 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoci Similes: A Benchmark for Extracting Intertextualities in Latin Literature
Jan 12, 2026Tracing connections between historical texts is an important part of intertextual research, enabling scholars to reconstruct the virtual library of a writer and identify the sources influencing their creative process. These intertextual links manifest in diverse forms, ranging from direct verbatim quotations to subtle allusions and paraphrases disguised by morphological variation. Language models offer a promising path forward due to their capability of capturing semantic similarity beyond lexical overlap. However, the development of new methods for this task is held back by the scarcity of standardized benchmarks and easy-to-use datasets. We address this gap by introducing Loci Similes, a benchmark for Latin intertextuality detection comprising of a curated dataset of ~172k text segments containing 545 expert-verified parallels linking Late Antique authors to a corpus of classical authors. Using this data, we establish baselines for retrieval and classification of intertextualities with state-of-the-art LLMs.
Only a Little to the Left: A Theory-grounded Measure of Political Bias in Large Language Models
Mar 20, 2025Prompt-based language models like GPT4 and LLaMa have been used for a wide variety of use cases such as simulating agents, searching for information, or for content analysis. For all of these applications and others, political biases in these models can affect their performance. Several researchers have attempted to study political bias in language models using evaluation suites based on surveys, such as the Political Compass Test (PCT), often finding a particular leaning favored by these models. However, there is some variation in the exact prompting techniques, leading to diverging findings and most research relies on constrained-answer settings to extract model responses. Moreover, the Political Compass Test is not a scientifically valid survey instrument. In this work, we contribute a political bias measured informed by political science theory, building on survey design principles to test a wide variety of input prompts, while taking into account prompt sensitivity. We then prompt 11 different open and commercial models, differentiating between instruction-tuned and non-instruction-tuned models, and automatically classify their political stances from 88,110 responses. Leveraging this dataset, we compute political bias profiles across different prompt variations and find that while PCT exaggerates bias in certain models like GPT3.5, measures of political bias are often unstable, but generally more left-leaning for instruction-tuned models.
R.U.Psycho? Robust Unified Psychometric Testing of Language Models
Mar 13, 2025



Generative language models are increasingly being subjected to psychometric questionnaires intended for human testing, in efforts to establish their traits, as benchmarks for alignment, or to simulate participants in social science experiments. While this growing body of work sheds light on the likeness of model responses to those of humans, concerns are warranted regarding the rigour and reproducibility with which these experiments may be conducted. Instabilities in model outputs, sensitivity to prompt design, parameter settings, and a large number of available model versions increase documentation requirements. Consequently, generalization of findings is often complex and reproducibility is far from guaranteed. In this paper, we present R.U.Psycho, a framework for designing and running robust and reproducible psychometric experiments on generative language models that requires limited coding expertise. We demonstrate the capability of our framework on a variety of psychometric questionnaires, which lend support to prior findings in the literature. R.U.Psycho is available as a Python package at https://github.com/julianschelb/rupsycho.
Tag-Pag: A Dedicated Tool for Systematic Web Page Annotations
Feb 22, 2025
Tag-Pag is an application designed to simplify the categorization of web pages, a task increasingly common for researchers who scrape web pages to analyze individuals' browsing patterns or train machine learning classifiers. Unlike existing tools that focus on annotating sections of text, Tag-Pag systematizes page-level annotations, allowing users to determine whether an entire document relates to one or multiple predefined topics. Tag-Pag offers an intuitive interface to configure the input web pages and annotation labels. It integrates libraries to extract content from the HTML and URL indicators to aid the annotation process. It provides direct access to both scraped and live versions of the web page. Our tool is designed to expedite the annotation process with features like quick navigation, label assignment, and export functionality, making it a versatile and efficient tool for various research applications. Tag-Pag is available at https://github.com/Pantonius/TagPag.
Quantifying the Risks of Tool-assisted Rephrasing to Linguistic Diversity
Oct 23, 2024



Writing assistants and large language models see widespread use in the creation of text content. While their effectiveness for individual users has been evaluated in the literature, little is known about their proclivity to change language or reduce its richness when adopted by a large user base. In this paper, we take a first step towards quantifying this risk by measuring the semantic and vocabulary change enacted by the use of rephrasing tools on a multi-domain corpus of human-generated text.
