 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscriptomics-based matching of drugs to diseases with deep learning
Mar 21, 2023In this work we present a deep learning approach to conduct hypothesis-free, transcriptomics-based matching of drugs for diseases. Our proposed neural network architecture is trained on approved drug-disease indications, taking as input the relevant disease and drug differential gene expression profiles, and learns to identify novel indications. We assemble an evaluation dataset of disease-drug indications spanning 68 diseases and evaluate in silico our approach against the most widely used transcriptomics-based matching baselines, CMap and the Characteristic Direction. Our results show a more than 200% improvement over both baselines in terms of standard retrieval metrics. We further showcase our model's ability to capture different genes' expressions interactions among drugs and diseases. We provide our trained models, data and code to predict with them at https://github.com/healx/dgem-nn-public.
Slot Filling for Biomedical Information Extraction
Sep 17, 2021

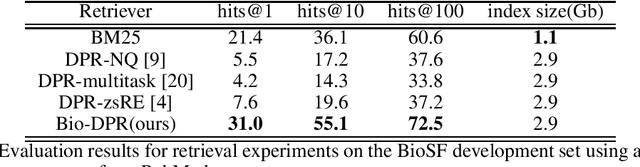
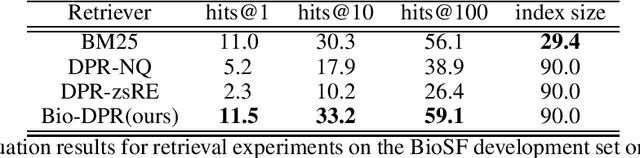
Information Extraction (IE) from text refers to the task of extracting structured knowledge from unstructured text. The task typically consists of a series of sub-tasks such as Named Entity Recognition and Relation Extraction. Sourcing entity and relation type specific training data is a major bottleneck in the above sub-tasks.In this work we present a slot filling approach to the task of biomedical IE, effectively replacing the need for entity and relation-specific training data, allowing to deal with zero-shot settings. We follow the recently proposed paradigm of coupling a Tranformer-based bi-encoder, Dense Passage Retrieval, with a Transformer-based reader model to extract relations from biomedical text. We assemble a biomedical slot filling dataset for both retrieval and reading comprehension and conduct a series of experiments demonstrating that our approach outperforms a number of simpler baselines. We also evaluate our approach end-to-end for standard as well as zero-shot settings. Our work provides a fresh perspective on how to solve biomedical IE tasks, in the absence of relevant training data. Our code, models and pretrained data are available at https://github.com/healx/biomed-slot-filling.
Teach me how to Label: Labeling Functions from Natural Language with Text-to-text Transformers
Jan 18, 2021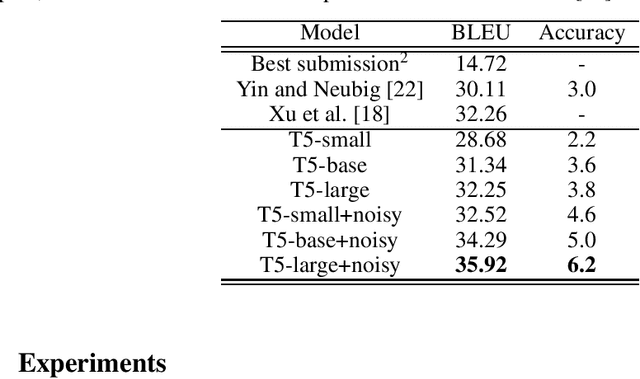
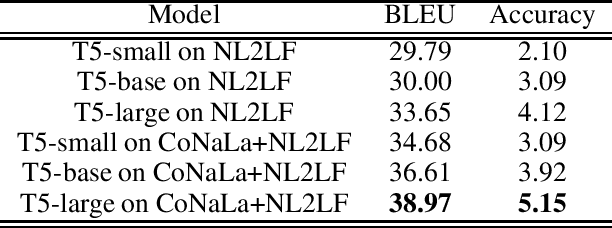
Annotated data has become the most important bottleneck in training accurate machine learning models, especially for areas that require domain expertise. A recent approach to deal with the above issue proposes using natural language explanations instead of labeling individual data points, thereby increasing human annotators' efficiency as well as decreasing costs substantially. This paper focuses on the task of turning these natural language descriptions into Python labeling functions by following a novel approach to semantic parsing with pre-trained text-to-text Transformers. In a series of experiments our approach achieves a new state of the art on the semantic parsing benchmark CoNaLa, surpassing the previous best approach by 3.7 BLEU points. Furthermore, on a manually constructed dataset of natural language descriptions-labeling functions pairs we achieve a BLEU of 0.39. Our approach can be regarded as a stepping stone towards models that are taught how to label in natural language, instead of being provided specific labeled samples. Our code, constructed dataset and models are available at https://github.com/ypapanik/t5-for-code-generation.
