 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoogleTrendArchive: A Year-Long Archive of Real-Time Web Search Trends Worldwide
Mar 23, 2026GoogleTrendArchive is a comprehensive archive of Google Trending Now data spanning over one year (from November 28, 2024 to January 3, 2026) across 125 countries and 1,358 locations. Unlike Google Trends, which requires specifying search terms in advance, Trending Now captures search queries experiencing real-time surges, offering a way to inductively discover trending patterns across regions for studying collective attention dynamics. However, Google does not provide historical access to this data beyond seven days. Our dataset addresses this gap by presenting an archive of Trending Now data. The dataset contains over 7.6 million trend episodes. Each record includes the trend identifier, search volume bucket, precise timestamps, duration, geographic location, and related query clusters. This dataset, among other, enables systematic studies of information diffusion patterns, cross-cultural attention dynamics, crisis responses, and the temporal evolution of collective information-seeking at a global scale. The comprehensive geographic coverage facilitates fine-grained cross-country or cross-regional comparative analyses.
Auditing Google's AI Overviews and Featured Snippets: A Case Study on Baby Care and Pregnancy
Nov 17, 2025Google Search increasingly surfaces AI-generated content through features like AI Overviews (AIO) and Featured Snippets (FS), which users frequently rely on despite having no control over their presentation. Through a systematic algorithm audit of 1,508 real baby care and pregnancy-related queries, we evaluate the quality and consistency of these information displays. Our robust evaluation framework assesses multiple quality dimensions, including answer consistency, relevance, presence of medical safeguards, source categories, and sentiment alignment. Our results reveal concerning gaps in information consistency, with information in AIO and FS displayed on the same search result page being inconsistent with each other in 33% of cases. Despite high relevance scores, both features critically lack medical safeguards (present in just 11% of AIO and 7% of FS responses). While health and wellness websites dominate source categories for both, AIO and FS, FS also often link to commercial sources. These findings have important implications for public health information access and demonstrate the need for stronger quality controls in AI-mediated health information. Our methodology provides a transferable framework for auditing AI systems across high-stakes domains where information quality directly impacts user well-being.
Large Language Model Hacking: Quantifying the Hidden Risks of Using LLMs for Text Annotation
Sep 10, 2025Large language models (LLMs) are rapidly transforming social science research by enabling the automation of labor-intensive tasks like data annotation and text analysis. However, LLM outputs vary significantly depending on the implementation choices made by researchers (e.g., model selection, prompting strategy, or temperature settings). Such variation can introduce systematic biases and random errors, which propagate to downstream analyses and cause Type I, Type II, Type S, or Type M errors. We call this LLM hacking. We quantify the risk of LLM hacking by replicating 37 data annotation tasks from 21 published social science research studies with 18 different models. Analyzing 13 million LLM labels, we test 2,361 realistic hypotheses to measure how plausible researcher choices affect statistical conclusions. We find incorrect conclusions based on LLM-annotated data in approximately one in three hypotheses for state-of-the-art models, and in half the hypotheses for small language models. While our findings show that higher task performance and better general model capabilities reduce LLM hacking risk, even highly accurate models do not completely eliminate it. The risk of LLM hacking decreases as effect sizes increase, indicating the need for more rigorous verification of findings near significance thresholds. Our extensive analysis of LLM hacking mitigation techniques emphasizes the importance of human annotations in reducing false positive findings and improving model selection. Surprisingly, common regression estimator correction techniques are largely ineffective in reducing LLM hacking risk, as they heavily trade off Type I vs. Type II errors. Beyond accidental errors, we find that intentional LLM hacking is unacceptably simple. With few LLMs and just a handful of prompt paraphrases, anything can be presented as statistically significant.
Algorithmically Curated Lies: How Search Engines Handle Misinformation about US Biolabs in Ukraine
Jan 24, 2024



The growing volume of online content prompts the need for adopting algorithmic systems of information curation. These systems range from web search engines to recommender systems and are integral for helping users stay informed about important societal developments. However, unlike journalistic editing the algorithmic information curation systems (AICSs) are known to be subject to different forms of malperformance which make them vulnerable to possible manipulation. The risk of manipulation is particularly prominent in the case when AICSs have to deal with information about false claims that underpin propaganda campaigns of authoritarian regimes. Using as a case study of the Russian disinformation campaign concerning the US biolabs in Ukraine, we investigate how one of the most commonly used forms of AICSs - i.e. web search engines - curate misinformation-related content. For this aim, we conduct virtual agent-based algorithm audits of Google, Bing, and Yandex search outputs in June 2022. Our findings highlight the troubling performance of search engines. Even though some search engines, like Google, were less likely to return misinformation results, across all languages and locations, the three search engines still mentioned or promoted a considerable share of false content (33% on Google; 44% on Bing, and 70% on Yandex). We also find significant disparities in misinformation exposure based on the language of search, with all search engines presenting a higher number of false stories in Russian. Location matters as well with users from Germany being more likely to be exposed to search results promoting false information. These observations stress the possibility of AICSs being vulnerable to manipulation, in particular in the case of the unfolding propaganda campaigns, and underline the importance of monitoring performance of these systems to prevent it.
