 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom prosthetic memory to prosthetic denial: Auditing whether large language models are prone to mass atrocity denialism
May 27, 2025The proliferation of large language models (LLMs) can influence how historical narratives are disseminated and perceived. This study explores the implications of LLMs' responses on the representation of mass atrocity memory, examining whether generative AI systems contribute to prosthetic memory, i.e., mediated experiences of historical events, or to what we term "prosthetic denial," the AI-mediated erasure or distortion of atrocity memories. We argue that LLMs function as interfaces that can elicit prosthetic memories and, therefore, act as experiential sites for memory transmission, but also introduce risks of denialism, particularly when their outputs align with contested or revisionist narratives. To empirically assess these risks, we conducted a comparative audit of five LLMs (Claude, GPT, Llama, Mixtral, and Gemini) across four historical case studies: the Holodomor, the Holocaust, the Cambodian Genocide, and the genocide against the Tutsis in Rwanda. Each model was prompted with questions addressing common denialist claims in English and an alternative language relevant to each case (Ukrainian, German, Khmer, and French). Our findings reveal that while LLMs generally produce accurate responses for widely documented events like the Holocaust, significant inconsistencies and susceptibility to denialist framings are observed for more underrepresented cases like the Cambodian Genocide. The disparities highlight the influence of training data availability and the probabilistic nature of LLM responses on memory integrity. We conclude that while LLMs extend the concept of prosthetic memory, their unmoderated use risks reinforcing historical denialism, raising ethical concerns for (digital) memory preservation, and potentially challenging the advantageous role of technology associated with the original values of prosthetic memory.
Tag-Pag: A Dedicated Tool for Systematic Web Page Annotations
Feb 22, 2025
Tag-Pag is an application designed to simplify the categorization of web pages, a task increasingly common for researchers who scrape web pages to analyze individuals' browsing patterns or train machine learning classifiers. Unlike existing tools that focus on annotating sections of text, Tag-Pag systematizes page-level annotations, allowing users to determine whether an entire document relates to one or multiple predefined topics. Tag-Pag offers an intuitive interface to configure the input web pages and annotation labels. It integrates libraries to extract content from the HTML and URL indicators to aid the annotation process. It provides direct access to both scraped and live versions of the web page. Our tool is designed to expedite the annotation process with features like quick navigation, label assignment, and export functionality, making it a versatile and efficient tool for various research applications. Tag-Pag is available at https://github.com/Pantonius/TagPag.
Assessing In-context Learning and Fine-tuning for Topic Classification of German Web Data
Jul 23, 2024Researchers in the political and social sciences often rely on classification models to analyze trends in information consumption by examining browsing histories of millions of webpages. Automated scalable methods are necessary due to the impracticality of manual labeling. In this paper, we model the detection of topic-related content as a binary classification task and compare the accuracy of fine-tuned pre-trained encoder models against in-context learning strategies. Using only a few hundred annotated data points per topic, we detect content related to three German policies in a database of scraped webpages. We compare multilingual and monolingual models, as well as zero and few-shot approaches, and investigate the impact of negative sampling strategies and the combination of URL & content-based features. Our results show that a small sample of annotated data is sufficient to train an effective classifier. Fine-tuning encoder-based models yields better results than in-context learning. Classifiers using both URL & content-based features perform best, while using URLs alone provides adequate results when content is unavailable.
Novelty in news search: a longitudinal study of the 2020 US elections
Nov 09, 2022The 2020 US elections news coverage was extensive, with new pieces of information generated rapidly. This evolving scenario presented an opportunity to study the performance of search engines in a context in which they had to quickly process information as it was published. We analyze novelty, a measurement of new items that emerge in the top news search results, to compare the coverage and visibility of different topics. We conduct a longitudinal study of news results of five search engines collected in short-bursts (every 21 minutes) from two regions (Oregon, US and Frankfurt, Germany), starting on election day and lasting until one day after the announcement of Biden as the winner. We find more new items emerging for election related queries ("joe biden", "donald trump" and "us elections") compared to topical (e.g., "coronavirus") or stable (e.g., "holocaust") queries. We demonstrate differences across search engines and regions over time, and we highlight imbalances between candidate queries. When it comes to news search, search engines are responsible for such imbalances, either due to their algorithms or the set of news sources they rely on. We argue that such imbalances affect the visibility of political candidates in news searches during electoral periods.
