 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Corroborating and Refuting Evidence Retrieval for Scientific Claim Verification
Mar 11, 2025In this paper, we introduce CIBER (Claim Investigation Based on Evidence Retrieval), an extension of the Retrieval-Augmented Generation (RAG) framework designed to identify corroborating and refuting documents as evidence for scientific claim verification. CIBER addresses the inherent uncertainty in Large Language Models (LLMs) by evaluating response consistency across diverse interrogation probes. By focusing on the behavioral analysis of LLMs without requiring access to their internal information, CIBER is applicable to both white-box and black-box models. Furthermore, CIBER operates in an unsupervised manner, enabling easy generalization across various scientific domains. Comprehensive evaluations conducted using LLMs with varying levels of linguistic proficiency reveal CIBER's superior performance compared to conventional RAG approaches. These findings not only highlight the effectiveness of CIBER but also provide valuable insights for future advancements in LLM-based scientific claim verification.
Trapping LLM Hallucinations Using Tagged Context Prompts
Jun 09, 2023
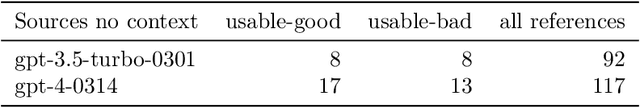
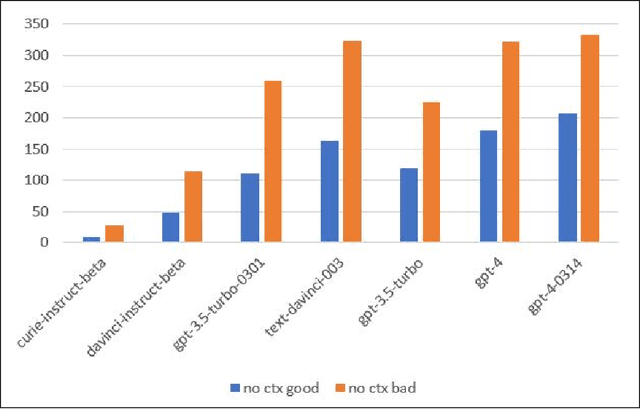
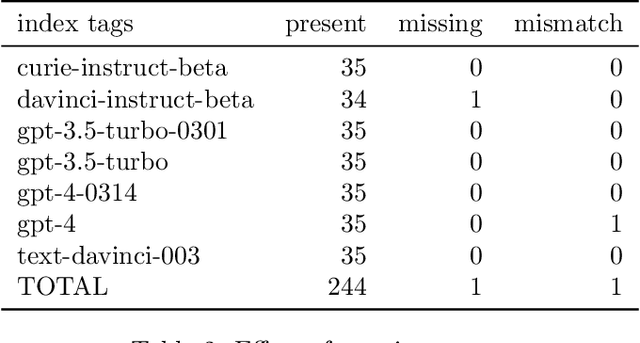
Recent advances in large language models (LLMs), such as ChatGPT, have led to highly sophisticated conversation agents. However, these models suffer from "hallucinations," where the model generates false or fabricated information. Addressing this challenge is crucial, particularly with AI-driven platforms being adopted across various sectors. In this paper, we propose a novel method to recognize and flag instances when LLMs perform outside their domain knowledge, and ensuring users receive accurate information. We find that the use of context combined with embedded tags can successfully combat hallucinations within generative language models. To do this, we baseline hallucination frequency in no-context prompt-response pairs using generated URLs as easily-tested indicators of fabricated data. We observed a significant reduction in overall hallucination when context was supplied along with question prompts for tested generative engines. Lastly, we evaluated how placing tags within contexts impacted model responses and were able to eliminate hallucinations in responses with 98.88% effectiveness.