DARE: Data Augmented Relation Extraction with GPT-2
Apr 06, 2020
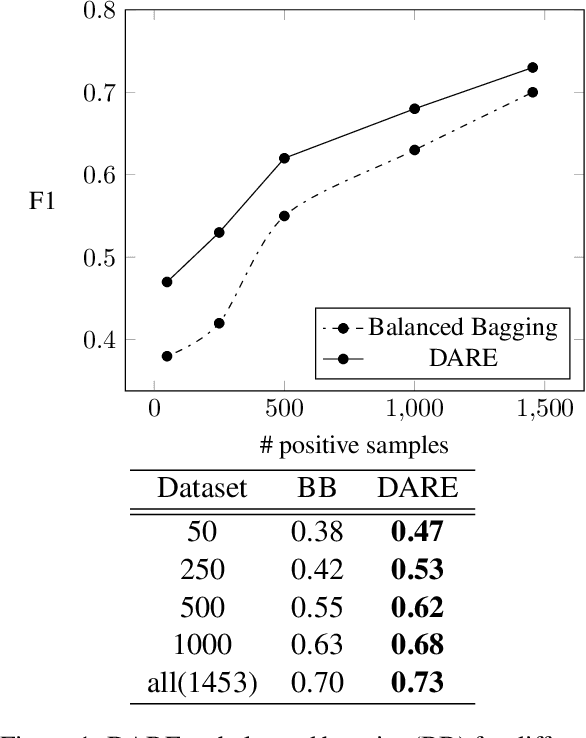

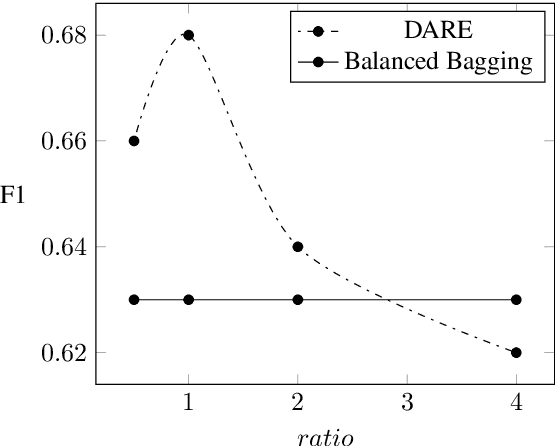
Real-world Relation Extraction (RE) tasks are challenging to deal with, either due to limited training data or class imbalance issues. In this work, we present Data Augmented Relation Extraction(DARE), a simple method to augment training data by properly fine-tuning GPT-2 to generate examples for specific relation types. The generated training data is then used in combination with the gold dataset to train a BERT-based RE classifier. In a series of experiments we show the advantages of our method, which leads in improvements of up to 11 F1 score points against a strong base-line. Also, DARE achieves new state of the art in three widely used biomedical RE datasets surpassing the previous best results by 4.7 F1 points on average.