Assessing In-context Learning and Fine-tuning for Topic Classification of German Web Data
Jul 23, 2024Researchers in the political and social sciences often rely on classification models to analyze trends in information consumption by examining browsing histories of millions of webpages. Automated scalable methods are necessary due to the impracticality of manual labeling. In this paper, we model the detection of topic-related content as a binary classification task and compare the accuracy of fine-tuned pre-trained encoder models against in-context learning strategies. Using only a few hundred annotated data points per topic, we detect content related to three German policies in a database of scraped webpages. We compare multilingual and monolingual models, as well as zero and few-shot approaches, and investigate the impact of negative sampling strategies and the combination of URL & content-based features. Our results show that a small sample of annotated data is sufficient to train an effective classifier. Fine-tuning encoder-based models yields better results than in-context learning. Classifiers using both URL & content-based features perform best, while using URLs alone provides adequate results when content is unavailable.
Revealing the Unwritten: Visual Investigation of Beam Search Trees to Address Language Model Prompting Challenges
Oct 17, 2023



The growing popularity of generative language models has amplified interest in interactive methods to guide model outputs. Prompt refinement is considered one of the most effective means to influence output among these methods. We identify several challenges associated with prompting large language models, categorized into data- and model-specific, linguistic, and socio-linguistic challenges. A comprehensive examination of model outputs, including runner-up candidates and their corresponding probabilities, is needed to address these issues. The beam search tree, the prevalent algorithm to sample model outputs, can inherently supply this information. Consequently, we introduce an interactive visual method for investigating the beam search tree, facilitating analysis of the decisions made by the model during generation. We quantitatively show the value of exposing the beam search tree and present five detailed analysis scenarios addressing the identified challenges. Our methodology validates existing results and offers additional insights.
Mind Your Bias: A Critical Review of Bias Detection Methods for Contextual Language Models
Nov 15, 2022



The awareness and mitigation of biases are of fundamental importance for the fair and transparent use of contextual language models, yet they crucially depend on the accurate detection of biases as a precursor. Consequently, numerous bias detection methods have been proposed, which vary in their approach, the considered type of bias, and the data used for evaluation. However, while most detection methods are derived from the word embedding association test for static word embeddings, the reported results are heterogeneous, inconsistent, and ultimately inconclusive. To address this issue, we conduct a rigorous analysis and comparison of bias detection methods for contextual language models. Our results show that minor design and implementation decisions (or errors) have a substantial and often significant impact on the derived bias scores. Overall, we find the state of the field to be both worse than previously acknowledged due to systematic and propagated errors in implementations, yet better than anticipated since divergent results in the literature homogenize after accounting for implementation errors. Based on our findings, we conclude with a discussion of paths towards more robust and consistent bias detection methods.
Collaborative and AI-aided Exam Question Generation using Wikidata in Education
Nov 15, 2022Since the COVID-19 outbreak, the use of digital learning or education platforms has significantly increased. Teachers now digitally distribute homework and provide exercise questions. In both cases, teachers need to continuously develop novel and individual questions. This process can be very time-consuming and should be facilitated and accelerated both through exchange with other teachers and by using Artificial Intelligence (AI) capabilities. To address this need, we propose a multilingual Wikimedia framework that allows for collaborative worldwide teacher knowledge engineering and subsequent AI-aided question generation, test, and correction. As a proof of concept, we present >>PhysWikiQuiz<<, a physics question generation and test engine. Our system (hosted by Wikimedia at https://physwikiquiz.wmflabs.org) retrieves physics knowledge from the open community-curated database Wikidata. It can generate questions in different variations and verify answer values and units using a Computer Algebra System (CAS). We evaluate the performance on a public benchmark dataset at each stage of the system workflow. For an average formula with three variables, the system can generate and correct up to 300 questions for individual students based on a single formula concept name as input by the teacher.
