 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponseRank: Data-Efficient Reward Modeling through Preference Strength Learning
Dec 31, 2025Binary choices, as often used for reinforcement learning from human feedback (RLHF), convey only the direction of a preference. A person may choose apples over oranges and bananas over grapes, but which preference is stronger? Strength is crucial for decision-making under uncertainty and generalization of preference models, but hard to measure reliably. Metadata such as response times and inter-annotator agreement can serve as proxies for strength, but are often noisy and confounded. We propose ResponseRank to address the challenge of learning from noisy strength signals. Our method uses relative differences in proxy signals to rank responses to pairwise comparisons by their inferred preference strength. To control for systemic variation, we compare signals only locally within carefully constructed strata. This enables robust learning of utility differences consistent with strength-derived rankings while making minimal assumptions about the strength signal. Our contributions are threefold: (1) ResponseRank, a novel method that robustly learns preference strength by leveraging locally valid relative strength signals; (2) empirical evidence of improved sample efficiency and robustness across diverse tasks: synthetic preference learning (with simulated response times), language modeling (with annotator agreement), and RL control tasks (with simulated episode returns); and (3) the Pearson Distance Correlation (PDC), a novel metric that isolates cardinal utility learning from ordinal accuracy.
MelodyVis: Visual Analytics for Melodic Patterns in Sheet Music
Jul 07, 2024



Manual melody detection is a tedious task requiring high expertise level, while automatic detection is often not expressive or powerful enough. Thus, we present MelodyVis, a visual application designed in collaboration with musicology experts to explore melodic patterns in digital sheet music. MelodyVis features five connected views, including a Melody Operator Graph and a Voicing Timeline. The system utilizes eight atomic operators, such as transposition and mirroring, to capture melody repetitions and variations. Users can start their analysis by manually selecting patterns in the sheet view, and then identifying other patterns based on the selected samples through an interactive exploration process. We conducted a user study to investigate the effectiveness and usefulness of our approach and its integrated melodic operators, including usability and mental load questions. We compared the analysis executed by 25 participants with and without the operators. The study results indicate that the participants could identify at least twice as many patterns with activated operators. MelodyVis allows analysts to steer the analysis process and interpret results. Our study also confirms the usefulness of MelodyVis in supporting common analytical tasks in melodic analysis, with participants reporting improved pattern identification and interpretation. Thus, MelodyVis addresses the limitations of fully-automated approaches, enabling music analysts to step into the analysis process and uncover and understand intricate melodic patterns and transformations in sheet music.
RLHF-Blender: A Configurable Interactive Interface for Learning from Diverse Human Feedback
Aug 08, 2023
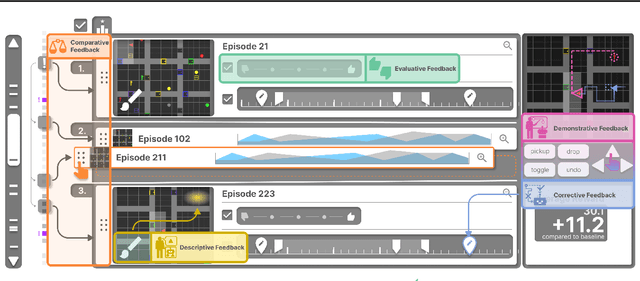
To use reinforcement learning from human feedback (RLHF) in practical applications, it is crucial to learn reward models from diverse sources of human feedback and to consider human factors involved in providing feedback of different types. However, the systematic study of learning from diverse types of feedback is held back by limited standardized tooling available to researchers. To bridge this gap, we propose RLHF-Blender, a configurable, interactive interface for learning from human feedback. RLHF-Blender provides a modular experimentation framework and implementation that enables researchers to systematically investigate the properties and qualities of human feedback for reward learning. The system facilitates the exploration of various feedback types, including demonstrations, rankings, comparisons, and natural language instructions, as well as studies considering the impact of human factors on their effectiveness. We discuss a set of concrete research opportunities enabled by RLHF-Blender. More information is available at https://rlhfblender.info/.
* 14 pages, 3 figures
The Role of Interactive Visualization in Explaining (Large) NLP Models: from Data to Inference
Jan 11, 2023



With a constant increase of learned parameters, modern neural language models become increasingly more powerful. Yet, explaining these complex model's behavior remains a widely unsolved problem. In this paper, we discuss the role interactive visualization can play in explaining NLP models (XNLP). We motivate the use of visualization in relation to target users and common NLP pipelines. We also present several use cases to provide concrete examples on XNLP with visualization. Finally, we point out an extensive list of research opportunities in this field.