In Generative AI we Trust: Can Chatbots Effectively Verify Political Information?
Dec 20, 2023



This article presents a comparative analysis of the ability of two large language model (LLM)-based chatbots, ChatGPT and Bing Chat, recently rebranded to Microsoft Copilot, to detect veracity of political information. We use AI auditing methodology to investigate how chatbots evaluate true, false, and borderline statements on five topics: COVID-19, Russian aggression against Ukraine, the Holocaust, climate change, and LGBTQ+ related debates. We compare how the chatbots perform in high- and low-resource languages by using prompts in English, Russian, and Ukrainian. Furthermore, we explore the ability of chatbots to evaluate statements according to political communication concepts of disinformation, misinformation, and conspiracy theory, using definition-oriented prompts. We also systematically test how such evaluations are influenced by source bias which we model by attributing specific claims to various political and social actors. The results show high performance of ChatGPT for the baseline veracity evaluation task, with 72 percent of the cases evaluated correctly on average across languages without pre-training. Bing Chat performed worse with a 67 percent accuracy. We observe significant disparities in how chatbots evaluate prompts in high- and low-resource languages and how they adapt their evaluations to political communication concepts with ChatGPT providing more nuanced outputs than Bing Chat. Finally, we find that for some veracity detection-related tasks, the performance of chatbots varied depending on the topic of the statement or the source to which it is attributed. These findings highlight the potential of LLM-based chatbots in tackling different forms of false information in online environments, but also points to the substantial variation in terms of how such potential is realized due to specific factors, such as language of the prompt or the topic.
Novelty in news search: a longitudinal study of the 2020 US elections
Nov 09, 2022The 2020 US elections news coverage was extensive, with new pieces of information generated rapidly. This evolving scenario presented an opportunity to study the performance of search engines in a context in which they had to quickly process information as it was published. We analyze novelty, a measurement of new items that emerge in the top news search results, to compare the coverage and visibility of different topics. We conduct a longitudinal study of news results of five search engines collected in short-bursts (every 21 minutes) from two regions (Oregon, US and Frankfurt, Germany), starting on election day and lasting until one day after the announcement of Biden as the winner. We find more new items emerging for election related queries ("joe biden", "donald trump" and "us elections") compared to topical (e.g., "coronavirus") or stable (e.g., "holocaust") queries. We demonstrate differences across search engines and regions over time, and we highlight imbalances between candidate queries. When it comes to news search, search engines are responsible for such imbalances, either due to their algorithms or the set of news sources they rely on. We argue that such imbalances affect the visibility of political candidates in news searches during electoral periods.
This is what a pandemic looks like: Visual framing of COVID-19 on search engines
Sep 22, 2022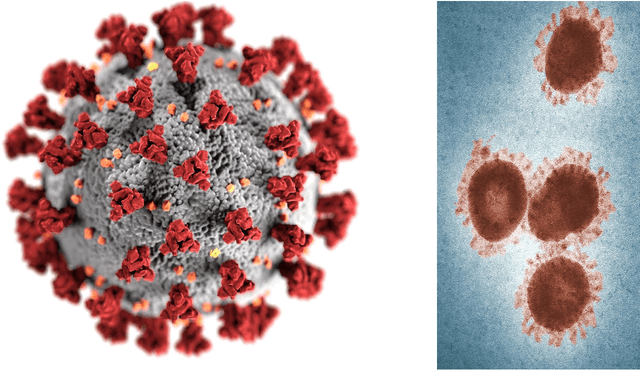
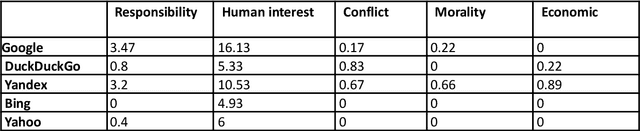
In today's high-choice media environment, search engines play an integral role in informing individuals and societies about the latest events. The importance of search algorithms is even higher at the time of crisis, when users search for information to understand the causes and the consequences of the current situation and decide on their course of action. In our paper, we conduct a comparative audit of how different search engines prioritize visual information related to COVID-19 and what consequences it has for the representation of the pandemic. Using a virtual agent-based audit approach, we examine image search results for the term "coronavirus" in English, Russian and Chinese on five major search engines: Google, Yandex, Bing, Yahoo, and DuckDuckGo. Specifically, we focus on how image search results relate to generic news frames (e.g., the attribution of responsibility, human interest, and economics) used in relation to COVID-19 and how their visual composition varies between the search engines.