Fair Inference for Discrete Latent Variable Models
Sep 15, 2022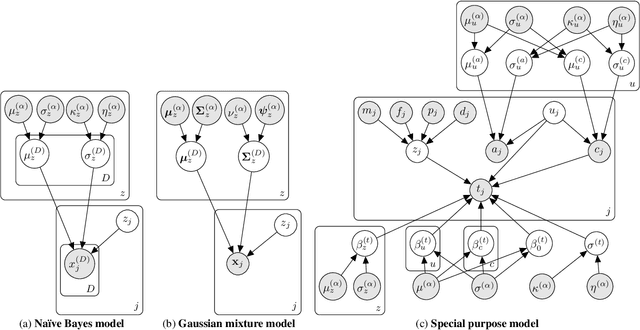

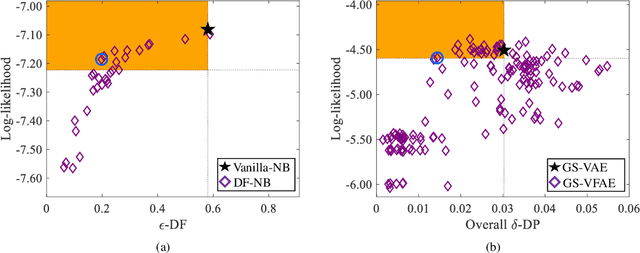

It is now well understood that machine learning models, trained on data without due care, often exhibit unfair and discriminatory behavior against certain populations. Traditional algorithmic fairness research has mainly focused on supervised learning tasks, particularly classification. While fairness in unsupervised learning has received some attention, the literature has primarily addressed fair representation learning of continuous embeddings. In this paper, we conversely focus on unsupervised learning using probabilistic graphical models with discrete latent variables. We develop a fair stochastic variational inference technique for the discrete latent variables, which is accomplished by including a fairness penalty on the variational distribution that aims to respect the principles of intersectionality, a critical lens on fairness from the legal, social science, and humanities literature, and then optimizing the variational parameters under this penalty. We first show the utility of our method in improving equity and fairness for clustering using na\"ive Bayes and Gaussian mixture models on benchmark datasets. To demonstrate the generality of our approach and its potential for real-world impact, we then develop a special-purpose graphical model for criminal justice risk assessments, and use our fairness approach to prevent the inferences from encoding unfair societal biases.
Polling Latent Opinions: A Method for Computational Sociolinguistics Using Transformer Language Models
Apr 19, 2022


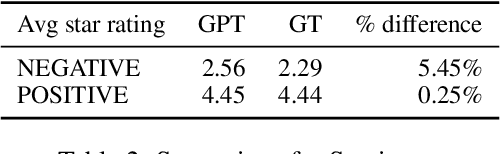
Text analysis of social media for sentiment, topic analysis, and other analysis depends initially on the selection of keywords and phrases that will be used to create the research corpora. However, keywords that researchers choose may occur infrequently, leading to errors that arise from using small samples. In this paper, we use the capacity for memorization, interpolation, and extrapolation of Transformer Language Models such as the GPT series to learn the linguistic behaviors of a subgroup within larger corpora of Yelp reviews. We then use prompt-based queries to generate synthetic text that can be analyzed to produce insights into specific opinions held by the populations that the models were trained on. Once learned, more specific sentiment queries can be made of the model with high levels of accuracy when compared to traditional keyword searches. We show that even in cases where a specific keyphrase is limited or not present at all in the training corpora, the GPT is able to accurately generate large volumes of text that have the correct sentiment.