This is what a pandemic looks like: Visual framing of COVID-19 on search engines
Sep 22, 2022
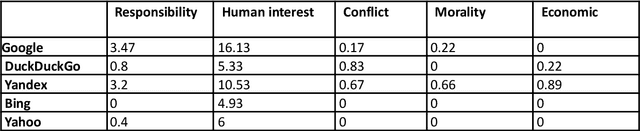
In today's high-choice media environment, search engines play an integral role in informing individuals and societies about the latest events. The importance of search algorithms is even higher at the time of crisis, when users search for information to understand the causes and the consequences of the current situation and decide on their course of action. In our paper, we conduct a comparative audit of how different search engines prioritize visual information related to COVID-19 and what consequences it has for the representation of the pandemic. Using a virtual agent-based audit approach, we examine image search results for the term "coronavirus" in English, Russian and Chinese on five major search engines: Google, Yandex, Bing, Yahoo, and DuckDuckGo. Specifically, we focus on how image search results relate to generic news frames (e.g., the attribution of responsibility, human interest, and economics) used in relation to COVID-19 and how their visual composition varies between the search engines.
Where the Earth is flat and 9/11 is an inside job: A comparative algorithm audit of conspiratorial information in web search results
Dec 06, 2021
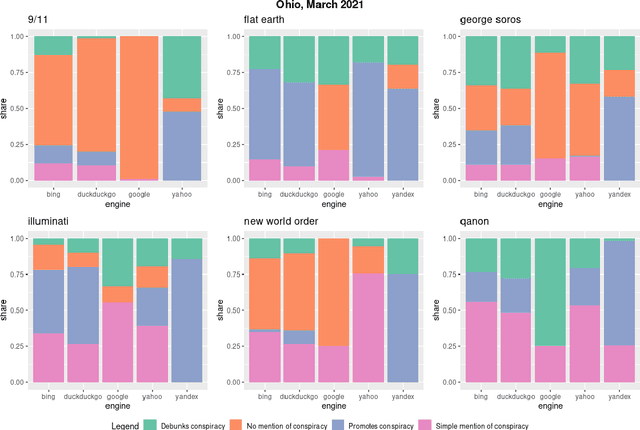


Web search engines are important online information intermediaries that are frequently used and highly trusted by the public despite multiple evidence of their outputs being subjected to inaccuracies and biases. One form of such inaccuracy, which so far received little scholarly attention, is the presence of conspiratorial information, namely pages promoting conspiracy theories. We address this gap by conducting a comparative algorithm audit to examine the distribution of conspiratorial information in search results across five search engines: Google, Bing, DuckDuckGo, Yahoo and Yandex. Using a virtual agent-based infrastructure, we systematically collect search outputs for six conspiracy theory-related queries (flat earth, new world order, qanon, 9/11, illuminati, george soros) across three locations (two in the US and one in the UK) and two observation periods (March and May 2021). We find that all search engines except Google consistently displayed conspiracy-promoting results and returned links to conspiracy-dedicated websites in their top results, although the share of such content varied across queries. Most conspiracy-promoting results came from social media and conspiracy-dedicated websites while conspiracy-debunking information was shared by scientific websites and, to a lesser extent, legacy media. The fact that these observations are consistent across different locations and time periods highlight the possibility of some search engines systematically prioritizing conspiracy-promoting content and, thus, amplifying their distribution in the online environments.