Panning for gold: Lessons learned from the platform-agnostic automated detection of political content in textual data
Jul 01, 2022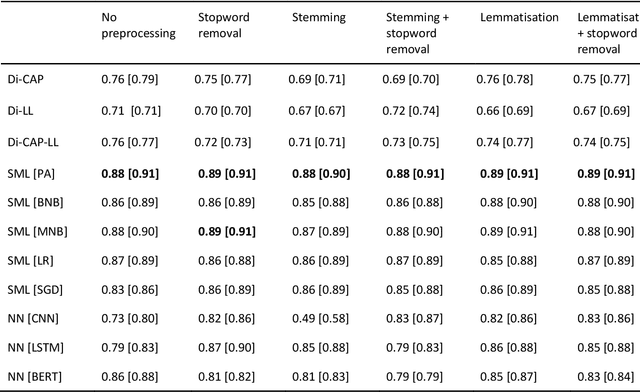
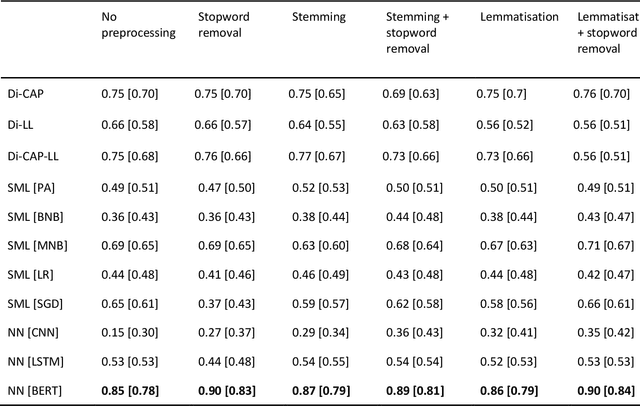
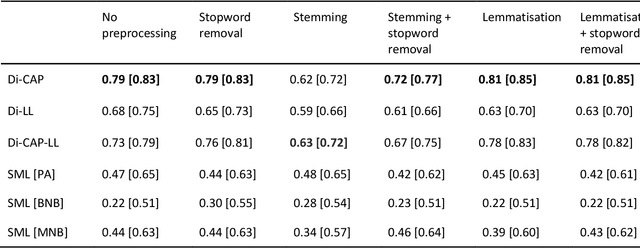
The growing availability of data about online information behaviour enables new possibilities for political communication research. However, the volume and variety of these data makes them difficult to analyse and prompts the need for developing automated content approaches relying on a broad range of natural language processing techniques (e.g. machine learning- or neural network-based ones). In this paper, we discuss how these techniques can be used to detect political content across different platforms. Using three validation datasets, which include a variety of political and non-political textual documents from online platforms, we systematically compare the performance of three groups of detection techniques relying on dictionaries, supervised machine learning, or neural networks. We also examine the impact of different modes of data preprocessing (e.g. stemming and stopword removal) on the low-cost implementations of these techniques using a large set (n = 66) of detection models. Our results show the limited impact of preprocessing on model performance, with the best results for less noisy data being achieved by neural network- and machine-learning-based models, in contrast to the more robust performance of dictionary-based models on noisy data.
