 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Browser-based Open Source Assistant for Multimodal Content Verification
Mar 03, 2026Disinformation and false content produced by generative AI pose a significant challenge for journalists and fact-checkers who must rapidly verify digital media information. While there is an abundance of NLP models for detecting credibility signals such as persuasion techniques, subjectivity, or machine-generated text, such methods often remain inaccessible to non-expert users and are not integrated into their daily workflows as a unified framework. This paper demonstrates the VERIFICATION ASSISTANT, a browser-based tool designed to bridge this gap. The VERIFICATION ASSISTANT, a core component of the widely adopted VERIFICATION PLUGIN (140,000+ users), allows users to submit URLs or media files to a unified interface. It automatically extracts content and routes it to a suite of backend NLP classifiers, delivering actionable credibility signals, estimating AI-generated content, and providing other verification guidance in a clear, easy-to-digest format. This paper showcases the tool architecture, its integration of multiple NLP services, and its real-world application to detecting disinformation.
Efficient Annotator Reliablity Assessment with EffiARA
Apr 01, 2025


Data annotation is an essential component of the machine learning pipeline; it is also a costly and time-consuming process. With the introduction of transformer-based models, annotation at the document level is increasingly popular; however, there is no standard framework for structuring such tasks. The EffiARA annotation framework is, to our knowledge, the first project to support the whole annotation pipeline, from understanding the resources required for an annotation task to compiling the annotated dataset and gaining insights into the reliability of individual annotators as well as the dataset as a whole. The framework's efficacy is supported by two previous studies: one improving classification performance through annotator-reliability-based soft label aggregation and sample weighting, and the other increasing the overall agreement among annotators through removing identifying and replacing an unreliable annotator. This work introduces the EffiARA Python package and its accompanying webtool, which provides an accessible graphical user interface for the system. We open-source the EffiARA Python package at https://github.com/MiniEggz/EffiARA and the webtool is publicly accessible at https://effiara.gate.ac.uk.
Towards an Interoperable Ecosystem of AI and LT Platforms: A Roadmap for the Implementation of Different Levels of Interoperability
Apr 17, 2020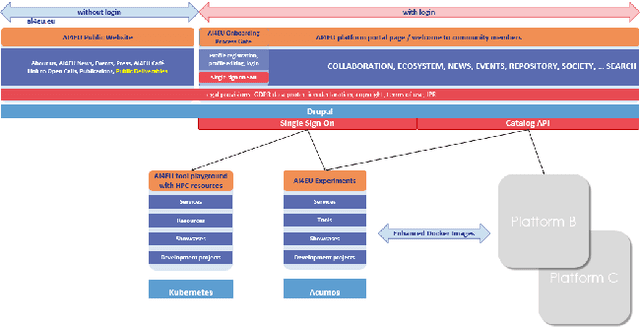
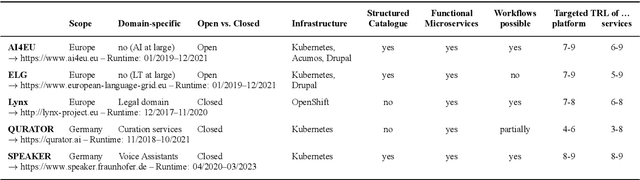

With regard to the wider area of AI/LT platform interoperability, we concentrate on two core aspects: (1) cross-platform search and discovery of resources and services; (2) composition of cross-platform service workflows. We devise five different levels (of increasing complexity) of platform interoperability that we suggest to implement in a wider federation of AI/LT platforms. We illustrate the approach using the five emerging AI/LT platforms AI4EU, ELG, Lynx, QURATOR and SPEAKER.
