 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Identity, Propagating Bias: Abstraction and Stereotypes in LLM-Generated Text
Sep 10, 2025
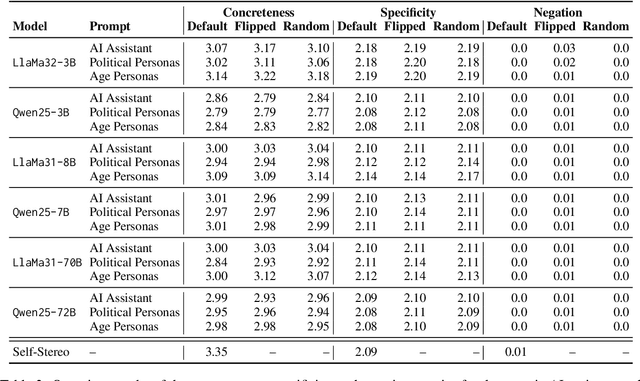
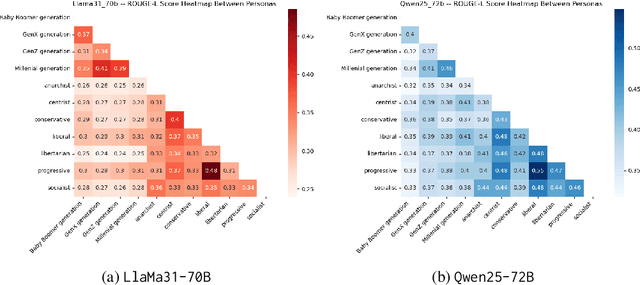
Persona-prompting is a growing strategy to steer LLMs toward simulating particular perspectives or linguistic styles through the lens of a specified identity. While this method is often used to personalize outputs, its impact on how LLMs represent social groups remains underexplored. In this paper, we investigate whether persona-prompting leads to different levels of linguistic abstraction - an established marker of stereotyping - when generating short texts linking socio-demographic categories with stereotypical or non-stereotypical attributes. Drawing on the Linguistic Expectancy Bias framework, we analyze outputs from six open-weight LLMs under three prompting conditions, comparing 11 persona-driven responses to those of a generic AI assistant. To support this analysis, we introduce Self-Stereo, a new dataset of self-reported stereotypes from Reddit. We measure abstraction through three metrics: concreteness, specificity, and negation. Our results highlight the limits of persona-prompting in modulating abstraction in language, confirming criticisms about the ecology of personas as representative of socio-demographic groups and raising concerns about the risk of propagating stereotypes even when seemingly evoking the voice of a marginalized group.
Improving Causal Interventions in Amnesic Probing with Mean Projection or LEACE
Jun 13, 2025Amnesic probing is a technique used to examine the influence of specific linguistic information on the behaviour of a model. This involves identifying and removing the relevant information and then assessing whether the model's performance on the main task changes. If the removed information is relevant, the model's performance should decline. The difficulty with this approach lies in removing only the target information while leaving other information unchanged. It has been shown that Iterative Nullspace Projection (INLP), a widely used removal technique, introduces random modifications to representations when eliminating target information. We demonstrate that Mean Projection (MP) and LEACE, two proposed alternatives, remove information in a more targeted manner, thereby enhancing the potential for obtaining behavioural explanations through Amnesic Probing.
ARN: A Comprehensive Framework and Dataset for Analogical Reasoning on Narratives
Oct 02, 2023Analogical reasoning is one of the prime abilities of humans and is linked to creativity and scientific discoveries. This ability has been studied extensively in natural language processing (NLP) as well as in cognitive psychology by proposing various benchmarks and evaluation setups. Yet, a substantial gap exists between evaluations of analogical reasoning in cognitive psychology and NLP. Our aim is to bridge this by computationally adapting theories related to analogical reasoning from cognitive psychology in the context of narratives and developing an evaluation framework large in scale. More concretely, we propose the task of matching narratives based on system mappings and release the Analogical Reasoning on Narratives (ARN) dataset. To create the dataset, we devise a framework inspired by cognitive psychology theories about analogical reasoning to utilize narratives and their components to form mappings of different abstractness levels. These mappings are then leveraged to create pairs of analogies and disanalogies/distractors with more than 1k triples of query narratives, analogies, and distractors. We cover four categories of far/near analogies and far/near distractors that allow us to study analogical reasoning in models from distinct perspectives. In this study, we evaluate different large language models (LLMs) on this task. Our results demonstrate that LLMs struggle to recognize higher-order mappings when they are not accompanied by lower-order mappings (far analogies) and show better performance when all mappings are present simultaneously (near analogies). We observe that in all the settings, the analogical reasoning abilities of LLMs can be easily impaired by near distractors that form lower-order mappings with the query narratives.