Deep Bidirectional Transformers for Relation Extraction without Supervision
Nov 01, 2019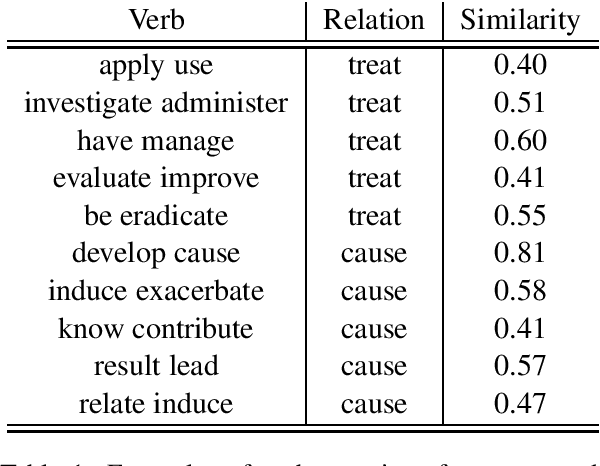
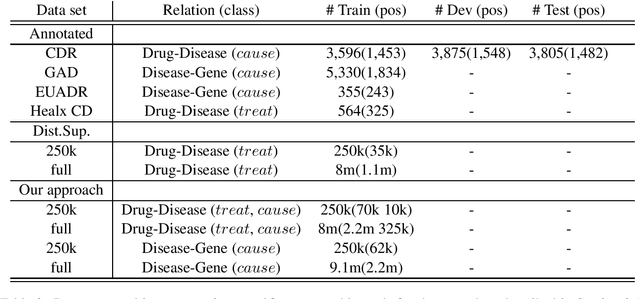
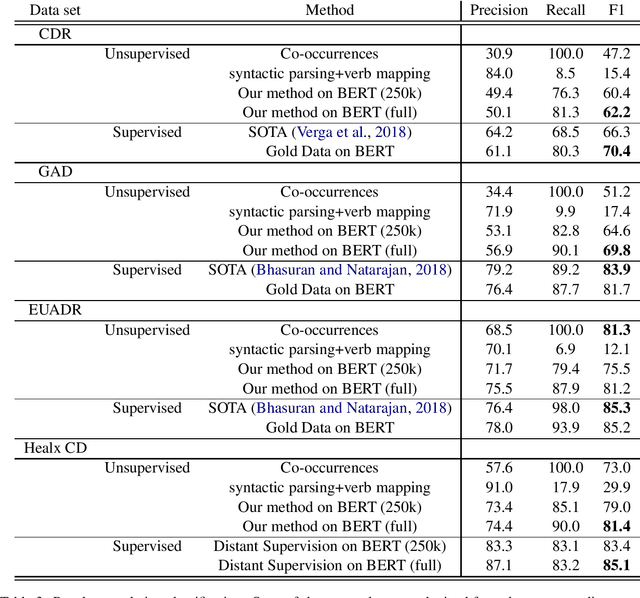
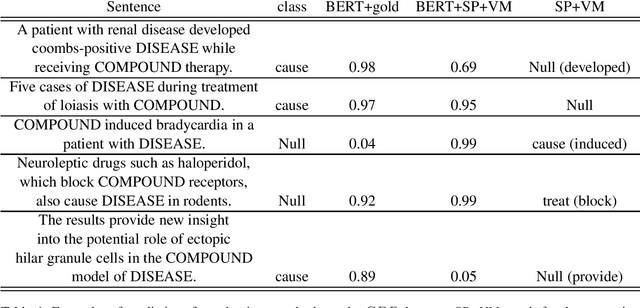
We present a novel framework to deal with relation extraction tasks in cases where there is complete lack of supervision, either in the form of gold annotations, or relations from a knowledge base. Our approach leverages syntactic parsing and pre-trained word embeddings to extract few but precise relations,which are then used to annotate a larger cor-pus, in a manner identical to distant supervision. The resulting data set is employed to fine tune a pre-trained BERT model in order to perform relation extraction. Empirical evaluation on four data sets from the biomedical domain shows that our method significantly outperforms two simple baselines for unsupervised relation extraction and, even if not using any supervision at all, achieves slightly worse results than the state-of-the-art in three out of four data sets. Importantly, we show that it is possible to successfully fine tune a large pre-trained language model with noisy data, as op-posed to previous works that rely on gold data for fine tuning.