Learning User Embeddings from Temporal Social Media Data: A Survey
May 17, 2021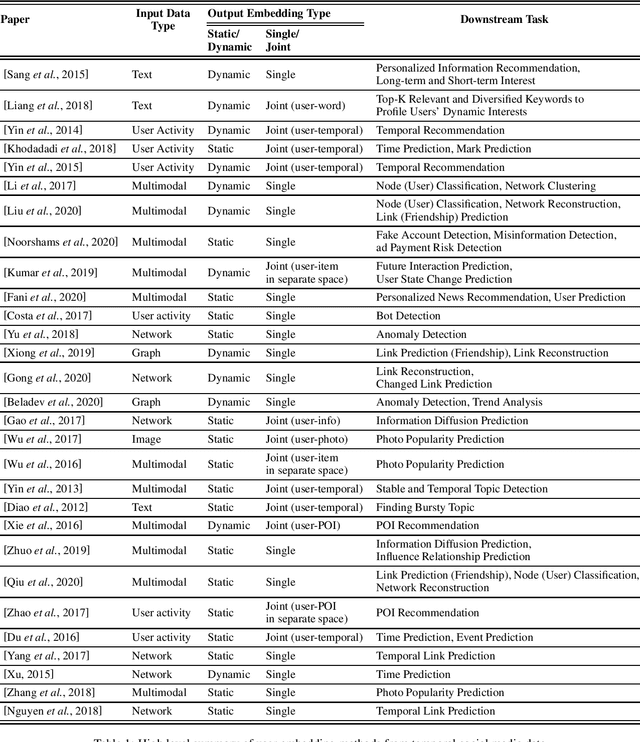
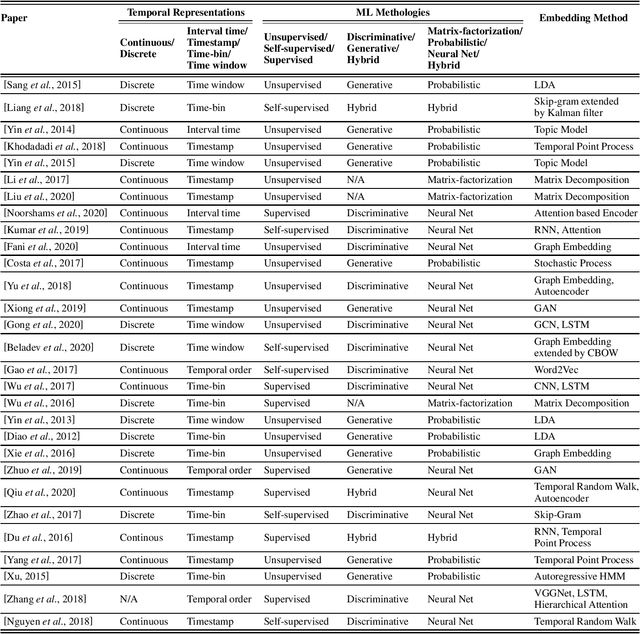
User-generated data on social media contain rich information about who we are, what we like and how we make decisions. In this paper, we survey representative work on learning a concise latent user representation (a.k.a. user embedding) that can capture the main characteristics of a social media user. The learned user embeddings can later be used to support different downstream user analysis tasks such as personality modeling, suicidal risk assessment and purchase decision prediction. The temporal nature of user-generated data on social media has largely been overlooked in much of the existing user embedding literature. In this survey, we focus on research that bridges the gap by incorporating temporal/sequential information in user representation learning. We categorize relevant papers along several key dimensions, identify limitations in the current work and suggest future research directions.
Analyzing COVID-19 Tweets with Transformer-based Language Models
May 06, 2021
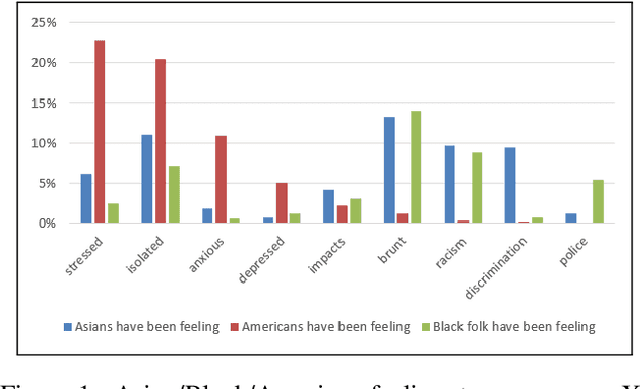

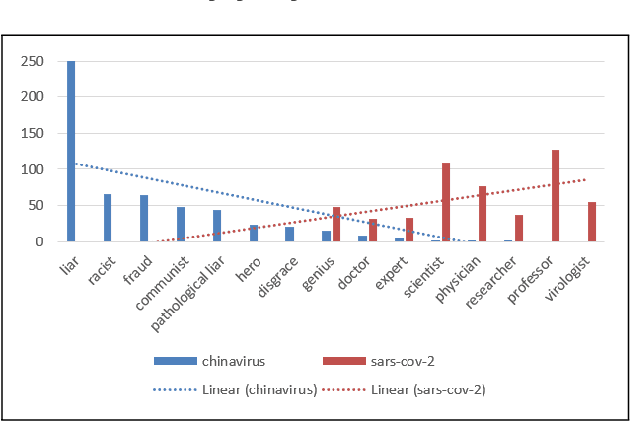
This paper describes a method for using Transformer-based Language Models (TLMs) to understand public opinion from social media posts. In this approach, we train a set of GPT models on several COVID-19 tweet corpora that reflect populations of users with distinctive views. We then use prompt-based queries to probe these models to reveal insights into the biases and opinions of the users. We demonstrate how this approach can be used to produce results which resemble polling the public on diverse social, political and public health issues. The results on the COVID-19 tweet data show that transformer language models are promising tools that can help us understand public opinions on social media at scale.