United States Politicians' Tone Became More Negative with 2016 Primary Campaigns
Jul 17, 2022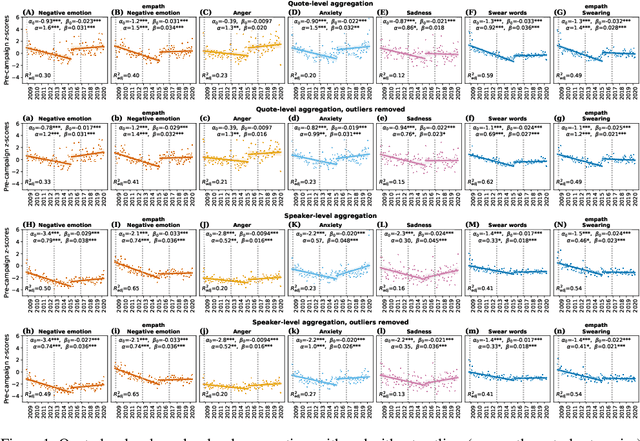
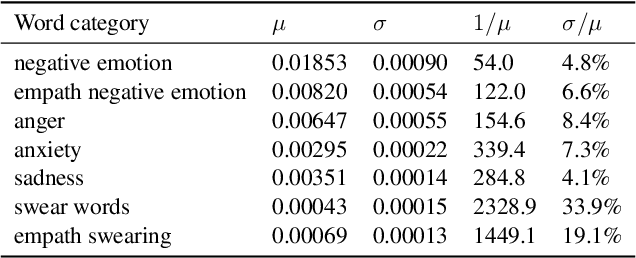
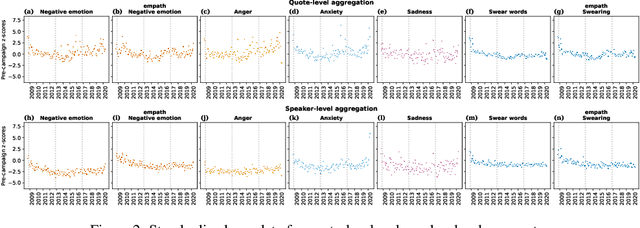
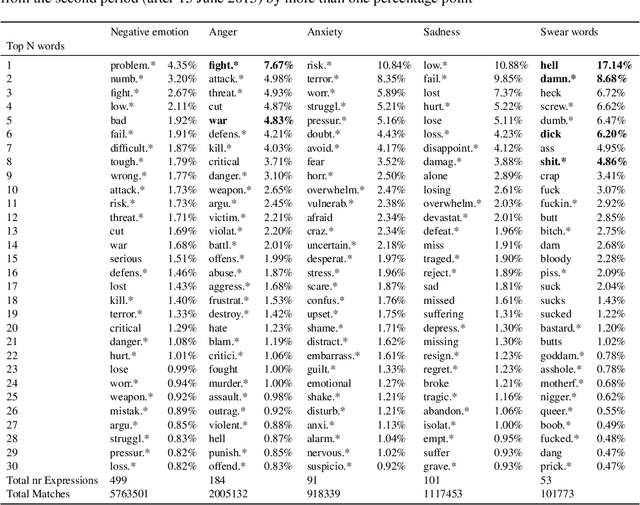
There is a widespread belief that the tone of US political language has become more negative recently, in particular when Donald Trump entered politics. At the same time, there is disagreement as to whether Trump changed or merely continued previous trends. To date, data-driven evidence regarding these questions is scarce, partly due to the difficulty of obtaining a comprehensive, longitudinal record of politicians' utterances. Here we apply psycholinguistic tools to a novel, comprehensive corpus of 24 million quotes from online news attributed to 18,627 US politicians in order to analyze how the tone of US politicians' language evolved between 2008 and 2020. We show that, whereas the frequency of negative emotion words had decreased continuously during Obama's tenure, it suddenly and lastingly increased with the 2016 primary campaigns, by 1.6 pre-campaign standard deviations, or 8% of the pre-campaign mean, in a pattern that emerges across parties. The effect size drops by 40% when omitting Trump's quotes, and by 50% when averaging over speakers rather than quotes, implying that prominent speakers, and Trump in particular, have disproportionately, though not exclusively, contributed to the rise in negative language. This work provides the first large-scale data-driven evidence of a drastic shift toward a more negative political tone following Trump's campaign start as a catalyst, with important implications for the debate about the state of US politics.