 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Semantic Encoders Can Harm Relighting Performance: Probing Visual Priors via Augmented Latent Intrinsics
Feb 01, 2026Image-to-image relighting requires representations that disentangle scene properties from illumination. Recent methods rely on latent intrinsic representations but remain under-constrained and often fail on challenging materials such as metal and glass. A natural hypothesis is that stronger pretrained visual priors should resolve these failures. We find the opposite: features from top-performing semantic encoders often degrade relighting quality, revealing a fundamental trade-off between semantic abstraction and photometric fidelity. We study this trade-off and introduce Augmented Latent Intrinsics (ALI), which balances semantic context and dense photometric structure by fusing features from a pixel-aligned visual encoder into a latent-intrinsic framework, together with a self-supervised refinement strategy to mitigate the scarcity of paired real-world data. Trained only on unlabeled real-world image pairs and paired with a dense, pixel-aligned visual prior, ALI achieves strong improvements in relighting, with the largest gains on complex, specular materials. Project page: https:\\augmented-latent-intrinsics.github.io
GR3EN: Generative Relighting for 3D Environments
Jan 22, 2026We present a method for relighting 3D reconstructions of large room-scale environments. Existing solutions for 3D scene relighting often require solving under-determined or ill-conditioned inverse rendering problems, and are as such unable to produce high-quality results on complex real-world scenes. Though recent progress in using generative image and video diffusion models for relighting has been promising, these techniques are either limited to 2D image and video relighting or 3D relighting of individual objects. Our approach enables controllable 3D relighting of room-scale scenes by distilling the outputs of a video-to-video relighting diffusion model into a 3D reconstruction. This side-steps the need to solve a difficult inverse rendering problem, and results in a flexible system that can relight 3D reconstructions of complex real-world scenes. We validate our approach on both synthetic and real-world datasets to show that it can faithfully render novel views of scenes under new lighting conditions.
Towards Integrating Uncertainty for Domain-Agnostic Segmentation
Dec 29, 2025Foundation models for segmentation such as the Segment Anything Model (SAM) family exhibit strong zero-shot performance, but remain vulnerable in shifted or limited-knowledge domains. This work investigates whether uncertainty quantification can mitigate such challenges and enhance model generalisability in a domain-agnostic manner. To this end, we (1) curate UncertSAM, a benchmark comprising eight datasets designed to stress-test SAM under challenging segmentation conditions including shadows, transparency, and camouflage; (2) evaluate a suite of lightweight, post-hoc uncertainty estimation methods; and (3) assess a preliminary uncertainty-guided prediction refinement step. Among evaluated approaches, a last-layer Laplace approximation yields uncertainty estimates that correlate well with segmentation errors, indicating a meaningful signal. While refinement benefits are preliminary, our findings underscore the potential of incorporating uncertainty into segmentation models to support robust, domain-agnostic performance. Our benchmark and code are made publicly available.
LumiNet: Latent Intrinsics Meets Diffusion Models for Indoor Scene Relighting
Dec 03, 2024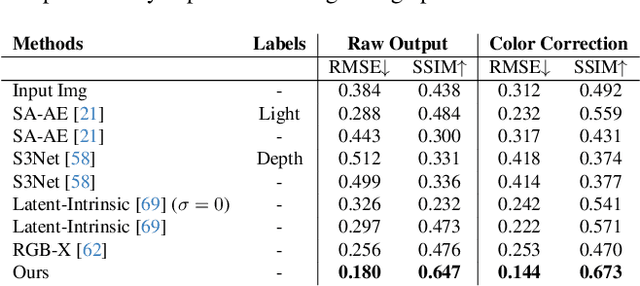



We introduce LumiNet, a novel architecture that leverages generative models and latent intrinsic representations for effective lighting transfer. Given a source image and a target lighting image, LumiNet synthesizes a relit version of the source scene that captures the target's lighting. Our approach makes two key contributions: a data curation strategy from the StyleGAN-based relighting model for our training, and a modified diffusion-based ControlNet that processes both latent intrinsic properties from the source image and latent extrinsic properties from the target image. We further improve lighting transfer through a learned adaptor (MLP) that injects the target's latent extrinsic properties via cross-attention and fine-tuning. Unlike traditional ControlNet, which generates images with conditional maps from a single scene, LumiNet processes latent representations from two different images - preserving geometry and albedo from the source while transferring lighting characteristics from the target. Experiments demonstrate that our method successfully transfers complex lighting phenomena including specular highlights and indirect illumination across scenes with varying spatial layouts and materials, outperforming existing approaches on challenging indoor scenes using only images as input.
Retinex-Diffusion: On Controlling Illumination Conditions in Diffusion Models via Retinex Theory
Jul 29, 2024This paper introduces a novel approach to illumination manipulation in diffusion models, addressing the gap in conditional image generation with a focus on lighting conditions. We conceptualize the diffusion model as a black-box image render and strategically decompose its energy function in alignment with the image formation model. Our method effectively separates and controls illumination-related properties during the generative process. It generates images with realistic illumination effects, including cast shadow, soft shadow, and inter-reflections. Remarkably, it achieves this without the necessity for learning intrinsic decomposition, finding directions in latent space, or undergoing additional training with new datasets.
Intrinsic Appearance Decomposition Using Point Cloud Representation
Jul 20, 2023

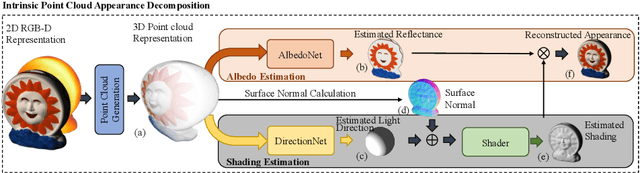

Intrinsic decomposition is to infer the albedo and shading from the image. Since it is a heavily ill-posed problem, previous methods rely on prior assumptions from 2D images, however, the exploration of the data representation itself is limited. The point cloud is known as a rich format of scene representation, which naturally aligns the geometric information and the color information of an image. Our proposed method, Point Intrinsic Net, in short, PoInt-Net, jointly predicts the albedo, light source direction, and shading, using point cloud representation. Experiments reveal the benefits of PoInt-Net, in terms of accuracy, it outperforms 2D representation approaches on multiple metrics across datasets; in terms of efficiency, it trains on small-scale point clouds and performs stably on any-scale point clouds; in terms of robustness, it only trains on single object level dataset, and demonstrates reasonable generalization ability for unseen objects and scenes.
Point Cloud Color Constancy
Nov 22, 2021



In this paper, we present Point Cloud Color Constancy, in short PCCC, an illumination chromaticity estimation algorithm exploiting a point cloud. We leverage the depth information captured by the time-of-flight (ToF) sensor mounted rigidly with the RGB sensor, and form a 6D cloud where each point contains the coordinates and RGB intensities, noted as (x,y,z,r,g,b). PCCC applies the PointNet architecture to the color constancy problem, deriving the illumination vector point-wise and then making a global decision about the global illumination chromaticity. On two popular RGB-D datasets, which we extend with illumination information, as well as on a novel benchmark, PCCC obtains lower error than the state-of-the-art algorithms. Our method is simple and fast, requiring merely 16*16-size input and reaching speed over 500 fps, including the cost of building the point cloud and net inference.