European Language Grid: An Overview
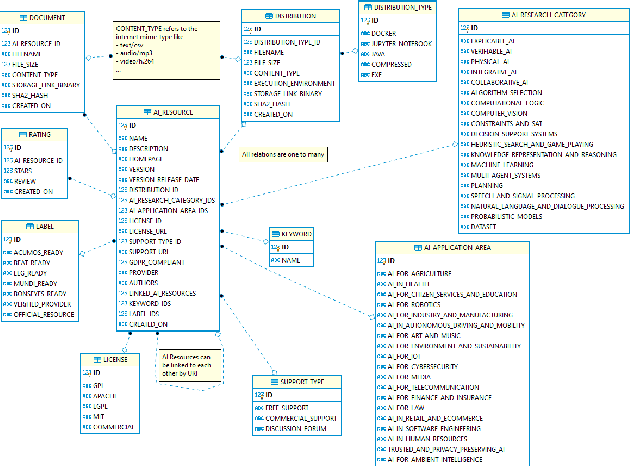
Mar 30, 2020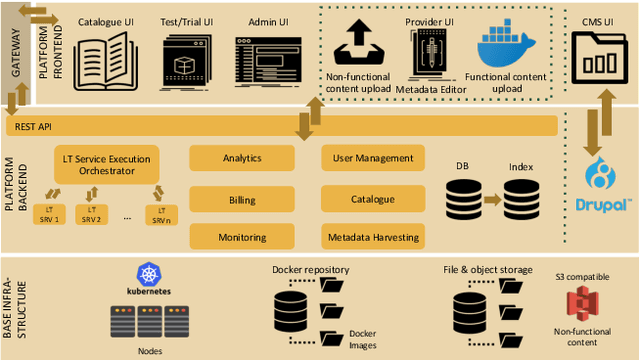

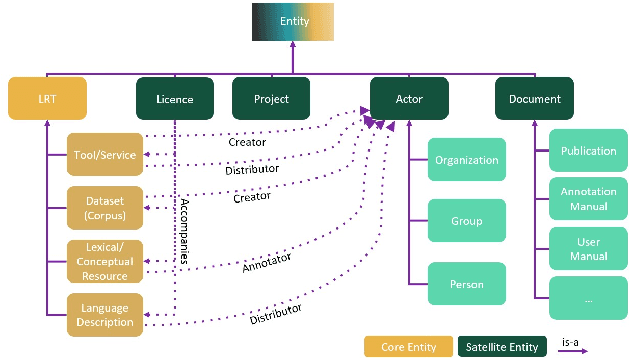
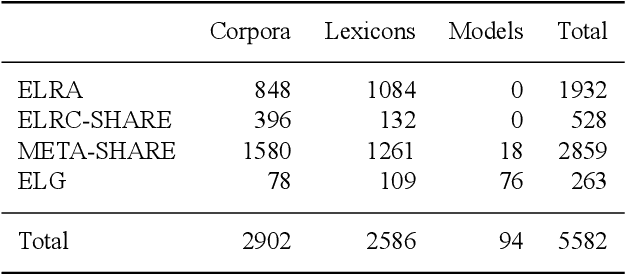
With 24 official EU and many additional languages, multilingualism in Europe and an inclusive Digital Single Market can only be enabled through Language Technologies (LTs). European LT business is dominated by hundreds of SMEs and a few large players. Many are world-class, with technologies that outperform the global players. However, European LT business is also fragmented, by nation states, languages, verticals and sectors, significantly holding back its impact. The European Language Grid (ELG) project addresses this fragmentation by establishing the ELG as the primary platform for LT in Europe. The ELG is a scalable cloud platform, providing, in an easy-to-integrate way, access to hundreds of commercial and non-commercial LTs for all European languages, including running tools and services as well as data sets and resources. Once fully operational, it will enable the commercial and non-commercial European LT community to deposit and upload their technologies and data sets into the ELG, to deploy them through the grid, and to connect with other resources. The ELG will boost the Multilingual Digital Single Market towards a thriving European LT community, creating new jobs and opportunities. Furthermore, the ELG project organises two open calls for up to 20 pilot projects. It also sets up 32 National Competence Centres (NCCs) and the European LT Council (LTC) for outreach and coordination purposes.
Reasoning Over Paths via Knowledge Base Completion
Nov 01, 2019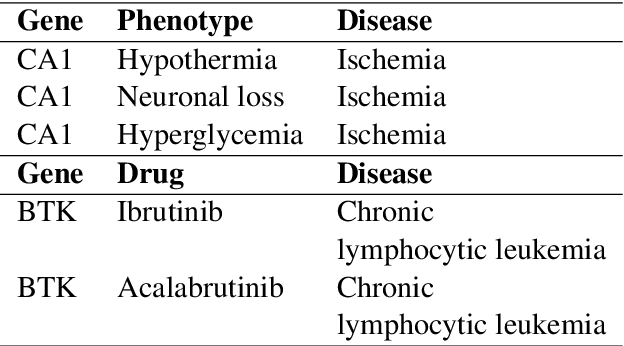
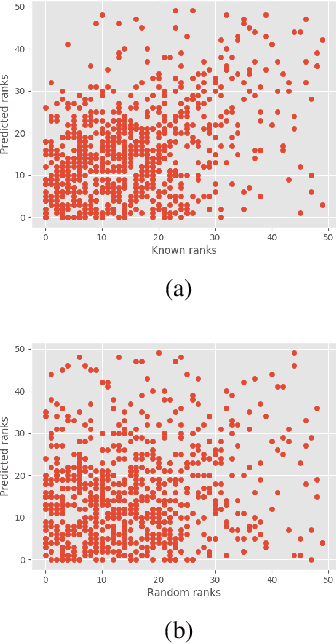
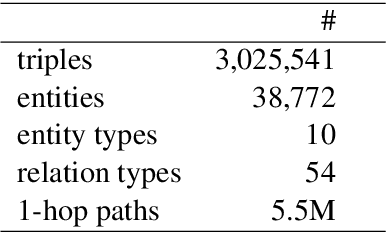

Reasoning over paths in large scale knowledge graphs is an important problem for many applications. In this paper we discuss a simple approach to automatically build and rank paths between a source and target entity pair with learned embeddings using a knowledge base completion model (KBC). We assembled a knowledge graph by mining the available biomedical scientific literature and extracted a set of high frequency paths to use for validation. We demonstrate that our method is able to effectively rank a list of known paths between a pair of entities and also come up with plausible paths that are not present in the knowledge graph. For a given entity pair we are able to reconstruct the highest ranking path 60% of the time within the the top 10 ranked paths and achieve 49% mean average precision. Our approach is compositional since any KBC model that can produce vector representations of entities can be used.
