 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Detection of Salvin's Albatrosses: Improving Deep Learning Tools for Aerial Wildlife Surveys
May 15, 2025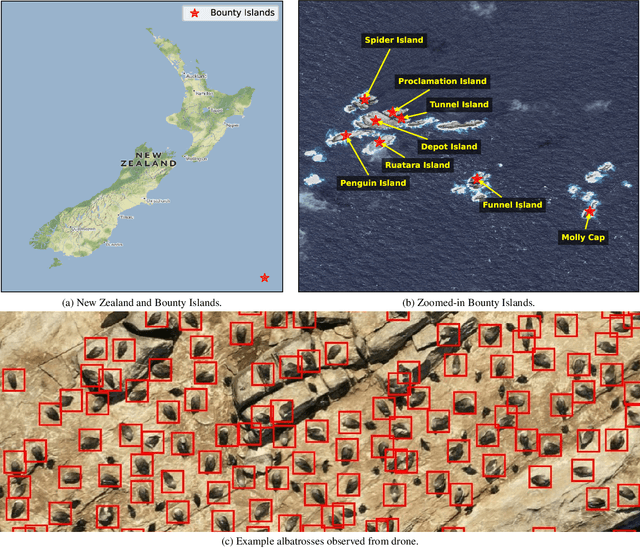


Recent advancements in deep learning and aerial imaging have transformed wildlife monitoring, enabling researchers to survey wildlife populations at unprecedented scales. Unmanned Aerial Vehicles (UAVs) provide a cost-effective means of capturing high-resolution imagery, particularly for monitoring densely populated seabird colonies. In this study, we assess the performance of a general-purpose avian detection model, BirdDetector, in estimating the breeding population of Salvin's albatross (Thalassarche salvini) on the Bounty Islands, New Zealand. Using drone-derived imagery, we evaluate the model's effectiveness in both zero-shot and fine-tuned settings, incorporating enhanced inference techniques and stronger augmentation methods. Our findings indicate that while applying the model in a zero-shot setting offers a strong baseline, fine-tuning with annotations from the target domain and stronger image augmentation leads to marked improvements in detection accuracy. These results highlight the potential of leveraging pre-trained deep-learning models for species-specific monitoring in remote and challenging environments.
ConstrainedZero: Chance-Constrained POMDP Planning using Learned Probabilistic Failure Surrogates and Adaptive Safety Constraints
May 01, 2024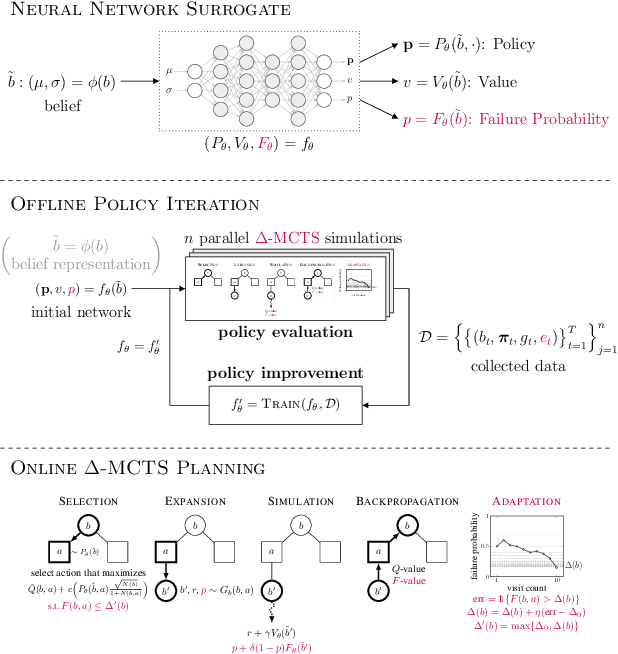
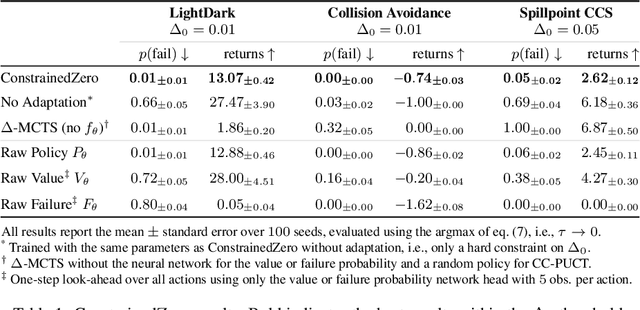
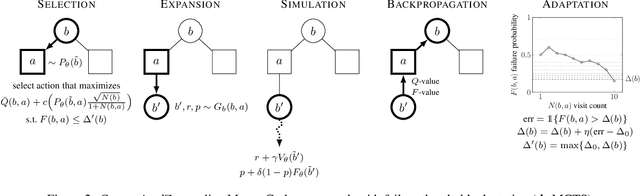

To plan safely in uncertain environments, agents must balance utility with safety constraints. Safe planning problems can be modeled as a chance-constrained partially observable Markov decision process (CC-POMDP) and solutions often use expensive rollouts or heuristics to estimate the optimal value and action-selection policy. This work introduces the ConstrainedZero policy iteration algorithm that solves CC-POMDPs in belief space by learning neural network approximations of the optimal value and policy with an additional network head that estimates the failure probability given a belief. This failure probability guides safe action selection during online Monte Carlo tree search (MCTS). To avoid overemphasizing search based on the failure estimates, we introduce $\Delta$-MCTS, which uses adaptive conformal inference to update the failure threshold during planning. The approach is tested on a safety-critical POMDP benchmark, an aircraft collision avoidance system, and the sustainability problem of safe CO$_2$ storage. Results show that by separating safety constraints from the objective we can achieve a target level of safety without optimizing the balance between rewards and costs.
