 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou've Changed: Detecting Modification of Black-Box Large Language Models
Apr 14, 2025

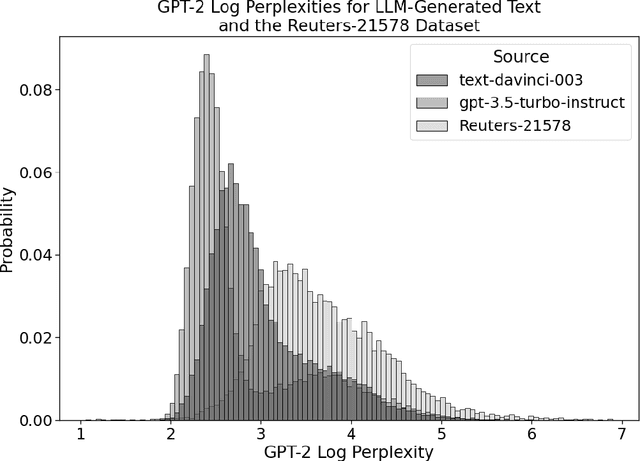

Large Language Models (LLMs) are often provided as a service via an API, making it challenging for developers to detect changes in their behavior. We present an approach to monitor LLMs for changes by comparing the distributions of linguistic and psycholinguistic features of generated text. Our method uses a statistical test to determine whether the distributions of features from two samples of text are equivalent, allowing developers to identify when an LLM has changed. We demonstrate the effectiveness of our approach using five OpenAI completion models and Meta's Llama 3 70B chat model. Our results show that simple text features coupled with a statistical test can distinguish between language models. We also explore the use of our approach to detect prompt injection attacks. Our work enables frequent LLM change monitoring and avoids computationally expensive benchmark evaluations.
LLM-based Corroborating and Refuting Evidence Retrieval for Scientific Claim Verification
Mar 11, 2025In this paper, we introduce CIBER (Claim Investigation Based on Evidence Retrieval), an extension of the Retrieval-Augmented Generation (RAG) framework designed to identify corroborating and refuting documents as evidence for scientific claim verification. CIBER addresses the inherent uncertainty in Large Language Models (LLMs) by evaluating response consistency across diverse interrogation probes. By focusing on the behavioral analysis of LLMs without requiring access to their internal information, CIBER is applicable to both white-box and black-box models. Furthermore, CIBER operates in an unsupervised manner, enabling easy generalization across various scientific domains. Comprehensive evaluations conducted using LLMs with varying levels of linguistic proficiency reveal CIBER's superior performance compared to conventional RAG approaches. These findings not only highlight the effectiveness of CIBER but also provide valuable insights for future advancements in LLM-based scientific claim verification.
GenderAlign: An Alignment Dataset for Mitigating Gender Bias in Large Language Models
Jun 20, 2024



Large Language Models (LLMs) are prone to generating content that exhibits gender biases, raising significant ethical concerns. Alignment, the process of fine-tuning LLMs to better align with desired behaviors, is recognized as an effective approach to mitigate gender biases. Although proprietary LLMs have made significant strides in mitigating gender bias, their alignment datasets are not publicly available. The commonly used and publicly available alignment dataset, HH-RLHF, still exhibits gender bias to some extent. There is a lack of publicly available alignment datasets specifically designed to address gender bias. Hence, we developed a new dataset named GenderAlign, aiming at mitigating a comprehensive set of gender biases in LLMs. This dataset comprises 8k single-turn dialogues, each paired with a "chosen" and a "rejected" response. Compared to the "rejected" responses, the "chosen" responses demonstrate lower levels of gender bias and higher quality. Furthermore, we categorized the gender biases in the "rejected" responses of GenderAlign into 4 principal categories. The experimental results show the effectiveness of GenderAlign in reducing gender bias in LLMs.
RAGged Edges: The Double-Edged Sword of Retrieval-Augmented Chatbots
Mar 13, 2024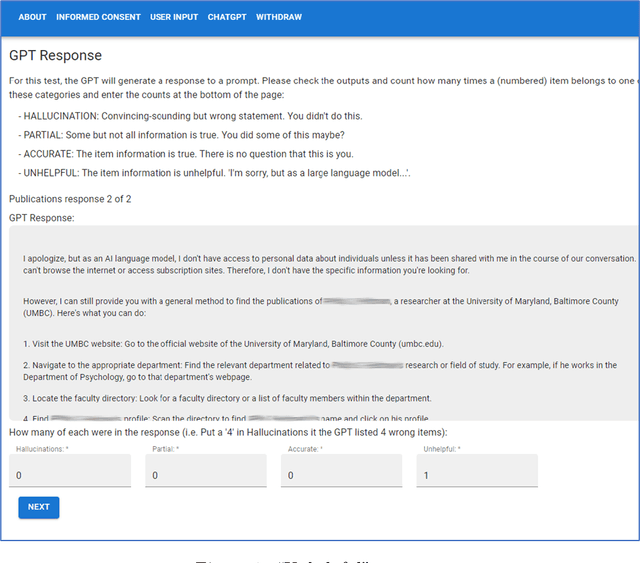