Deep Bidirectional Transformers for Relation Extraction without Supervision
Nov 01, 2019
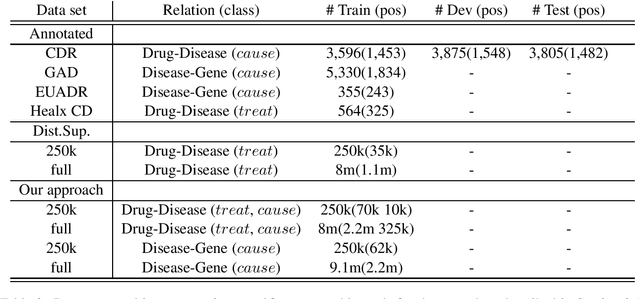
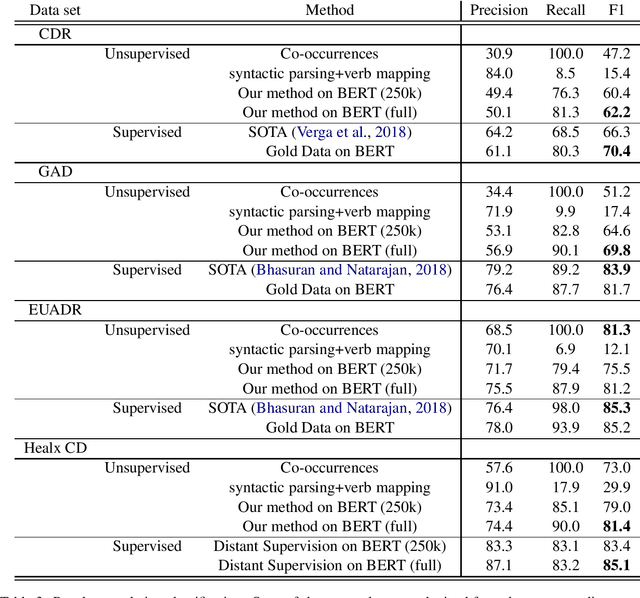
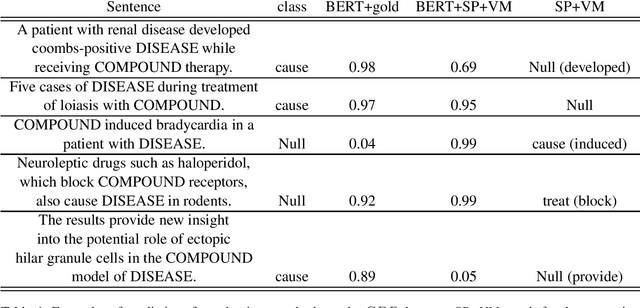
We present a novel framework to deal with relation extraction tasks in cases where there is complete lack of supervision, either in the form of gold annotations, or relations from a knowledge base. Our approach leverages syntactic parsing and pre-trained word embeddings to extract few but precise relations,which are then used to annotate a larger cor-pus, in a manner identical to distant supervision. The resulting data set is employed to fine tune a pre-trained BERT model in order to perform relation extraction. Empirical evaluation on four data sets from the biomedical domain shows that our method significantly outperforms two simple baselines for unsupervised relation extraction and, even if not using any supervision at all, achieves slightly worse results than the state-of-the-art in three out of four data sets. Importantly, we show that it is possible to successfully fine tune a large pre-trained language model with noisy data, as op-posed to previous works that rely on gold data for fine tuning.