ZigMa: Zigzag Mamba Diffusion Model
Mar 20, 2024



The diffusion model has long been plagued by scalability and quadratic complexity issues, especially within transformer-based structures. In this study, we aim to leverage the long sequence modeling capability of a State-Space Model called Mamba to extend its applicability to visual data generation. Firstly, we identify a critical oversight in most current Mamba-based vision methods, namely the lack of consideration for spatial continuity in the scan scheme of Mamba. Secondly, building upon this insight, we introduce a simple, plug-and-play, zero-parameter method named Zigzag Mamba, which outperforms Mamba-based baselines and demonstrates improved speed and memory utilization compared to transformer-based baselines. Lastly, we integrate Zigzag Mamba with the Stochastic Interpolant framework to investigate the scalability of the model on large-resolution visual datasets, such as FacesHQ $1024\times 1024$ and UCF101, MultiModal-CelebA-HQ, and MS COCO $256\times 256$. Code will be released at https://taohu.me/zigma/
PITA: Physics-Informed Trajectory Autoencoder
Mar 18, 2024Validating robotic systems in safety-critical appli-cations requires testing in many scenarios including rare edgecases that are unlikely to occur, requiring to complement real-world testing with testing in simulation. Generative models canbe used to augment real-world datasets with generated data toproduce edge case scenarios by sampling in a learned latentspace. Autoencoders can learn said latent representation for aspecific domain by learning to reconstruct the input data froma lower-dimensional intermediate representation. However, theresulting trajectories are not necessarily physically plausible, butinstead typically contain noise that is not present in the inputtrajectory. To resolve this issue, we propose the novel Physics-Informed Trajectory Autoencoder (PITA) architecture, whichincorporates a physical dynamics model into the loss functionof the autoencoder. This results in smooth trajectories that notonly reconstruct the input trajectory but also adhere to thephysical model. We evaluate PITA on a real-world dataset ofvehicle trajectories and compare its performance to a normalautoencoder and a state-of-the-art action-space autoencoder.
Launch Power Optimization for Dynamic Elastic Optical Networks over C+L Bands
Aug 25, 2023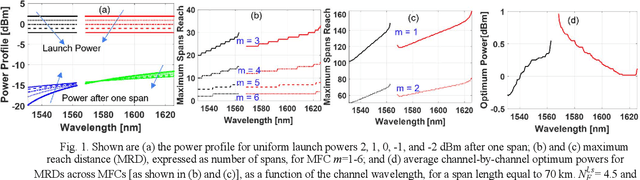


We propose an algorithm for calculating the optimum launch power over the entire C+L bands by maximizing the cumulative link GSNR of a channel plan built upon multiple modulation formats, with application to dynamic EONs. Exact last-fit spectrum assignment proves to outperform exact first-fit in terms of average GSNR at arrival time.
