load forecasting.
Polybot: Training One Policy Across Robots While Embracing Variability
Jul 07, 2023



Reusing large datasets is crucial to scale vision-based robotic manipulators to everyday scenarios due to the high cost of collecting robotic datasets. However, robotic platforms possess varying control schemes, camera viewpoints, kinematic configurations, and end-effector morphologies, posing significant challenges when transferring manipulation skills from one platform to another. To tackle this problem, we propose a set of key design decisions to train a single policy for deployment on multiple robotic platforms. Our framework first aligns the observation and action spaces of our policy across embodiments via utilizing wrist cameras and a unified, but modular codebase. To bridge the remaining domain shift, we align our policy's internal representations across embodiments through contrastive learning. We evaluate our method on a dataset collected over 60 hours spanning 6 tasks and 3 robots with varying joint configurations and sizes: the WidowX 250S, the Franka Emika Panda, and the Sawyer. Our results demonstrate significant improvements in success rate and sample efficiency for our policy when using new task data collected on a different robot, validating our proposed design decisions. More details and videos can be found on our anonymized project website: https://sites.google.com/view/polybot-multirobot
Don't Start From Scratch: Leveraging Prior Data to Automate Robotic Reinforcement Learning
Jul 17, 2022


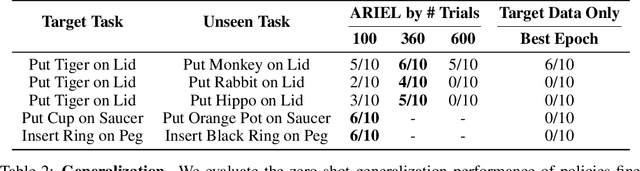
Reinforcement learning (RL) algorithms hold the promise of enabling autonomous skill acquisition for robotic systems. However, in practice, real-world robotic RL typically requires time consuming data collection and frequent human intervention to reset the environment. Moreover, robotic policies learned with RL often fail when deployed beyond the carefully controlled setting in which they were learned. In this work, we study how these challenges can all be tackled by effective utilization of diverse offline datasets collected from previously seen tasks. When faced with a new task, our system adapts previously learned skills to quickly learn to both perform the new task and return the environment to an initial state, effectively performing its own environment reset. Our empirical results demonstrate that incorporating prior data into robotic reinforcement learning enables autonomous learning, substantially improves sample-efficiency of learning, and enables better generalization. Project website: https://sites.google.com/view/ariel-berkeley/
COG: Connecting New Skills to Past Experience with Offline Reinforcement Learning
Oct 27, 2020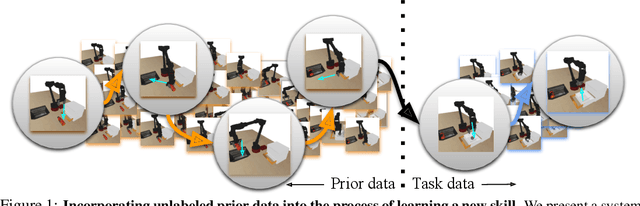
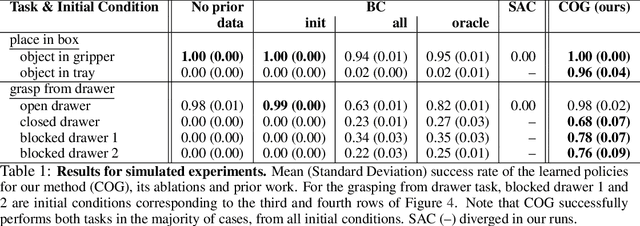
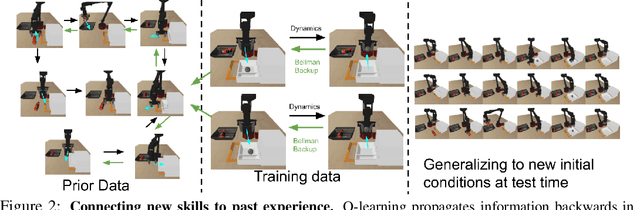

Reinforcement learning has been applied to a wide variety of robotics problems, but most of such applications involve collecting data from scratch for each new task. Since the amount of robot data we can collect for any single task is limited by time and cost considerations, the learned behavior is typically narrow: the policy can only execute the task in a handful of scenarios that it was trained on. What if there was a way to incorporate a large amount of prior data, either from previously solved tasks or from unsupervised or undirected environment interaction, to extend and generalize learned behaviors? While most prior work on extending robotic skills using pre-collected data focuses on building explicit hierarchies or skill decompositions, we show in this paper that we can reuse prior data to extend new skills simply through dynamic programming. We show that even when the prior data does not actually succeed at solving the new task, it can still be utilized for learning a better policy, by providing the agent with a broader understanding of the mechanics of its environment. We demonstrate the effectiveness of our approach by chaining together several behaviors seen in prior datasets for solving a new task, with our hardest experimental setting involving composing four robotic skills in a row: picking, placing, drawer opening, and grasping, where a +1/0 sparse reward is provided only on task completion. We train our policies in an end-to-end fashion, mapping high-dimensional image observations to low-level robot control commands, and present results in both simulated and real world domains. Additional materials and source code can be found on our project website: https://sites.google.com/view/cog-rl