The Role of Interactive Visualization in Explaining (Large) NLP Models: from Data to Inference
Jan 11, 2023



With a constant increase of learned parameters, modern neural language models become increasingly more powerful. Yet, explaining these complex model's behavior remains a widely unsolved problem. In this paper, we discuss the role interactive visualization can play in explaining NLP models (XNLP). We motivate the use of visualization in relation to target users and common NLP pipelines. We also present several use cases to provide concrete examples on XNLP with visualization. Finally, we point out an extensive list of research opportunities in this field.
Better Hit the Nail on the Head than Beat around the Bush: Removing Protected Attributes with a Single Projection
Dec 08, 2022Bias elimination and recent probing studies attempt to remove specific information from embedding spaces. Here it is important to remove as much of the target information as possible, while preserving any other information present. INLP is a popular recent method which removes specific information through iterative nullspace projections. Multiple iterations, however, increase the risk that information other than the target is negatively affected. We introduce two methods that find a single targeted projection: Mean Projection (MP, more efficient) and Tukey Median Projection (TMP, with theoretical guarantees). Our comparison between MP and INLP shows that (1) one MP projection removes linear separability based on the target and (2) MP has less impact on the overall space. Further analysis shows that applying random projections after MP leads to the same overall effects on the embedding space as the multiple projections of INLP. Applying one targeted (MP) projection hence is methodologically cleaner than applying multiple (INLP) projections that introduce random effects.
* EMNLP 2022
Firearms and Tigers are Dangerous, Kitchen Knives and Zebras are Not: Testing whether Word Embeddings Can Tell
Sep 05, 2018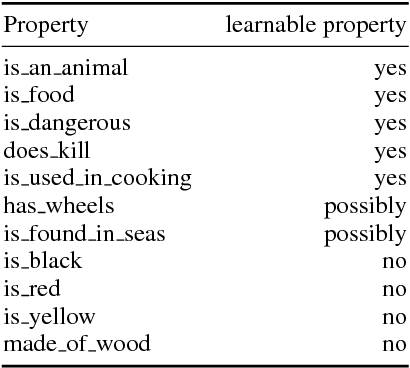
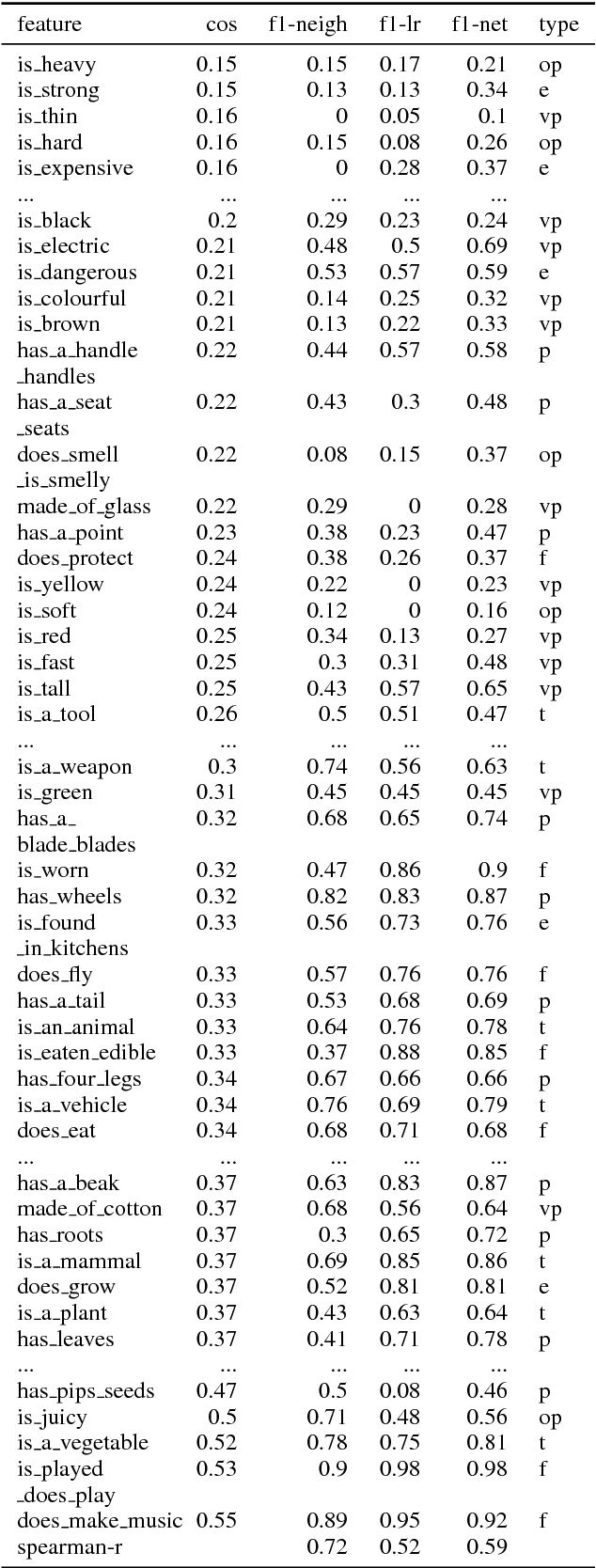
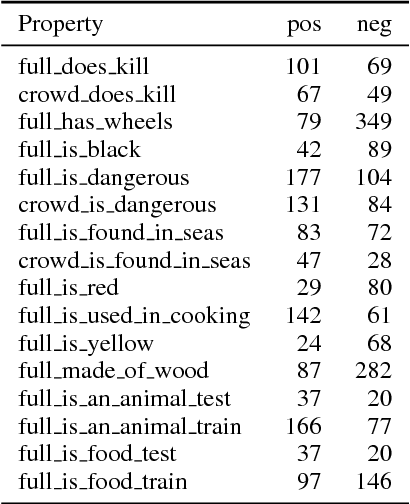
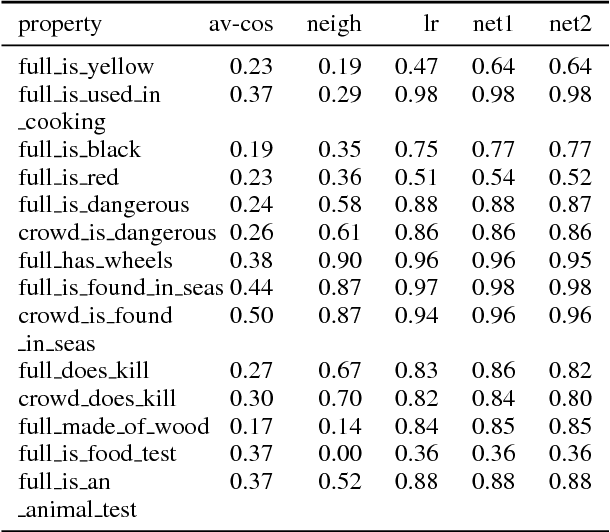
This paper presents an approach for investigating the nature of semantic information captured by word embeddings. We propose a method that extends an existing human-elicited semantic property dataset with gold negative examples using crowd judgments. Our experimental approach tests the ability of supervised classifiers to identify semantic features in word embedding vectors and com- pares this to a feature-identification method based on full vector cosine similarity. The idea behind this method is that properties identified by classifiers, but not through full vector comparison are captured by embeddings. Properties that cannot be identified by either method are not. Our results provide an initial indication that semantic properties relevant for the way entities interact (e.g. dangerous) are captured, while perceptual information (e.g. colors) is not represented. We conclude that, though preliminary, these results show that our method is suitable for identifying which properties are captured by embeddings.