SHAIL: Safety-Aware Hierarchical Adversarial Imitation Learning for Autonomous Driving in Urban Environments
Apr 05, 2022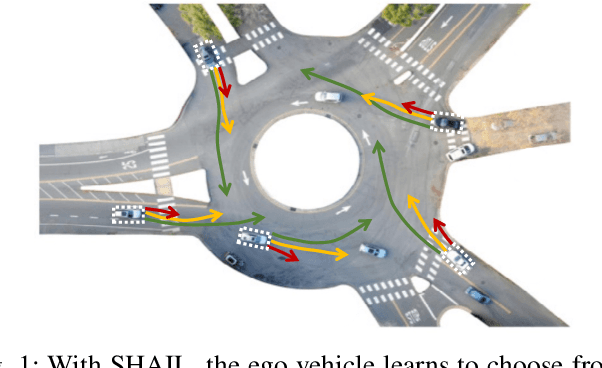
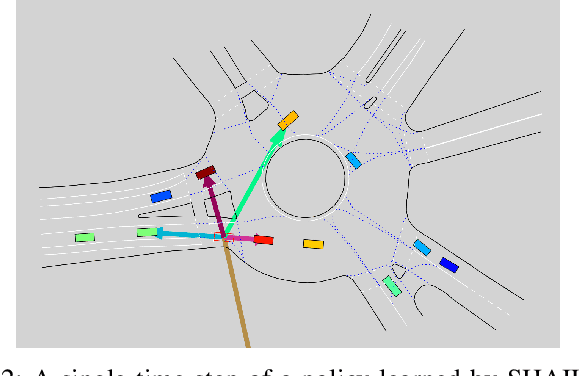
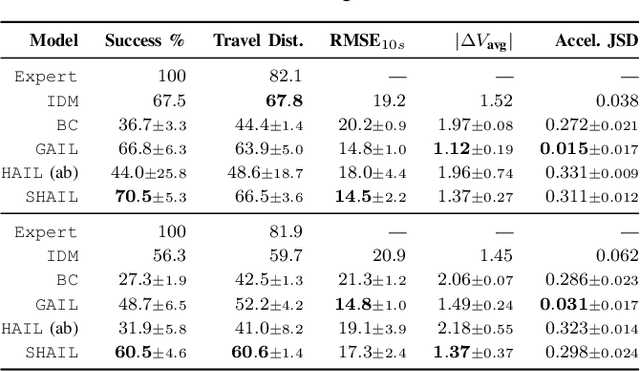
Designing a safe and human-like decision-making system for an autonomous vehicle is a challenging task. Generative imitation learning is one possible approach for automating policy-building by leveraging both real-world and simulated decisions. Previous work that applies generative imitation learning to autonomous driving policies focuses on learning a low-level controller for simple settings. However, to scale to complex settings, many autonomous driving systems combine fixed, safe, optimization-based low-level controllers with high-level decision-making logic that selects the appropriate task and associated controller. In this paper, we attempt to bridge this gap in complexity by employing Safety-Aware Hierarchical Adversarial Imitation Learning (SHAIL), a method for learning a high-level policy that selects from a set of low-level controller instances in a way that imitates low-level driving data on-policy. We introduce an urban roundabout simulator that controls non-ego vehicles using real data from the Interaction dataset. We then show empirically that our approach can produce better behavior than previous approaches in driver imitation which have difficulty scaling to complex environments. Our implementation is available at https://github.com/sisl/InteractionImitation.
Minimizing Safety Interference for Safe and Comfortable Automated Driving with Distributional Reinforcement Learning
Jul 15, 2021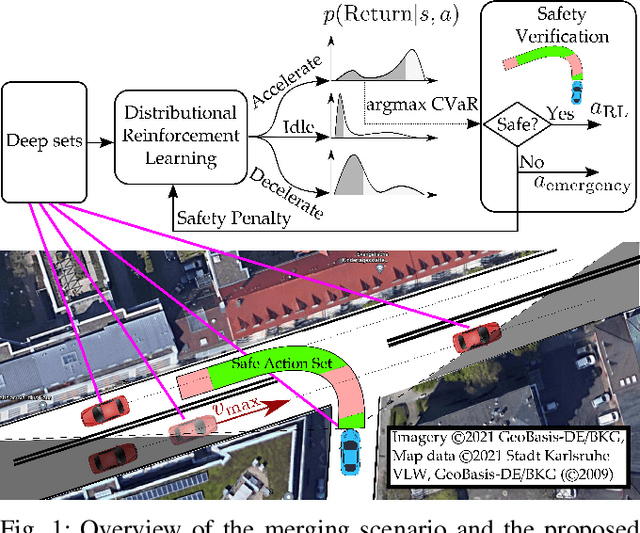
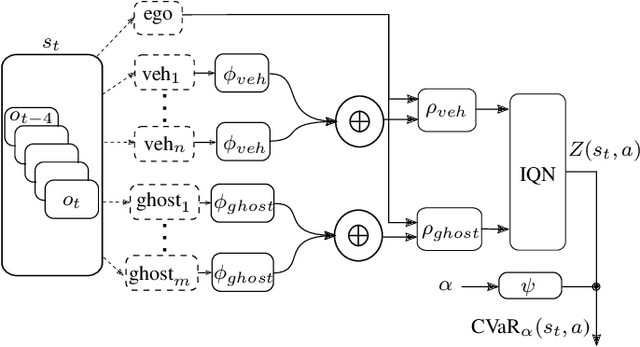
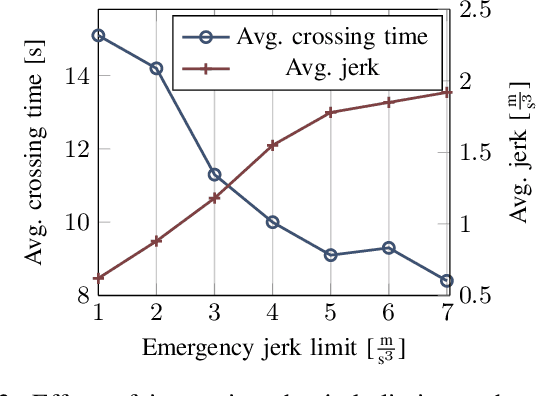
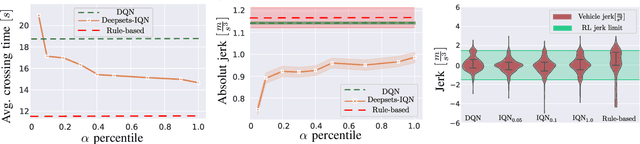