Where the Earth is flat and 9/11 is an inside job: A comparative algorithm audit of conspiratorial information in web search results
Dec 06, 2021
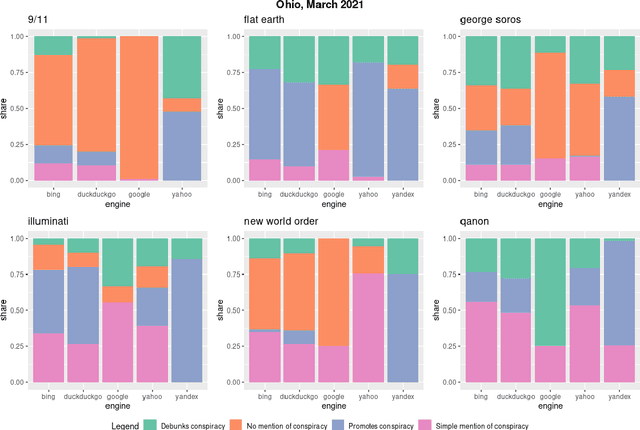


Web search engines are important online information intermediaries that are frequently used and highly trusted by the public despite multiple evidence of their outputs being subjected to inaccuracies and biases. One form of such inaccuracy, which so far received little scholarly attention, is the presence of conspiratorial information, namely pages promoting conspiracy theories. We address this gap by conducting a comparative algorithm audit to examine the distribution of conspiratorial information in search results across five search engines: Google, Bing, DuckDuckGo, Yahoo and Yandex. Using a virtual agent-based infrastructure, we systematically collect search outputs for six conspiracy theory-related queries (flat earth, new world order, qanon, 9/11, illuminati, george soros) across three locations (two in the US and one in the UK) and two observation periods (March and May 2021). We find that all search engines except Google consistently displayed conspiracy-promoting results and returned links to conspiracy-dedicated websites in their top results, although the share of such content varied across queries. Most conspiracy-promoting results came from social media and conspiracy-dedicated websites while conspiracy-debunking information was shared by scientific websites and, to a lesser extent, legacy media. The fact that these observations are consistent across different locations and time periods highlight the possibility of some search engines systematically prioritizing conspiracy-promoting content and, thus, amplifying their distribution in the online environments.
Detecting race and gender bias in visual representation of AI on web search engines
Jun 26, 2021
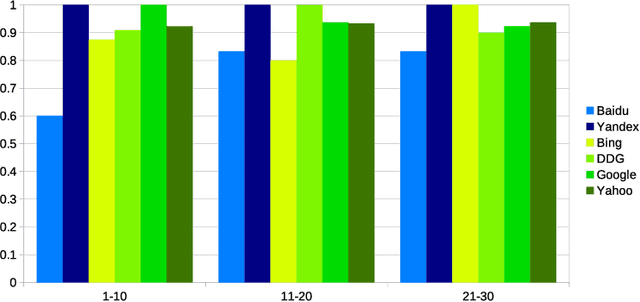
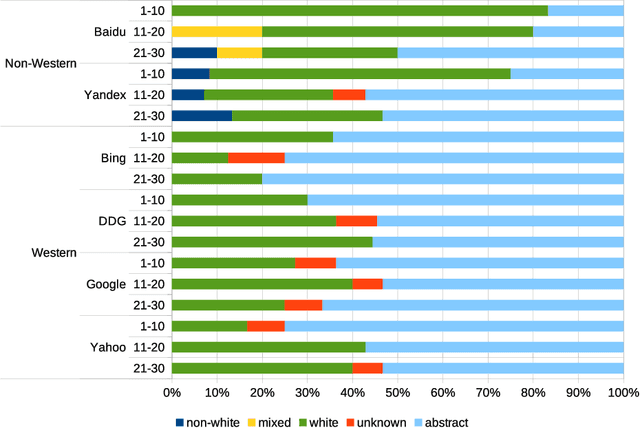
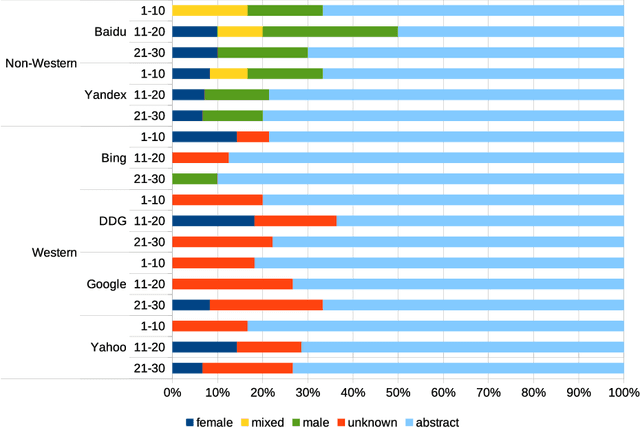
Web search engines influence perception of social reality by filtering and ranking information. However, their outputs are often subjected to bias that can lead to skewed representation of subjects such as professional occupations or gender. In our paper, we use a mixed-method approach to investigate presence of race and gender bias in representation of artificial intelligence (AI) in image search results coming from six different search engines. Our findings show that search engines prioritize anthropomorphic images of AI that portray it as white, whereas non-white images of AI are present only in non-Western search engines. By contrast, gender representation of AI is more diverse and less skewed towards a specific gender that can be attributed to higher awareness about gender bias in search outputs. Our observations indicate both the the need and the possibility for addressing bias in representation of societally relevant subjects, such as technological innovation, and emphasize the importance of designing new approaches for detecting bias in information retrieval systems.
* 16 pages, 3 figures