 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgegenerAItor: Tree-in-the-Loop Text Generation for Language Model Explainability and Adaptation
Mar 12, 2024



Large language models (LLMs) are widely deployed in various downstream tasks, e.g., auto-completion, aided writing, or chat-based text generation. However, the considered output candidates of the underlying search algorithm are under-explored and under-explained. We tackle this shortcoming by proposing a tree-in-the-loop approach, where a visual representation of the beam search tree is the central component for analyzing, explaining, and adapting the generated outputs. To support these tasks, we present generAItor, a visual analytics technique, augmenting the central beam search tree with various task-specific widgets, providing targeted visualizations and interaction possibilities. Our approach allows interactions on multiple levels and offers an iterative pipeline that encompasses generating, exploring, and comparing output candidates, as well as fine-tuning the model based on adapted data. Our case study shows that our tool generates new insights in gender bias analysis beyond state-of-the-art template-based methods. Additionally, we demonstrate the applicability of our approach in a qualitative user study. Finally, we quantitatively evaluate the adaptability of the model to few samples, as occurring in text-generation use cases.
Revealing the Unwritten: Visual Investigation of Beam Search Trees to Address Language Model Prompting Challenges
Oct 17, 2023



The growing popularity of generative language models has amplified interest in interactive methods to guide model outputs. Prompt refinement is considered one of the most effective means to influence output among these methods. We identify several challenges associated with prompting large language models, categorized into data- and model-specific, linguistic, and socio-linguistic challenges. A comprehensive examination of model outputs, including runner-up candidates and their corresponding probabilities, is needed to address these issues. The beam search tree, the prevalent algorithm to sample model outputs, can inherently supply this information. Consequently, we introduce an interactive visual method for investigating the beam search tree, facilitating analysis of the decisions made by the model during generation. We quantitatively show the value of exposing the beam search tree and present five detailed analysis scenarios addressing the identified challenges. Our methodology validates existing results and offers additional insights.
Semantic Concept Spaces: Guided Topic Model Refinement using Word-Embedding Projections
Aug 01, 2019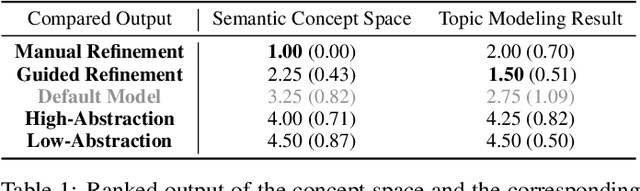
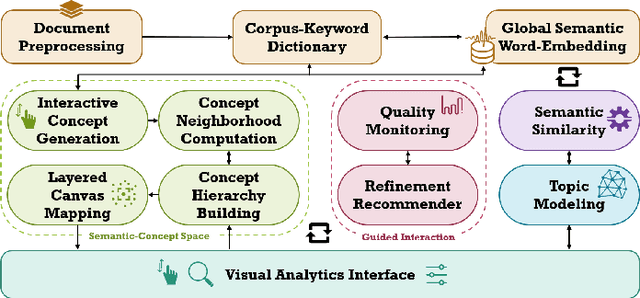
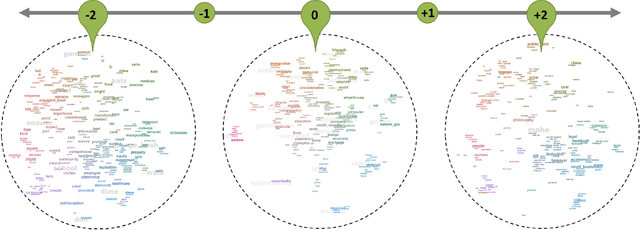

We present a framework that allows users to incorporate the semantics of their domain knowledge for topic model refinement while remaining model-agnostic. Our approach enables users to (1) understand the semantic space of the model, (2) identify regions of potential conflicts and problems, and (3) readjust the semantic relation of concepts based on their understanding, directly influencing the topic modeling. These tasks are supported by an interactive visual analytics workspace that uses word-embedding projections to define concept regions which can then be refined. The user-refined concepts are independent of a particular document collection and can be transferred to related corpora. All user interactions within the concept space directly affect the semantic relations of the underlying vector space model, which, in turn, change the topic modeling. In addition to direct manipulation, our system guides the users' decision-making process through recommended interactions that point out potential improvements. This targeted refinement aims at minimizing the feedback required for an efficient human-in-the-loop process. We confirm the improvements achieved through our approach in two user studies that show topic model quality improvements through our visual knowledge externalization and learning process.
VIANA: Visual Interactive Annotation of Argumentation
Jul 29, 2019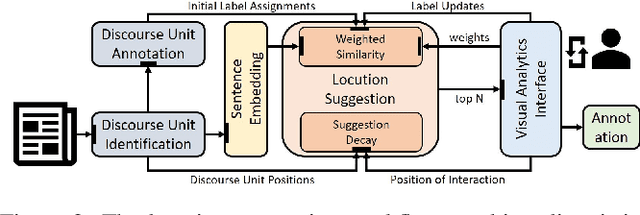
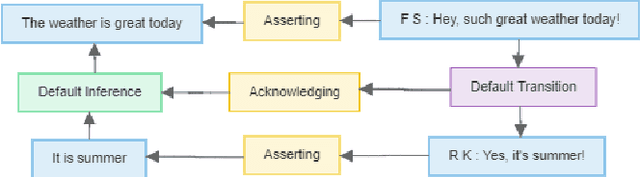
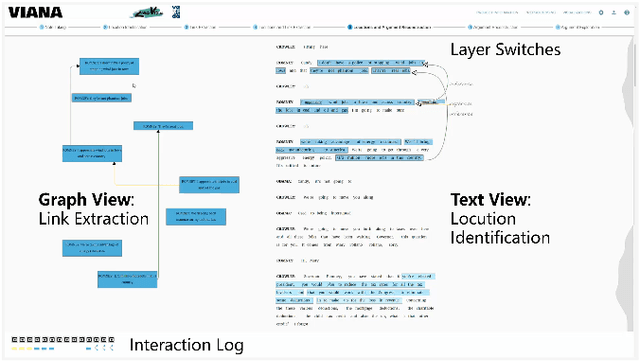

Argumentation Mining addresses the challenging tasks of identifying boundaries of argumentative text fragments and extracting their relationships. Fully automated solutions do not reach satisfactory accuracy due to their insufficient incorporation of semantics and domain knowledge. Therefore, experts currently rely on time-consuming manual annotations. In this paper, we present a visual analytics system that augments the manual annotation process by automatically suggesting which text fragments to annotate next. The accuracy of those suggestions is improved over time by incorporating linguistic knowledge and language modeling to learn a measure of argument similarity from user interactions. Based on a long-term collaboration with domain experts, we identify and model five high-level analysis tasks. We enable close reading and note-taking, annotation of arguments, argument reconstruction, extraction of argument relations, and exploration of argument graphs. To avoid context switches, we transition between all views through seamless morphing, visually anchoring all text- and graph-based layers. We evaluate our system with a two-stage expert user study based on a corpus of presidential debates. The results show that experts prefer our system over existing solutions due to the speedup provided by the automatic suggestions and the tight integration between text and graph views.