 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Token-Sparse Diffusion Models
Jan 04, 2026Diffusion models deliver high quality in image synthesis but remain expensive during training and inference. Recent works have leveraged the inherent redundancy in visual content to make training more affordable by training only on a subset of visual information. While these methods were successful in providing cheaper and more effective training, sparsely trained diffusion models struggle in inference. This is due to their lacking response to Classifier-free Guidance (CFG) leading to underwhelming performance during inference. To overcome this, we propose Sparse Guidance (SG). Instead of using conditional dropout as a signal to guide diffusion models, SG uses token-level sparsity. As a result, SG preserves the high-variance of the conditional prediction better, achieving good quality and high variance outputs. Leveraging token-level sparsity at inference, SG improves fidelity at lower compute, achieving 1.58 FID on the commonly used ImageNet-256 benchmark with 25% fewer FLOPs, and yields up to 58% FLOP savings at matched baseline quality. To demonstrate the effectiveness of Sparse Guidance, we train a 2.5B text-to-image diffusion model using training time sparsity and leverage SG during inference. SG achieves improvements in composition and human preference score while increasing throughput at the same time.
Purrception: Variational Flow Matching for Vector-Quantized Image Generation
Oct 01, 2025



We introduce Purrception, a variational flow matching approach for vector-quantized image generation that provides explicit categorical supervision while maintaining continuous transport dynamics. Our method adapts Variational Flow Matching to vector-quantized latents by learning categorical posteriors over codebook indices while computing velocity fields in the continuous embedding space. This combines the geometric awareness of continuous methods with the discrete supervision of categorical approaches, enabling uncertainty quantification over plausible codes and temperature-controlled generation. We evaluate Purrception on ImageNet-1k 256x256 generation. Training converges faster than both continuous flow matching and discrete flow matching baselines while achieving competitive FID scores with state-of-the-art models. This demonstrates that Variational Flow Matching can effectively bridge continuous transport and discrete supervision for improved training efficiency in image generation.
TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training
Jan 08, 2025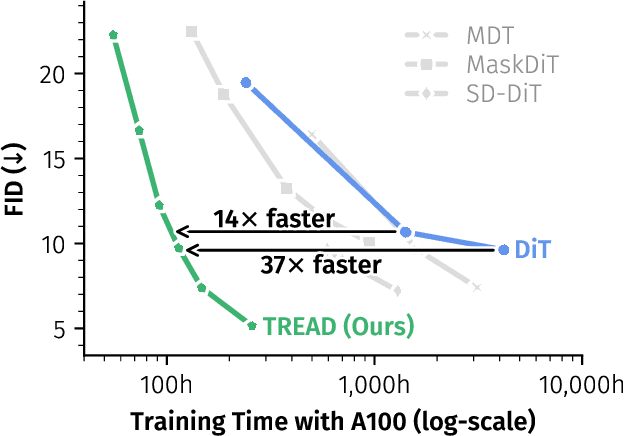
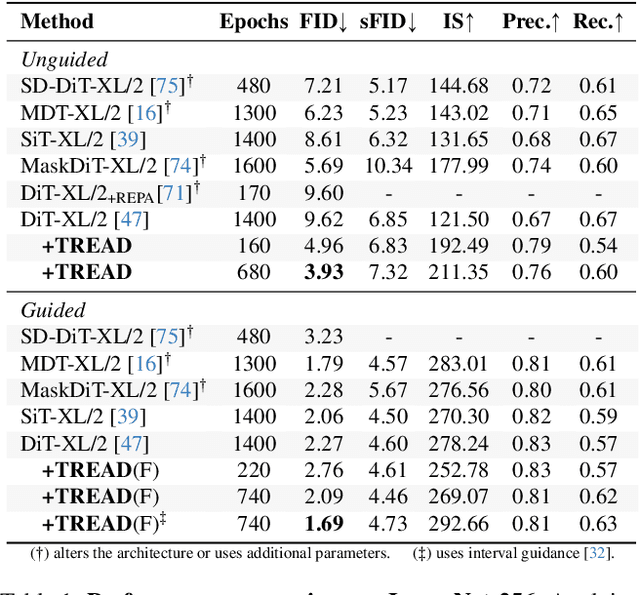