Large language models (LLMs) like ChatGPT demonstrate the remarkable progress of artificial intelligence. However, their tendency to hallucinate -- generate plausible but false information -- poses a significant challenge. This issue is critical, as seen in recent court cases where ChatGPT's use led to citations of non-existent legal rulings. This paper explores how Retrieval-Augmented Generation (RAG) can counter hallucinations by integrating external knowledge with prompts. We empirically evaluate RAG against standard LLMs using prompts designed to induce hallucinations. Our results show that RAG increases accuracy in some cases, but can still be misled when prompts directly contradict the model's pre-trained understanding. These findings highlight the complex nature of hallucinations and the need for more robust solutions to ensure LLM reliability in real-world applications. We offer practical recommendations for RAG deployment and discuss implications for the development of more trustworthy LLMs.
Teach me with a Whisper: Enhancing Large Language Models for Analyzing Spoken Transcripts using Speech Embeddings
Nov 13, 2023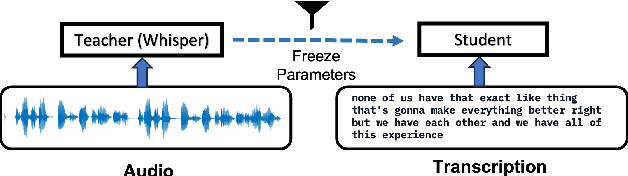



Speech data has rich acoustic and paralinguistic information with important cues for understanding a speaker's tone, emotion, and intent, yet traditional large language models such as BERT do not incorporate this information. There has been an increased interest in multi-modal language models leveraging audio and/or visual information and text. However, current multi-modal language models require both text and audio/visual data streams during inference/test time. In this work, we propose a methodology for training language models leveraging spoken language audio data but without requiring the audio stream during prediction time. This leads to an improved language model for analyzing spoken transcripts while avoiding an audio processing overhead at test time. We achieve this via an audio-language knowledge distillation framework, where we transfer acoustic and paralinguistic information from a pre-trained speech embedding (OpenAI Whisper) teacher model to help train a student language model on an audio-text dataset. In our experiments, the student model achieves consistent improvement over traditional language models on tasks analyzing spoken transcripts.
Trapping LLM Hallucinations Using Tagged Context Prompts
Jun 09, 2023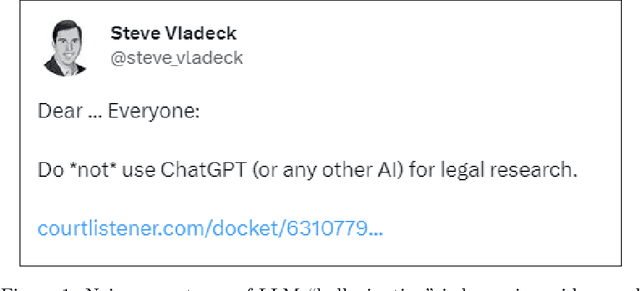
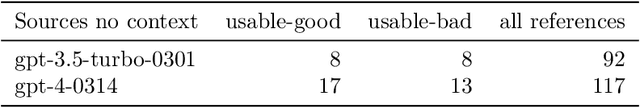
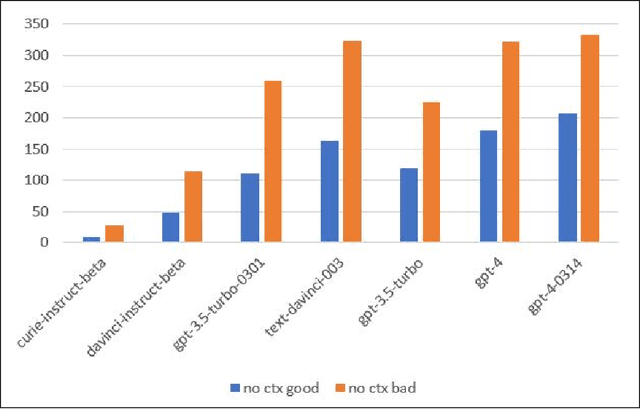
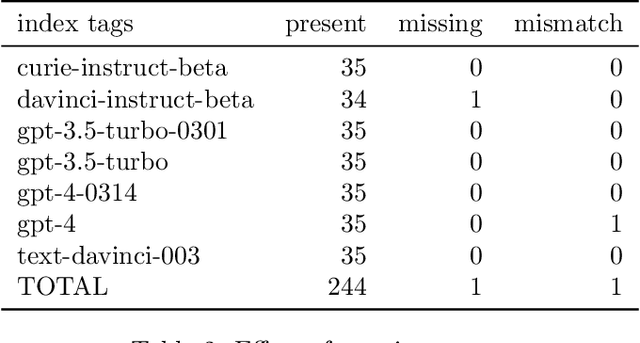
Recent advances in large language models (LLMs), such as ChatGPT, have led to highly sophisticated conversation agents. However, these models suffer from "hallucinations," where the model generates false or fabricated information. Addressing this challenge is crucial, particularly with AI-driven platforms being adopted across various sectors. In this paper, we propose a novel method to recognize and flag instances when LLMs perform outside their domain knowledge, and ensuring users receive accurate information. We find that the use of context combined with embedded tags can successfully combat hallucinations within generative language models. To do this, we baseline hallucination frequency in no-context prompt-response pairs using generated URLs as easily-tested indicators of fabricated data. We observed a significant reduction in overall hallucination when context was supplied along with question prompts for tested generative engines. Lastly, we evaluated how placing tags within contexts impacted model responses and were able to eliminate hallucinations in responses with 98.88% effectiveness.
The Role of Interactive Visualization in Explaining (Large) NLP Models: from Data to Inference
Jan 11, 2023