Neural Embedding Allocation: Distributed Representations of Topic Models
Sep 10, 2019

Word embedding models such as the skip-gram learn vector representations of words' semantic relationships, and document embedding models learn similar representations for documents. On the other hand, topic models provide latent representations of the documents' topical themes. To get the benefits of these representations simultaneously, we propose a unifying algorithm, called neural embedding allocation (NEA), which deconstructs topic models into interpretable vector-space embeddings of words, topics, documents, authors, and so on, by learning neural embeddings to mimic the topic models. We showcase NEA's effectiveness and generality on LDA, author-topic models and the recently proposed mixed membership skip gram topic model and achieve better performance with the embeddings compared to several state-of-the-art models. Furthermore, we demonstrate that using NEA to smooth out the topics improves coherence scores over the original topic models when the number of topics is large.
Subset Labeled LDA for Large-Scale Multi-Label Classification
Sep 16, 2017
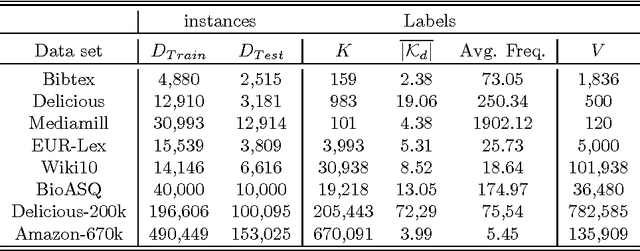
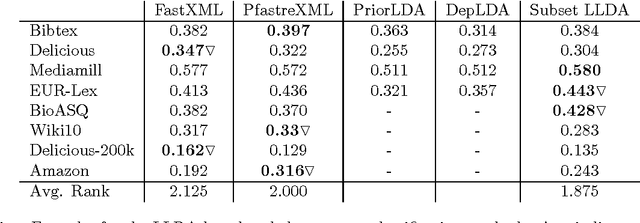
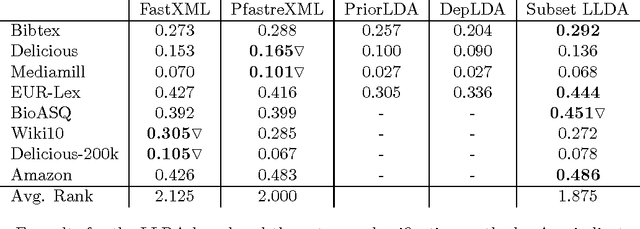
Labeled Latent Dirichlet Allocation (LLDA) is an extension of the standard unsupervised Latent Dirichlet Allocation (LDA) algorithm, to address multi-label learning tasks. Previous work has shown it to perform in par with other state-of-the-art multi-label methods. Nonetheless, with increasing label sets sizes LLDA encounters scalability issues. In this work, we introduce Subset LLDA, a simple variant of the standard LLDA algorithm, that not only can effectively scale up to problems with hundreds of thousands of labels but also improves over the LLDA state-of-the-art. We conduct extensive experiments on eight data sets, with label sets sizes ranging from hundreds to hundreds of thousands, comparing our proposed algorithm with the previously proposed LLDA algorithms (Prior--LDA, Dep--LDA), as well as the state of the art in extreme multi-label classification. The results show a steady advantage of our method over the other LLDA algorithms and competitive results compared to the extreme multi-label classification algorithms.
