 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Distributions from Sparse Samples: Improved Gibbs Sampling Parameter Estimators for LDA
Apr 11, 2017
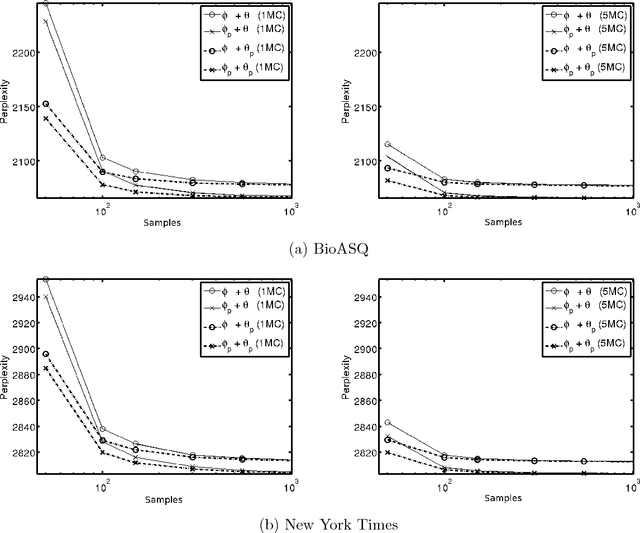

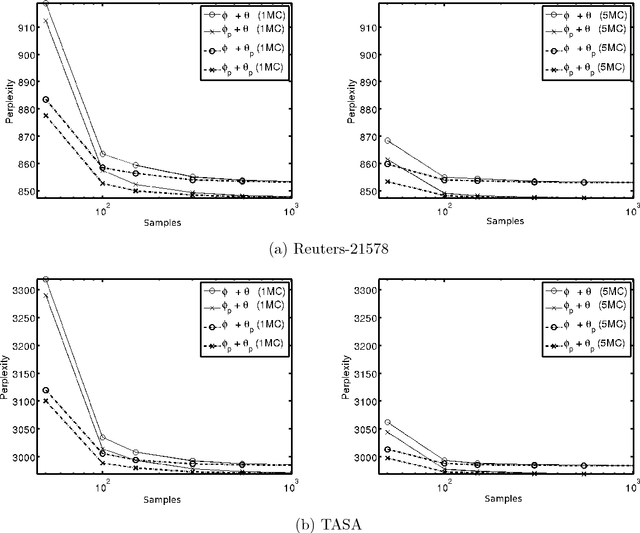
We introduce a novel approach for estimating Latent Dirichlet Allocation (LDA) parameters from collapsed Gibbs samples (CGS), by leveraging the full conditional distributions over the latent variable assignments to efficiently average over multiple samples, for little more computational cost than drawing a single additional collapsed Gibbs sample. Our approach can be understood as adapting the soft clustering methodology of Collapsed Variational Bayes (CVB0) to CGS parameter estimation, in order to get the best of both techniques. Our estimators can straightforwardly be applied to the output of any existing implementation of CGS, including modern accelerated variants. We perform extensive empirical comparisons of our estimators with those of standard collapsed inference algorithms on real-world data for both unsupervised LDA and Prior-LDA, a supervised variant of LDA for multi-label classification. Our results show a consistent advantage of our approach over traditional CGS under all experimental conditions, and over CVB0 inference in the majority of conditions. More broadly, our results highlight the importance of averaging over multiple samples in LDA parameter estimation, and the use of efficient computational techniques to do so.
Statistical Topic Models for Multi-Label Document Classification
Nov 10, 2011

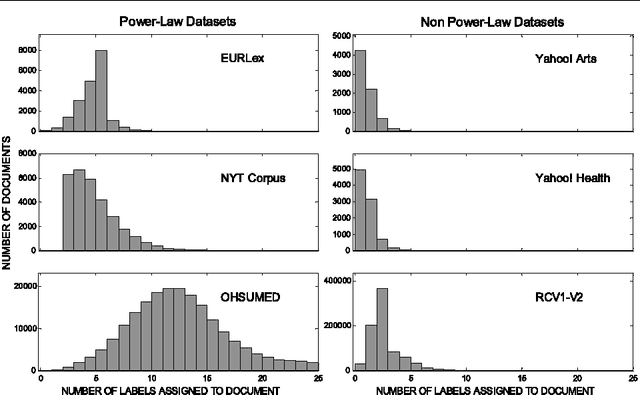

Machine learning approaches to multi-label document classification have to date largely relied on discriminative modeling techniques such as support vector machines. A drawback of these approaches is that performance rapidly drops off as the total number of labels and the number of labels per document increase. This problem is amplified when the label frequencies exhibit the type of highly skewed distributions that are often observed in real-world datasets. In this paper we investigate a class of generative statistical topic models for multi-label documents that associate individual word tokens with different labels. We investigate the advantages of this approach relative to discriminative models, particularly with respect to classification problems involving large numbers of relatively rare labels. We compare the performance of generative and discriminative approaches on document labeling tasks ranging from datasets with several thousand labels to datasets with tens of labels. The experimental results indicate that probabilistic generative models can achieve competitive multi-label classification performance compared to discriminative methods, and have advantages for datasets with many labels and skewed label frequencies.