Equitable Allocation of Healthcare Resources with Fair Cox Models
Oct 14, 2020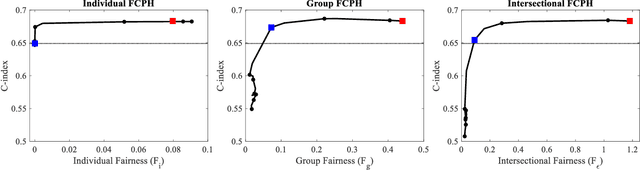
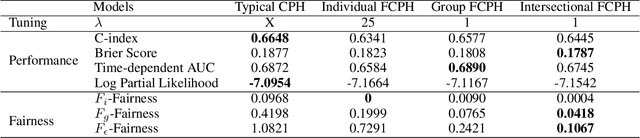
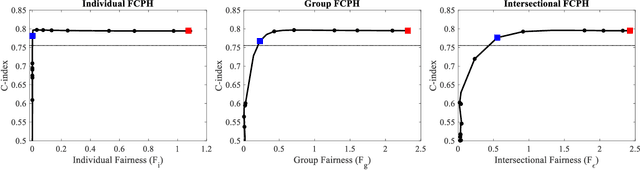
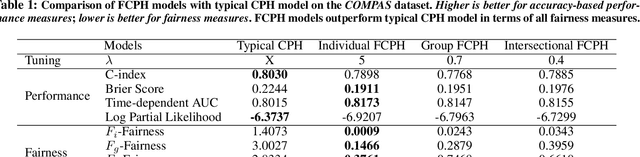
Healthcare programs such as Medicaid provide crucial services to vulnerable populations, but due to limited resources, many of the individuals who need these services the most languish on waiting lists. Survival models, e.g. the Cox proportional hazards model, can potentially improve this situation by predicting individuals' levels of need, which can then be used to prioritize the waiting lists. Providing care to those in need can prevent institutionalization for those individuals, which both improves quality of life and reduces overall costs. While the benefits of such an approach are clear, care must be taken to ensure that the prioritization process is fair or independent of demographic information-based harmful stereotypes. In this work, we develop multiple fairness definitions for survival models and corresponding fair Cox proportional hazards models to ensure equitable allocation of healthcare resources. We demonstrate the utility of our methods in terms of fairness and predictive accuracy on two publicly available survival datasets.
Neural Embedding Allocation: Distributed Representations of Topic Models
Sep 10, 2019
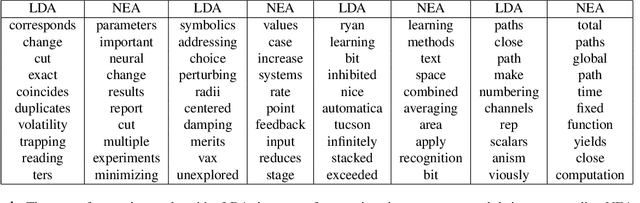
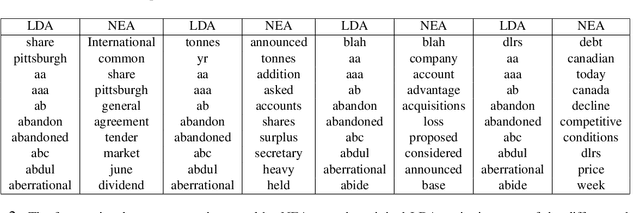

Word embedding models such as the skip-gram learn vector representations of words' semantic relationships, and document embedding models learn similar representations for documents. On the other hand, topic models provide latent representations of the documents' topical themes. To get the benefits of these representations simultaneously, we propose a unifying algorithm, called neural embedding allocation (NEA), which deconstructs topic models into interpretable vector-space embeddings of words, topics, documents, authors, and so on, by learning neural embeddings to mimic the topic models. We showcase NEA's effectiveness and generality on LDA, author-topic models and the recently proposed mixed membership skip gram topic model and achieve better performance with the embeddings compared to several state-of-the-art models. Furthermore, we demonstrate that using NEA to smooth out the topics improves coherence scores over the original topic models when the number of topics is large.