Should We Trust AI? Design Dimensions for Structured Experimental Evaluations
Sep 14, 2020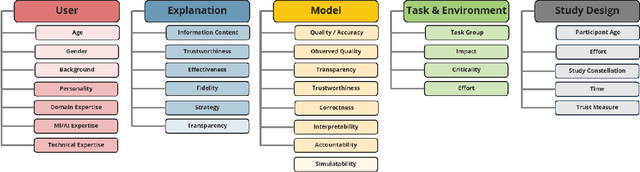
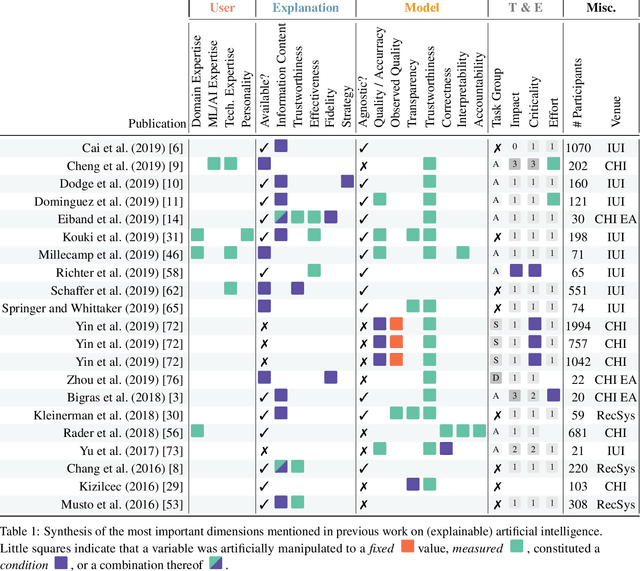
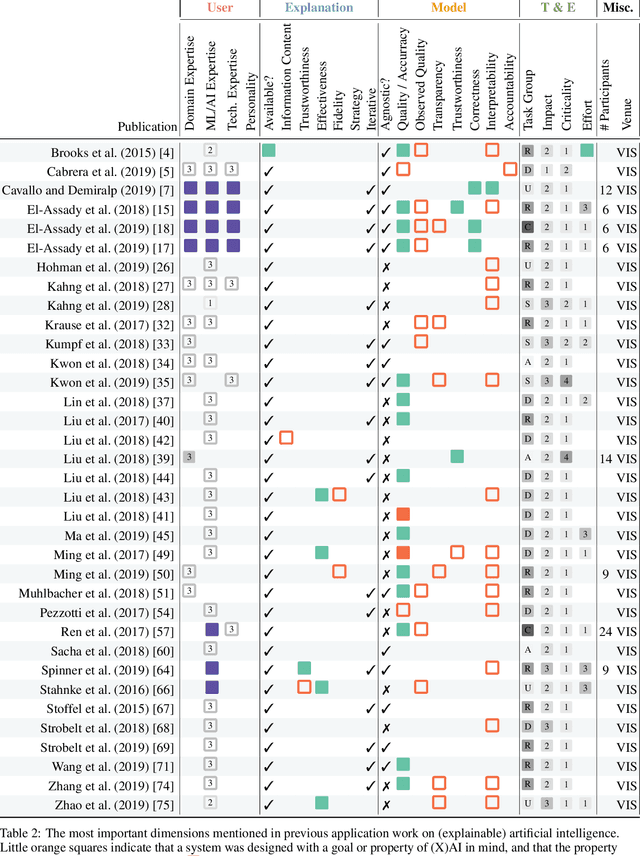
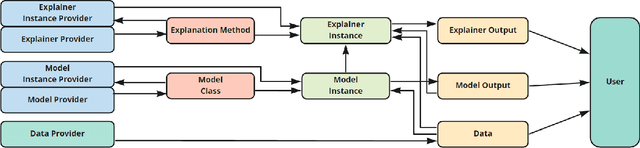
This paper systematically derives design dimensions for the structured evaluation of explainable artificial intelligence (XAI) approaches. These dimensions enable a descriptive characterization, facilitating comparisons between different study designs. They further structure the design space of XAI, converging towards a precise terminology required for a rigorous study of XAI. Our literature review differentiates between comparative studies and application papers, revealing methodological differences between the fields of machine learning, human-computer interaction, and visual analytics. Generally, each of these disciplines targets specific parts of the XAI process. Bridging the resulting gaps enables a holistic evaluation of XAI in real-world scenarios, as proposed by our conceptual model characterizing bias sources and trust-building. Furthermore, we identify and discuss the potential for future work based on observed research gaps that should lead to better coverage of the proposed model.