With a constant increase of learned parameters, modern neural language models become increasingly more powerful. Yet, explaining these complex model's behavior remains a widely unsolved problem. In this paper, we discuss the role interactive visualization can play in explaining NLP models (XNLP). We motivate the use of visualization in relation to target users and common NLP pipelines. We also present several use cases to provide concrete examples on XNLP with visualization. Finally, we point out an extensive list of research opportunities in this field.
Fair Inference for Discrete Latent Variable Models
Sep 15, 2022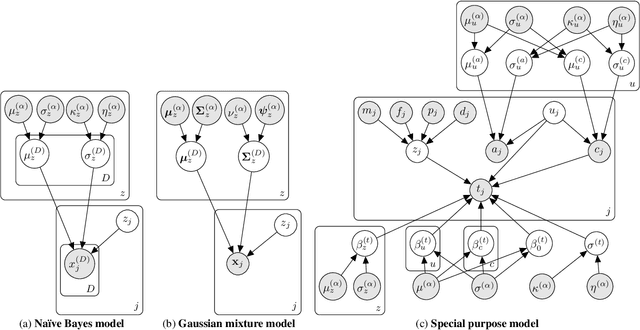

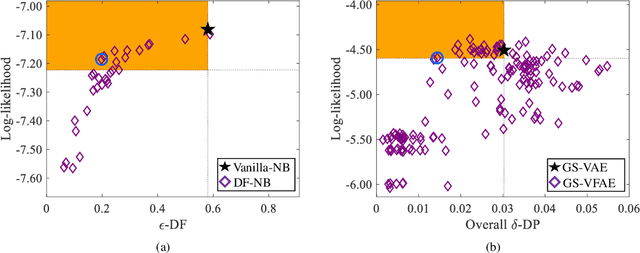

It is now well understood that machine learning models, trained on data without due care, often exhibit unfair and discriminatory behavior against certain populations. Traditional algorithmic fairness research has mainly focused on supervised learning tasks, particularly classification. While fairness in unsupervised learning has received some attention, the literature has primarily addressed fair representation learning of continuous embeddings. In this paper, we conversely focus on unsupervised learning using probabilistic graphical models with discrete latent variables. We develop a fair stochastic variational inference technique for the discrete latent variables, which is accomplished by including a fairness penalty on the variational distribution that aims to respect the principles of intersectionality, a critical lens on fairness from the legal, social science, and humanities literature, and then optimizing the variational parameters under this penalty. We first show the utility of our method in improving equity and fairness for clustering using na\"ive Bayes and Gaussian mixture models on benchmark datasets. To demonstrate the generality of our approach and its potential for real-world impact, we then develop a special-purpose graphical model for criminal justice risk assessments, and use our fairness approach to prevent the inferences from encoding unfair societal biases.
Tell Me Something That Will Help Me Trust You: A Survey of Trust Calibration in Human-Agent Interaction
