 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Token-Sparse Diffusion Models
Jan 04, 2026Diffusion models deliver high quality in image synthesis but remain expensive during training and inference. Recent works have leveraged the inherent redundancy in visual content to make training more affordable by training only on a subset of visual information. While these methods were successful in providing cheaper and more effective training, sparsely trained diffusion models struggle in inference. This is due to their lacking response to Classifier-free Guidance (CFG) leading to underwhelming performance during inference. To overcome this, we propose Sparse Guidance (SG). Instead of using conditional dropout as a signal to guide diffusion models, SG uses token-level sparsity. As a result, SG preserves the high-variance of the conditional prediction better, achieving good quality and high variance outputs. Leveraging token-level sparsity at inference, SG improves fidelity at lower compute, achieving 1.58 FID on the commonly used ImageNet-256 benchmark with 25% fewer FLOPs, and yields up to 58% FLOP savings at matched baseline quality. To demonstrate the effectiveness of Sparse Guidance, we train a 2.5B text-to-image diffusion model using training time sparsity and leverage SG during inference. SG achieves improvements in composition and human preference score while increasing throughput at the same time.
Diffusion Models and Representation Learning: A Survey
Jun 30, 2024


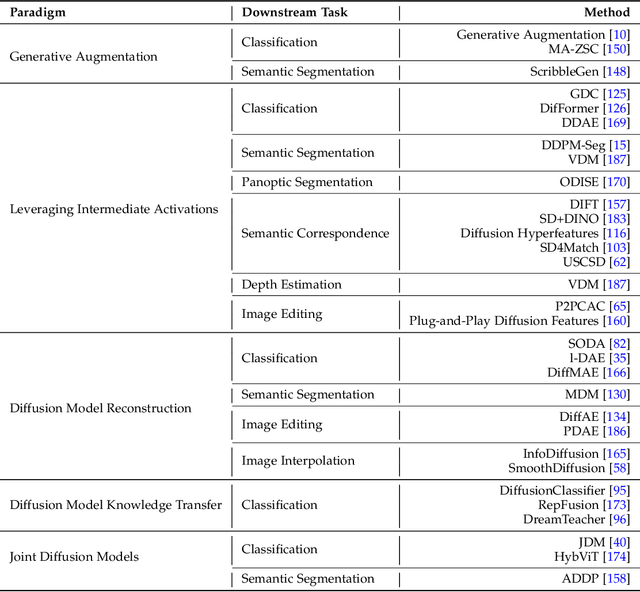
Diffusion Models are popular generative modeling methods in various vision tasks, attracting significant attention. They can be considered a unique instance of self-supervised learning methods due to their independence from label annotation. This survey explores the interplay between diffusion models and representation learning. It provides an overview of diffusion models' essential aspects, including mathematical foundations, popular denoising network architectures, and guidance methods. Various approaches related to diffusion models and representation learning are detailed. These include frameworks that leverage representations learned from pre-trained diffusion models for subsequent recognition tasks and methods that utilize advancements in representation and self-supervised learning to enhance diffusion models. This survey aims to offer a comprehensive overview of the taxonomy between diffusion models and representation learning, identifying key areas of existing concerns and potential exploration. Github link: https://github.com/dongzhuoyao/Diffusion-Representation-Learning-Survey-Taxonomy
DepthFM: Fast Monocular Depth Estimation with Flow Matching
Mar 20, 2024



Monocular depth estimation is crucial for numerous downstream vision tasks and applications. Current discriminative approaches to this problem are limited due to blurry artifacts, while state-of-the-art generative methods suffer from slow sampling due to their SDE nature. Rather than starting from noise, we seek a direct mapping from input image to depth map. We observe that this can be effectively framed using flow matching, since its straight trajectories through solution space offer efficiency and high quality. Our study demonstrates that a pre-trained image diffusion model can serve as an adequate prior for a flow matching depth model, allowing efficient training on only synthetic data to generalize to real images. We find that an auxiliary surface normals loss further improves the depth estimates. Due to the generative nature of our approach, our model reliably predicts the confidence of its depth estimates. On standard benchmarks of complex natural scenes, our lightweight approach exhibits state-of-the-art performance at favorable low computational cost despite only being trained on little synthetic data.
ZigMa: Zigzag Mamba Diffusion Model
Mar 20, 2024



The diffusion model has long been plagued by scalability and quadratic complexity issues, especially within transformer-based structures. In this study, we aim to leverage the long sequence modeling capability of a State-Space Model called Mamba to extend its applicability to visual data generation. Firstly, we identify a critical oversight in most current Mamba-based vision methods, namely the lack of consideration for spatial continuity in the scan scheme of Mamba. Secondly, building upon this insight, we introduce a simple, plug-and-play, zero-parameter method named Zigzag Mamba, which outperforms Mamba-based baselines and demonstrates improved speed and memory utilization compared to transformer-based baselines. Lastly, we integrate Zigzag Mamba with the Stochastic Interpolant framework to investigate the scalability of the model on large-resolution visual datasets, such as FacesHQ $1024\times 1024$ and UCF101, MultiModal-CelebA-HQ, and MS COCO $256\times 256$. Code will be released at https://taohu.me/zigma/
Boosting Latent Diffusion with Flow Matching
Dec 12, 2023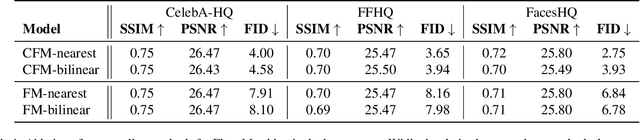


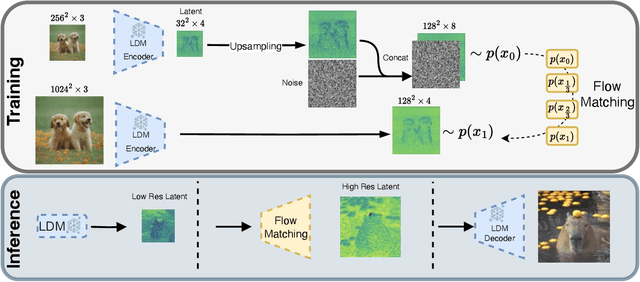
Recently, there has been tremendous progress in visual synthesis and the underlying generative models. Here, diffusion models (DMs) stand out particularly, but lately, flow matching (FM) has also garnered considerable interest. While DMs excel in providing diverse images, they suffer from long training and slow generation. With latent diffusion, these issues are only partially alleviated. Conversely, FM offers faster training and inference but exhibits less diversity in synthesis. We demonstrate that introducing FM between the Diffusion model and the convolutional decoder offers high-resolution image synthesis with reduced computational cost and model size. Diffusion can then efficiently provide the necessary generation diversity. FM compensates for the lower resolution, mapping the small latent space to a high-dimensional one. Subsequently, the convolutional decoder of the LDM maps these latents to high-resolution images. By combining the diversity of DMs, the efficiency of FMs, and the effectiveness of convolutional decoders, we achieve state-of-the-art high-resolution image synthesis at $1024^2$ with minimal computational cost. Importantly, our approach is orthogonal to recent approximation and speed-up strategies for the underlying DMs, making it easily integrable into various DM frameworks.