Dense Distributions from Sparse Samples: Improved Gibbs Sampling Parameter Estimators for LDA
Apr 11, 2017
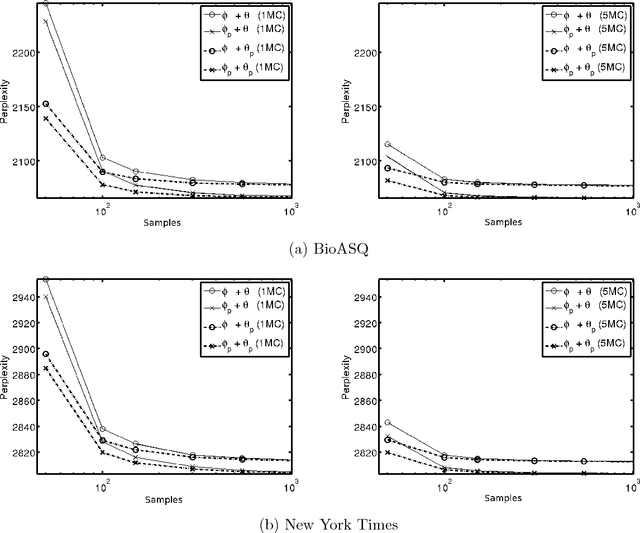

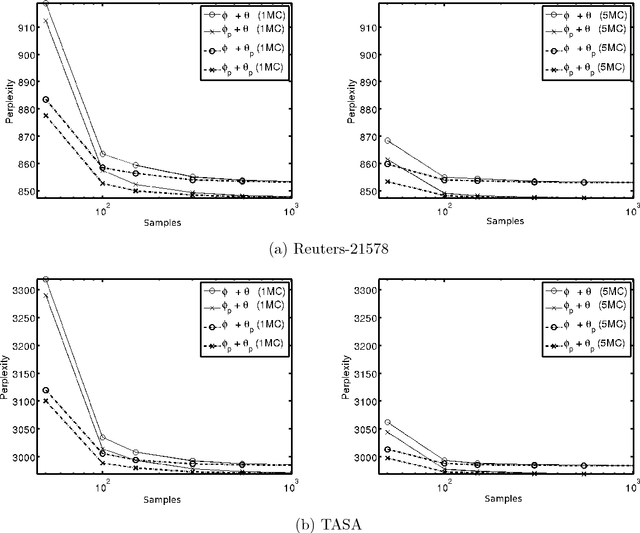
We introduce a novel approach for estimating Latent Dirichlet Allocation (LDA) parameters from collapsed Gibbs samples (CGS), by leveraging the full conditional distributions over the latent variable assignments to efficiently average over multiple samples, for little more computational cost than drawing a single additional collapsed Gibbs sample. Our approach can be understood as adapting the soft clustering methodology of Collapsed Variational Bayes (CVB0) to CGS parameter estimation, in order to get the best of both techniques. Our estimators can straightforwardly be applied to the output of any existing implementation of CGS, including modern accelerated variants. We perform extensive empirical comparisons of our estimators with those of standard collapsed inference algorithms on real-world data for both unsupervised LDA and Prior-LDA, a supervised variant of LDA for multi-label classification. Our results show a consistent advantage of our approach over traditional CGS under all experimental conditions, and over CVB0 inference in the majority of conditions. More broadly, our results highlight the importance of averaging over multiple samples in LDA parameter estimation, and the use of efficient computational techniques to do so.