May 06, 2022
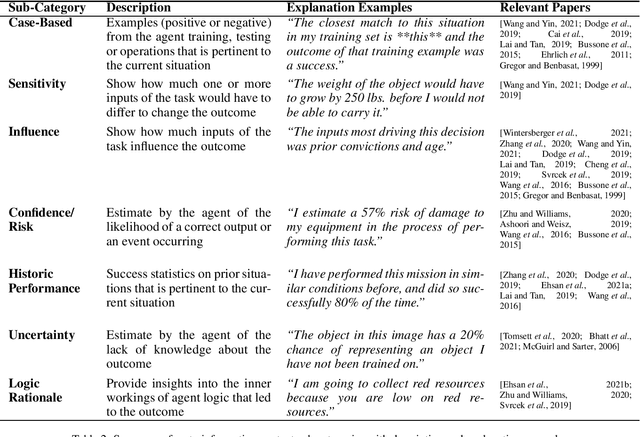
When a human receives a prediction or recommended course of action from an intelligent agent, what additional information, beyond the prediction or recommendation itself, does the human require from the agent to decide whether to trust or reject the prediction or recommendation? In this paper we survey literature in the area of trust between a single human supervisor and a single agent subordinate to determine the nature and extent of this additional information and to characterize it into a taxonomy that can be leveraged by future researchers and intelligent agent practitioners. By examining this question from a human-centered, information-focused point of view, we can begin to compare and contrast different implementations and also provide insight and directions for future work.
Bias: Friend or Foe? User Acceptance of Gender Stereotypes in Automated Career Recommendations
Jun 13, 2021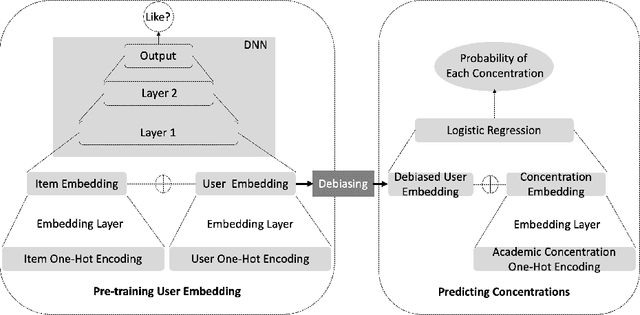

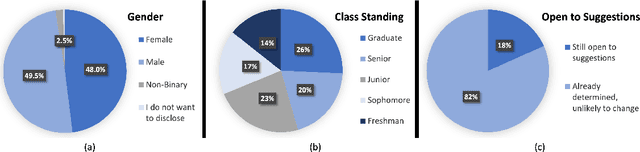
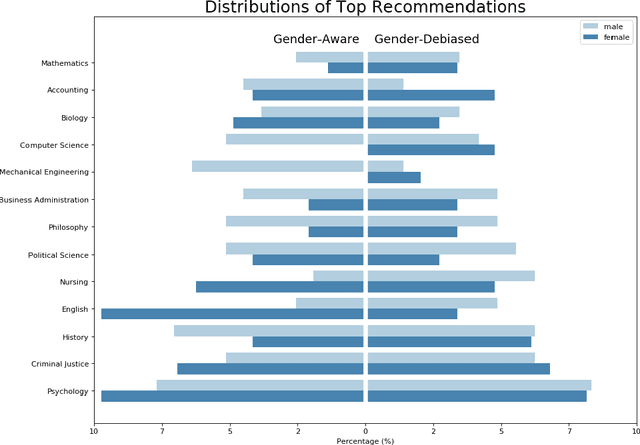
Currently, there is a surge of interest in fair Artificial Intelligence (AI) and Machine Learning (ML) research which aims to mitigate discriminatory bias in AI algorithms, e.g. along lines of gender, age, and race. While most research in this domain focuses on developing fair AI algorithms, in this work, we show that a fair AI algorithm on its own may be insufficient to achieve its intended results in the real world. Using career recommendation as a case study, we build a fair AI career recommender by employing gender debiasing machine learning techniques. Our offline evaluation showed that the debiased recommender makes fairer career recommendations without sacrificing its accuracy. Nevertheless, an online user study of more than 200 college students revealed that participants on average prefer the original biased system over the debiased system. Specifically, we found that perceived gender disparity is a determining factor for the acceptance of a recommendation. In other words, our results demonstrate we cannot fully address the gender bias issue in AI recommendations without addressing the gender bias in humans.