Detecting race and gender bias in visual representation of AI on web search engines
Jun 26, 2021
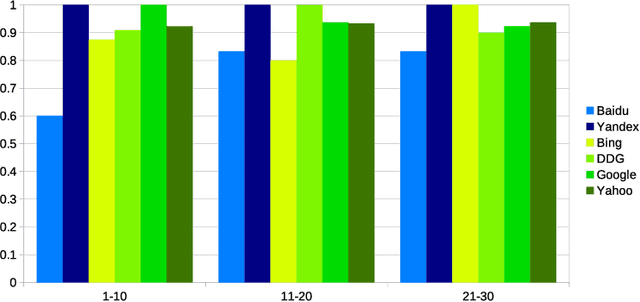
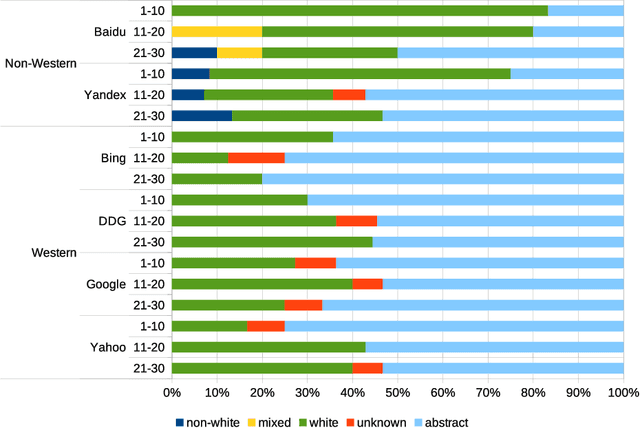
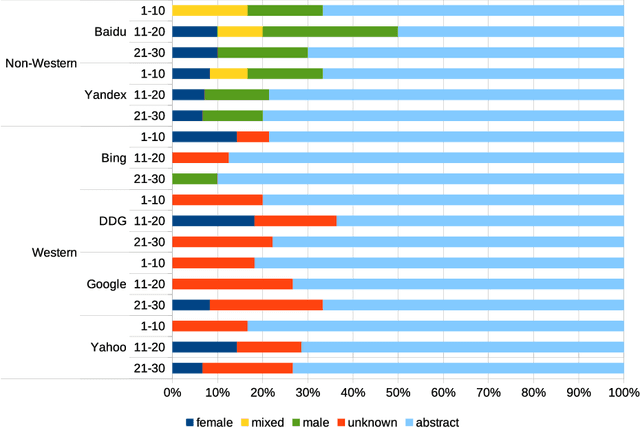
Web search engines influence perception of social reality by filtering and ranking information. However, their outputs are often subjected to bias that can lead to skewed representation of subjects such as professional occupations or gender. In our paper, we use a mixed-method approach to investigate presence of race and gender bias in representation of artificial intelligence (AI) in image search results coming from six different search engines. Our findings show that search engines prioritize anthropomorphic images of AI that portray it as white, whereas non-white images of AI are present only in non-Western search engines. By contrast, gender representation of AI is more diverse and less skewed towards a specific gender that can be attributed to higher awareness about gender bias in search outputs. Our observations indicate both the the need and the possibility for addressing bias in representation of societally relevant subjects, such as technological innovation, and emphasize the importance of designing new approaches for detecting bias in information retrieval systems.
* 16 pages, 3 figures
Auditing Source Diversity Bias in Video Search Results Using Virtual Agents
Jun 04, 2021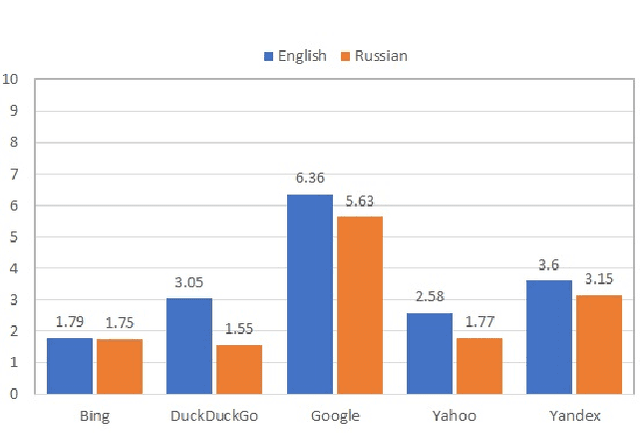
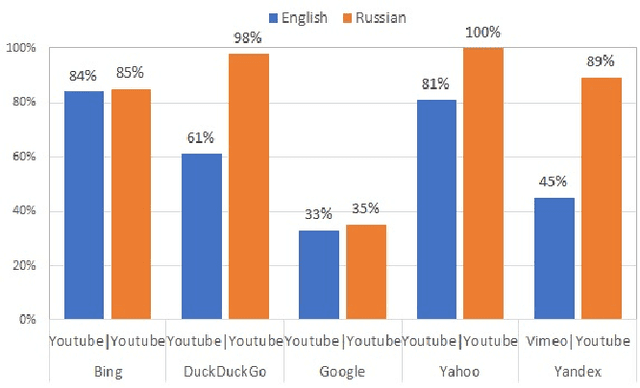
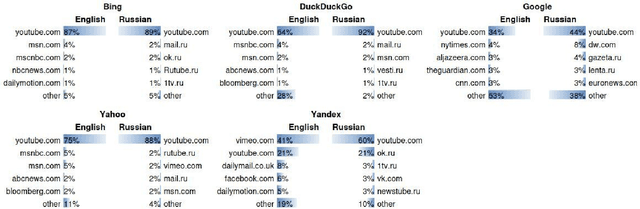
We audit the presence of domain-level source diversity bias in video search results. Using a virtual agent-based approach, we compare outputs of four Western and one non-Western search engines for English and Russian queries. Our findings highlight that source diversity varies substantially depending on the language with English queries returning more diverse outputs. We also find disproportionately high presence of a single platform, YouTube, in top search outputs for all Western search engines except Google. At the same time, we observe that Youtube's major competitors such as Vimeo or Dailymotion do not appear in the sampled Google's video search results. This finding suggests that Google might be downgrading the results from the main competitors of Google-owned Youtube and highlights the necessity for further studies focusing on the presence of own-content bias in Google's search results.