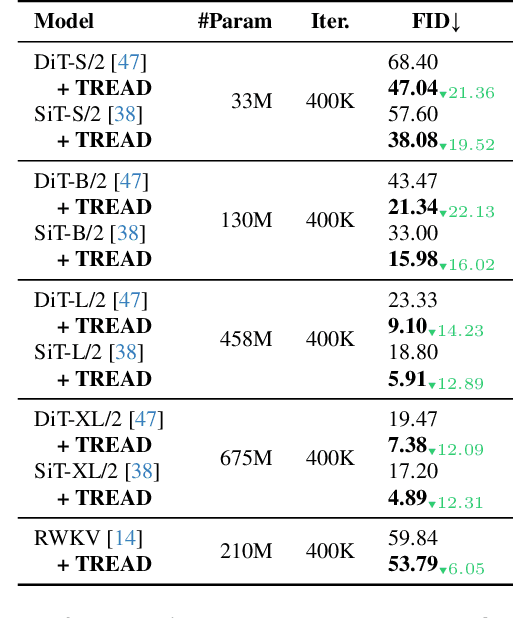
Diffusion models have emerged as the mainstream approach for visual generation. However, these models usually suffer from sample inefficiency and high training costs. This issue is particularly pronounced in the standard diffusion transformer architecture due to its quadratic complexity relative to input length. Recent works have addressed this by reducing the number of tokens processed in the model, often through masking. In contrast, this work aims to improve the training efficiency of the diffusion backbone by using predefined routes that store this information until it is reintroduced to deeper layers of the model, rather than discarding these tokens entirely. Further, we combine multiple routes and introduce an adapted auxiliary loss that accounts for all applied routes. Our method is not limited to the common transformer-based model - it can also be applied to state-space models. Unlike most current approaches, TREAD achieves this without architectural modifications. Finally, we show that our method reduces the computational cost and simultaneously boosts model performance on the standard benchmark ImageNet-1K 256 x 256 in class-conditional synthesis. Both of these benefits multiply to a convergence speedup of 9.55x at 400K training iterations compared to DiT and 25.39x compared to the best benchmark performance of DiT at 7M training iterations.
Does VLM Classification Benefit from LLM Description Semantics?
Dec 16, 2024



Accurately describing images via text is a foundation of explainable AI. Vision-Language Models (VLMs) like CLIP have recently addressed this by aligning images and texts in a shared embedding space, expressing semantic similarities between vision and language embeddings. VLM classification can be improved with descriptions generated by Large Language Models (LLMs). However, it is difficult to determine the contribution of actual description semantics, as the performance gain may also stem from a semantic-agnostic ensembling effect. Considering this, we ask how to distinguish the actual discriminative power of descriptions from performance boosts that potentially rely on an ensembling effect. To study this, we propose an alternative evaluation scenario that shows a characteristic behavior if the used descriptions have discriminative power. Furthermore, we propose a training-free method to select discriminative descriptions that work independently of classname ensembling effects. The training-free method works in the following way: A test image has a local CLIP label neighborhood, i.e., its top-$k$ label predictions. Then, w.r.t. to a small selection set, we extract descriptions that distinguish each class well in the local neighborhood. Using the selected descriptions, we demonstrate improved classification accuracy across seven datasets and provide in-depth analysis and insights into the explainability of description-based image classification by VLMs.
[MASK] is All You Need
Dec 10, 2024In generative models, two paradigms have gained attraction in various applications: next-set prediction-based Masked Generative Models and next-noise prediction-based Non-Autoregressive Models, e.g., Diffusion Models. In this work, we propose using discrete-state models to connect them and explore their scalability in the vision domain. First, we conduct a step-by-step analysis in a unified design space across two types of models including timestep-independence, noise schedule, temperature, guidance strength, etc in a scalable manner. Second, we re-cast typical discriminative tasks, e.g., image segmentation, as an unmasking process from [MASK] tokens on a discrete-state model. This enables us to perform various sampling processes, including flexible conditional sampling by only training once to model the joint distribution. All aforementioned explorations lead to our framework named Discrete Interpolants, which enables us to achieve state-of-the-art or competitive performance compared to previous discrete-state based methods in various benchmarks, like ImageNet256, MS COCO, and video dataset FaceForensics. In summary, by leveraging [MASK] in discrete-state models, we can bridge Masked Generative and Non-autoregressive Diffusion models, as well as generative and discriminative tasks.
Distillation of Diffusion Features for Semantic Correspondence
Dec 04, 2024Semantic correspondence, the task of determining relationships between different parts of images, underpins various applications including 3D reconstruction, image-to-image translation, object tracking, and visual place recognition. Recent studies have begun to explore representations learned in large generative image models for semantic correspondence, demonstrating promising results. Building on this progress, current state-of-the-art methods rely on combining multiple large models, resulting in high computational demands and reduced efficiency. In this work, we address this challenge by proposing a more computationally efficient approach. We propose a novel knowledge distillation technique to overcome the problem of reduced efficiency. We show how to use two large vision foundation models and distill the capabilities of these complementary models into one smaller model that maintains high accuracy at reduced computational cost. Furthermore, we demonstrate that by incorporating 3D data, we are able to further improve performance, without the need for human-annotated correspondences. Overall, our empirical results demonstrate that our distilled model with 3D data augmentation achieves performance superior to current state-of-the-art methods while significantly reducing computational load and enhancing practicality for real-world applications, such as semantic video correspondence. Our code and weights are publicly available on our project page.
Scaling Image Tokenizers with Grouped Spherical Quantization
Dec 03, 2024