Large-Scale Online Semantic Indexing of Biomedical Articles via an Ensemble of Multi-Label Classification Models
Apr 18, 2017
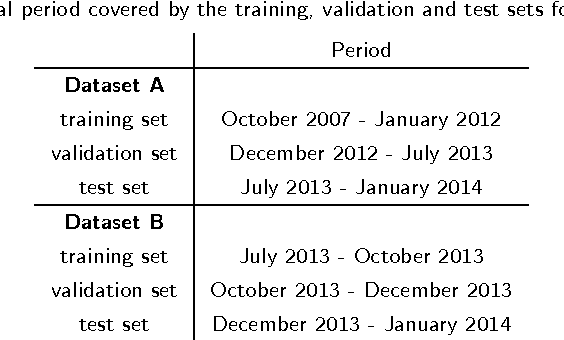
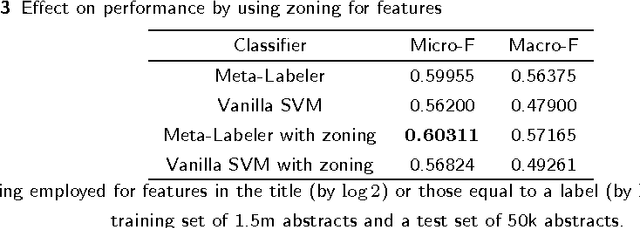
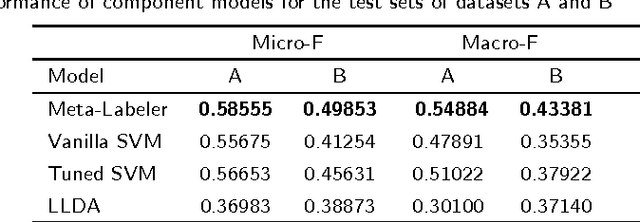
Background: In this paper we present the approaches and methods employed in order to deal with a large scale multi-label semantic indexing task of biomedical papers. This work was mainly implemented within the context of the BioASQ challenge of 2014. Methods: The main contribution of this work is a multi-label ensemble method that incorporates a McNemar statistical significance test in order to validate the combination of the constituent machine learning algorithms. Some secondary contributions include a study on the temporal aspects of the BioASQ corpus (observations apply also to the BioASQ's super-set, the PubMed articles collection) and the proper adaptation of the algorithms used to deal with this challenging classification task. Results: The ensemble method we developed is compared to other approaches in experimental scenarios with subsets of the BioASQ corpus giving positive results. During the BioASQ 2014 challenge we obtained the first place during the first batch and the third in the two following batches. Our success in the BioASQ challenge proved that a fully automated machine-learning approach, which does not implement any heuristics and rule-based approaches, can be highly competitive and outperform other approaches in similar challenging contexts.
Dense Distributions from Sparse Samples: Improved Gibbs Sampling Parameter Estimators for LDA
Apr 11, 2017
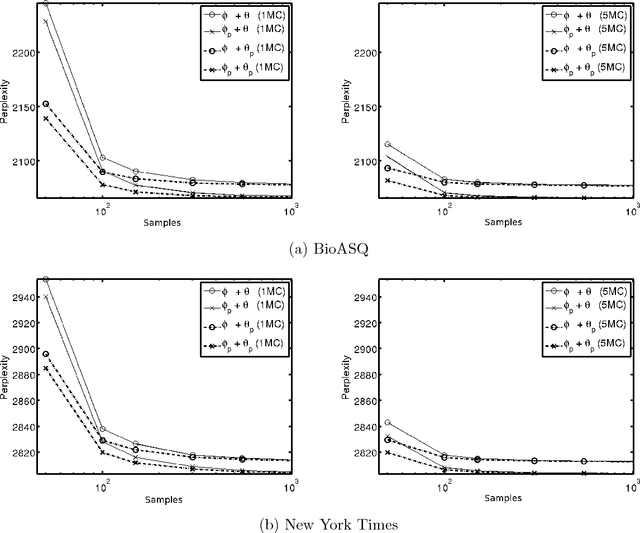

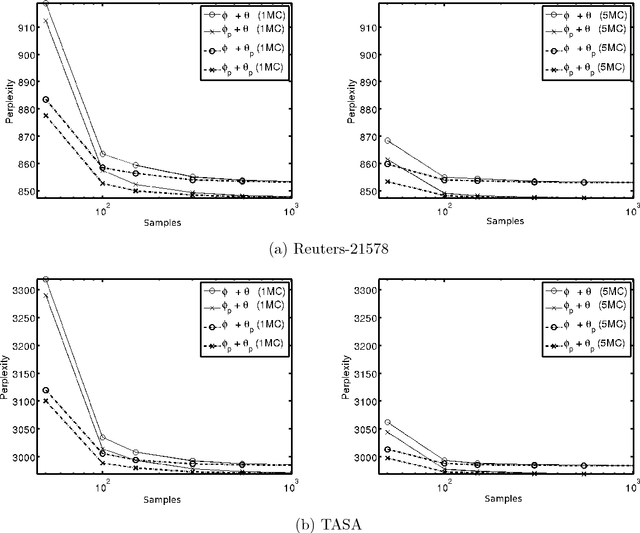
We introduce a novel approach for estimating Latent Dirichlet Allocation (LDA) parameters from collapsed Gibbs samples (CGS), by leveraging the full conditional distributions over the latent variable assignments to efficiently average over multiple samples, for little more computational cost than drawing a single additional collapsed Gibbs sample. Our approach can be understood as adapting the soft clustering methodology of Collapsed Variational Bayes (CVB0) to CGS parameter estimation, in order to get the best of both techniques. Our estimators can straightforwardly be applied to the output of any existing implementation of CGS, including modern accelerated variants. We perform extensive empirical comparisons of our estimators with those of standard collapsed inference algorithms on real-world data for both unsupervised LDA and Prior-LDA, a supervised variant of LDA for multi-label classification. Our results show a consistent advantage of our approach over traditional CGS under all experimental conditions, and over CVB0 inference in the majority of conditions. More broadly, our results highlight the importance of averaging over multiple samples in LDA parameter estimation, and the use of efficient computational techniques to do so.
