 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrowsing behavior exposes identities on the Web
Dec 24, 2023
How easy is it to uniquely identify a person based on their web browsing behavior? Here we show that when people navigate the Web, their online traces produce fingerprints that identify them. By merely knowing their most visited web domains, four data points are enough to identify 95% of the individuals. These digital fingerprints are stable and render high re-identifiability. We demonstrate that we can re-identify 90% of the individuals in separate time slices of data. Such a privacy threat persists even with limited information about individuals' browsing behavior, reinforcing existing concerns around online privacy.
Novelty in news search: a longitudinal study of the 2020 US elections
Nov 09, 2022The 2020 US elections news coverage was extensive, with new pieces of information generated rapidly. This evolving scenario presented an opportunity to study the performance of search engines in a context in which they had to quickly process information as it was published. We analyze novelty, a measurement of new items that emerge in the top news search results, to compare the coverage and visibility of different topics. We conduct a longitudinal study of news results of five search engines collected in short-bursts (every 21 minutes) from two regions (Oregon, US and Frankfurt, Germany), starting on election day and lasting until one day after the announcement of Biden as the winner. We find more new items emerging for election related queries ("joe biden", "donald trump" and "us elections") compared to topical (e.g., "coronavirus") or stable (e.g., "holocaust") queries. We demonstrate differences across search engines and regions over time, and we highlight imbalances between candidate queries. When it comes to news search, search engines are responsible for such imbalances, either due to their algorithms or the set of news sources they rely on. We argue that such imbalances affect the visibility of political candidates in news searches during electoral periods.
A Domain-adaptive Pre-training Approach for Language Bias Detection in News
May 22, 2022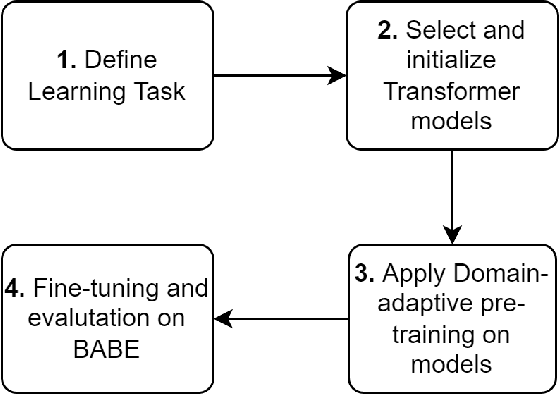

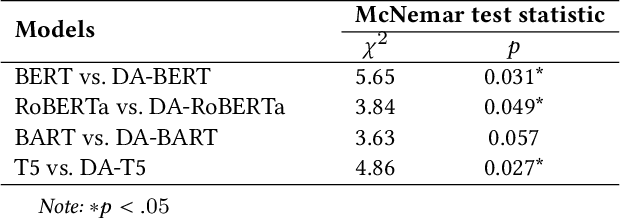
Media bias is a multi-faceted construct influencing individual behavior and collective decision-making. Slanted news reporting is the result of one-sided and polarized writing which can occur in various forms. In this work, we focus on an important form of media bias, i.e. bias by word choice. Detecting biased word choices is a challenging task due to its linguistic complexity and the lack of representative gold-standard corpora. We present DA-RoBERTa, a new state-of-the-art transformer-based model adapted to the media bias domain which identifies sentence-level bias with an F1 score of 0.814. In addition, we also train, DA-BERT and DA-BART, two more transformer models adapted to the bias domain. Our proposed domain-adapted models outperform prior bias detection approaches on the same data.
Where the Earth is flat and 9/11 is an inside job: A comparative algorithm audit of conspiratorial information in web search results
Dec 06, 2021
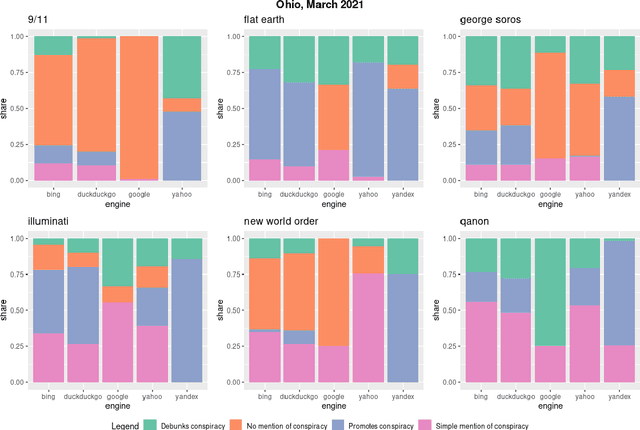


Web search engines are important online information intermediaries that are frequently used and highly trusted by the public despite multiple evidence of their outputs being subjected to inaccuracies and biases. One form of such inaccuracy, which so far received little scholarly attention, is the presence of conspiratorial information, namely pages promoting conspiracy theories. We address this gap by conducting a comparative algorithm audit to examine the distribution of conspiratorial information in search results across five search engines: Google, Bing, DuckDuckGo, Yahoo and Yandex. Using a virtual agent-based infrastructure, we systematically collect search outputs for six conspiracy theory-related queries (flat earth, new world order, qanon, 9/11, illuminati, george soros) across three locations (two in the US and one in the UK) and two observation periods (March and May 2021). We find that all search engines except Google consistently displayed conspiracy-promoting results and returned links to conspiracy-dedicated websites in their top results, although the share of such content varied across queries. Most conspiracy-promoting results came from social media and conspiracy-dedicated websites while conspiracy-debunking information was shared by scientific websites and, to a lesser extent, legacy media. The fact that these observations are consistent across different locations and time periods highlight the possibility of some search engines systematically prioritizing conspiracy-promoting content and, thus, amplifying their distribution in the online environments.