Vision tokenizers have gained a lot of attraction due to their scalability and compactness; previous works depend on old-school GAN-based hyperparameters, biased comparisons, and a lack of comprehensive analysis of the scaling behaviours. To tackle those issues, we introduce Grouped Spherical Quantization (GSQ), featuring spherical codebook initialization and lookup regularization to constrain codebook latent to a spherical surface. Our empirical analysis of image tokenizer training strategies demonstrates that GSQ-GAN achieves superior reconstruction quality over state-of-the-art methods with fewer training iterations, providing a solid foundation for scaling studies. Building on this, we systematically examine the scaling behaviours of GSQ, specifically in latent dimensionality, codebook size, and compression ratios, and their impact on model performance. Our findings reveal distinct behaviours at high and low spatial compression levels, underscoring challenges in representing high-dimensional latent spaces. We show that GSQ can restructure high-dimensional latent into compact, low-dimensional spaces, thus enabling efficient scaling with improved quality. As a result, GSQ-GAN achieves a 16x down-sampling with a reconstruction FID (rFID) of 0.50.
Retinex-Diffusion: On Controlling Illumination Conditions in Diffusion Models via Retinex Theory
Jul 29, 2024This paper introduces a novel approach to illumination manipulation in diffusion models, addressing the gap in conditional image generation with a focus on lighting conditions. We conceptualize the diffusion model as a black-box image render and strategically decompose its energy function in alignment with the image formation model. Our method effectively separates and controls illumination-related properties during the generative process. It generates images with realistic illumination effects, including cast shadow, soft shadow, and inter-reflections. Remarkably, it achieves this without the necessity for learning intrinsic decomposition, finding directions in latent space, or undergoing additional training with new datasets.
Diffusion Models and Representation Learning: A Survey
Jun 30, 2024


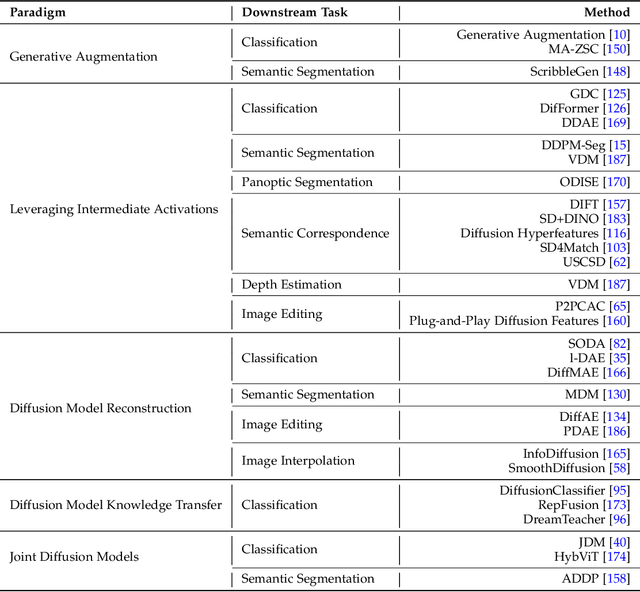
Diffusion Models are popular generative modeling methods in various vision tasks, attracting significant attention. They can be considered a unique instance of self-supervised learning methods due to their independence from label annotation. This survey explores the interplay between diffusion models and representation learning. It provides an overview of diffusion models' essential aspects, including mathematical foundations, popular denoising network architectures, and guidance methods. Various approaches related to diffusion models and representation learning are detailed. These include frameworks that leverage representations learned from pre-trained diffusion models for subsequent recognition tasks and methods that utilize advancements in representation and self-supervised learning to enhance diffusion models. This survey aims to offer a comprehensive overview of the taxonomy between diffusion models and representation learning, identifying key areas of existing concerns and potential exploration. Github link: https://github.com/dongzhuoyao/Diffusion-Representation-Learning-Survey-Taxonomy
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
Mar 25, 2024In recent years, advances in text-to-image (T2I) diffusion models have substantially elevated the quality of their generated images. However, achieving fine-grained control over attributes remains a challenge due to the limitations of natural language prompts (such as no continuous set of intermediate descriptions existing between ``person'' and ``old person''). Even though many methods were introduced that augment the model or generation process to enable such control, methods that do not require a fixed reference image are limited to either enabling global fine-grained attribute expression control or coarse attribute expression control localized to specific subjects, not both simultaneously. We show that there exist directions in the commonly used token-level CLIP text embeddings that enable fine-grained subject-specific control of high-level attributes in text-to-image models. Based on this observation, we introduce one efficient optimization-free and one robust optimization-based method to identify these directions for specific attributes from contrastive text prompts. We demonstrate that these directions can be used to augment the prompt text input with fine-grained control over attributes of specific subjects in a compositional manner (control over multiple attributes of a single subject) without having to adapt the diffusion model. Project page: https://compvis.github.io/attribute-control. Code is available at https://github.com/CompVis/attribute-control.