Hierarchical Partitioning of the Output Space in Multi-label Data
Dec 19, 2016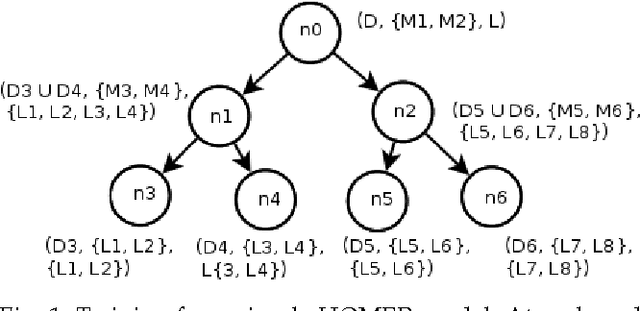

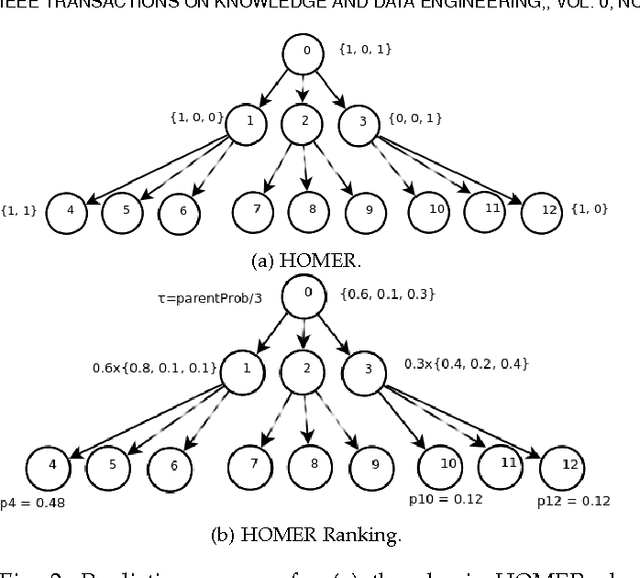
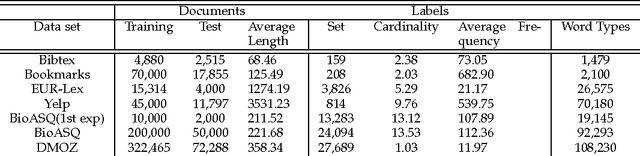
Hierarchy Of Multi-label classifiers (HOMER) is a multi-label learning algorithm that breaks the initial learning task to several, easier sub-tasks by first constructing a hierarchy of labels from a given label set and secondly employing a given base multi-label classifier (MLC) to the resulting sub-problems. The primary goal is to effectively address class imbalance and scalability issues that often arise in real-world multi-label classification problems. In this work, we present the general setup for a HOMER model and a simple extension of the algorithm that is suited for MLCs that output rankings. Furthermore, we provide a detailed analysis of the properties of the algorithm, both from an aspect of effectiveness and computational complexity. A secondary contribution involves the presentation of a balanced variant of the k means algorithm, which serves in the first step of the label hierarchy construction. We conduct extensive experiments on six real-world datasets, studying empirically HOMER's parameters and providing examples of instantiations of the algorithm with different clustering approaches and MLCs, The empirical results demonstrate a significant improvement over the given base MLC.