Semantic Concept Spaces: Guided Topic Model Refinement using Word-Embedding Projections
Aug 01, 2019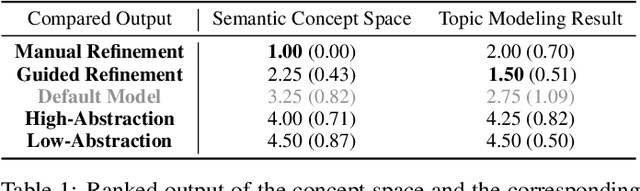
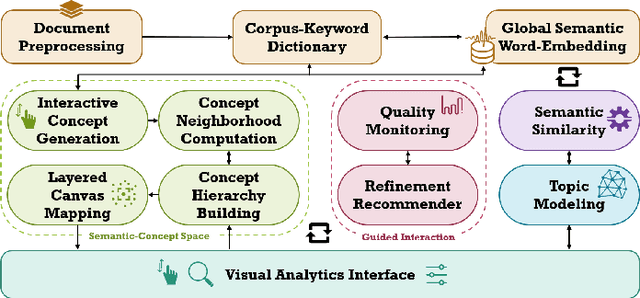
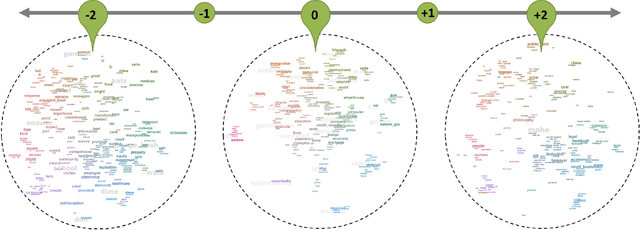

We present a framework that allows users to incorporate the semantics of their domain knowledge for topic model refinement while remaining model-agnostic. Our approach enables users to (1) understand the semantic space of the model, (2) identify regions of potential conflicts and problems, and (3) readjust the semantic relation of concepts based on their understanding, directly influencing the topic modeling. These tasks are supported by an interactive visual analytics workspace that uses word-embedding projections to define concept regions which can then be refined. The user-refined concepts are independent of a particular document collection and can be transferred to related corpora. All user interactions within the concept space directly affect the semantic relations of the underlying vector space model, which, in turn, change the topic modeling. In addition to direct manipulation, our system guides the users' decision-making process through recommended interactions that point out potential improvements. This targeted refinement aims at minimizing the feedback required for an efficient human-in-the-loop process. We confirm the improvements achieved through our approach in two user studies that show topic model quality improvements through our visual knowledge externalization and learning process.
Visual Integration of Data and Model Space in Ensemble Learning
Oct 19, 2017


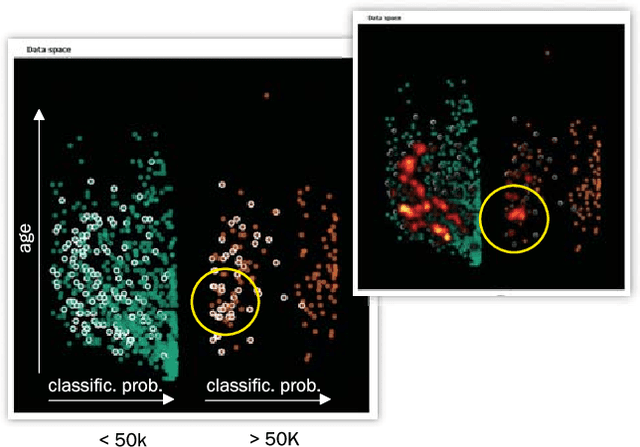
Ensembles of classifier models typically deliver superior performance and can outperform single classifier models given a dataset and classification task at hand. However, the gain in performance comes together with the lack in comprehensibility, posing a challenge to understand how each model affects the classification outputs and where the errors come from. We propose a tight visual integration of the data and the model space for exploring and combining classifier models. We introduce a workflow that builds upon the visual integration and enables the effective exploration of classification outputs and models. We then present a use case in which we start with an ensemble automatically selected by a standard ensemble selection algorithm, and show how we can manipulate models and alternative combinations.