Despite recent advances in reinforcement learning (RL), its application in safety critical domains like autonomous vehicles is still challenging. Although punishing RL agents for risky situations can help to learn safe policies, it may also lead to highly conservative behavior. In this paper, we propose a distributional RL framework in order to learn adaptive policies that can tune their level of conservativity at run-time based on the desired comfort and utility. Using a proactive safety verification approach, the proposed framework can guarantee that actions generated from RL are fail-safe according to the worst-case assumptions. Concurrently, the policy is encouraged to minimize safety interference and generate more comfortable behavior. We trained and evaluated the proposed approach and baseline policies using a high level simulator with a variety of randomized scenarios including several corner cases which rarely happen in reality but are very crucial. In light of our experiments, the behavior of policies learned using distributional RL can be adaptive at run-time and robust to the environment uncertainty. Quantitatively, the learned distributional RL agent drives in average 8 seconds faster than the normal DQN policy and requires 83\% less safety interference compared to the rule-based policy with slightly increasing the average crossing time. We also study sensitivity of the learned policy in environments with higher perception noise and show that our algorithm learns policies that can still drive reliable when the perception noise is two times higher than the training configuration for automated merging and crossing at occluded intersections.
Towards an Interoperable Ecosystem of AI and LT Platforms: A Roadmap for the Implementation of Different Levels of Interoperability
Apr 17, 2020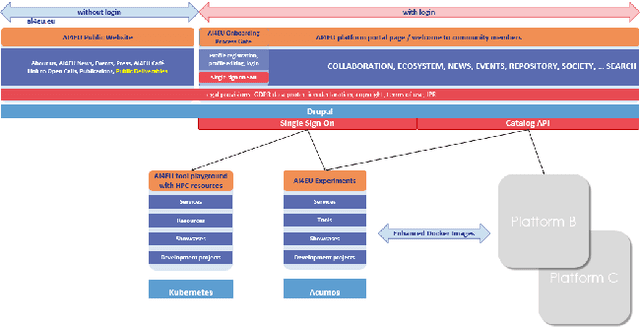
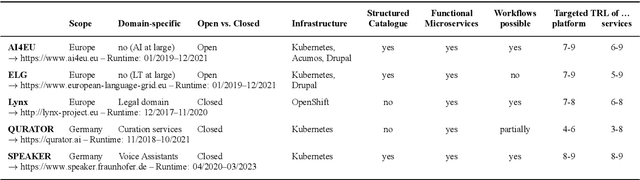
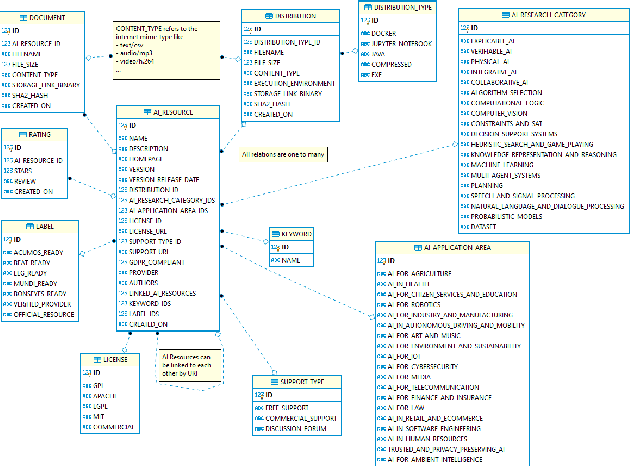

With regard to the wider area of AI/LT platform interoperability, we concentrate on two core aspects: (1) cross-platform search and discovery of resources and services; (2) composition of cross-platform service workflows. We devise five different levels (of increasing complexity) of platform interoperability that we suggest to implement in a wider federation of AI/LT platforms. We illustrate the approach using the five emerging AI/LT platforms AI4EU, ELG, Lynx, QURATOR and SPEAKER.