 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Semantic Encoders Can Harm Relighting Performance: Probing Visual Priors via Augmented Latent Intrinsics
Feb 01, 2026Image-to-image relighting requires representations that disentangle scene properties from illumination. Recent methods rely on latent intrinsic representations but remain under-constrained and often fail on challenging materials such as metal and glass. A natural hypothesis is that stronger pretrained visual priors should resolve these failures. We find the opposite: features from top-performing semantic encoders often degrade relighting quality, revealing a fundamental trade-off between semantic abstraction and photometric fidelity. We study this trade-off and introduce Augmented Latent Intrinsics (ALI), which balances semantic context and dense photometric structure by fusing features from a pixel-aligned visual encoder into a latent-intrinsic framework, together with a self-supervised refinement strategy to mitigate the scarcity of paired real-world data. Trained only on unlabeled real-world image pairs and paired with a dense, pixel-aligned visual prior, ALI achieves strong improvements in relighting, with the largest gains on complex, specular materials. Project page: https:\\augmented-latent-intrinsics.github.io
SyncLight: Controllable and Consistent Multi-View Relighting
Jan 23, 2026We present SyncLight, the first method to enable consistent, parametric relighting across multiple uncalibrated views of a static scene. While single-view relighting has advanced significantly, existing generative approaches struggle to maintain the rigorous lighting consistency essential for multi-camera broadcasts, stereoscopic cinema, and virtual production. SyncLight addresses this by enabling precise control over light intensity and color across a multi-view capture of a scene, conditioned on a single reference edit. Our method leverages a multi-view diffusion transformer trained using a latent bridge matching formulation, achieving high-fidelity relighting of the entire image set in a single inference step. To facilitate training, we introduce a large-scale hybrid dataset comprising diverse synthetic environments -- curated from existing sources and newly designed scenes -- alongside high-fidelity, real-world multi-view captures under calibrated illumination. Surprisingly, though trained only on image pairs, SyncLight generalizes zero-shot to an arbitrary number of viewpoints, effectively propagating lighting changes across all views, without requiring camera pose information. SyncLight enables practical relighting workflows for multi-view capture systems.
Name That Part: 3D Part Segmentation and Naming
Dec 19, 2025
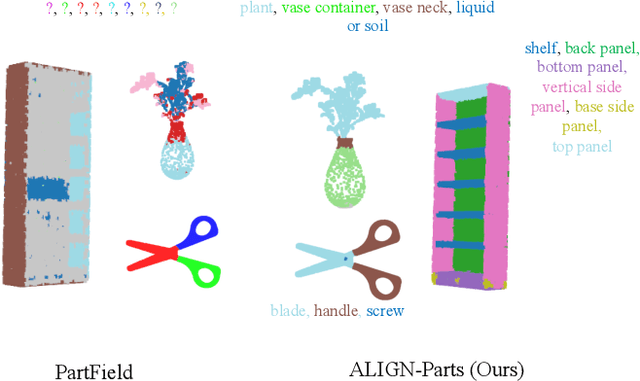

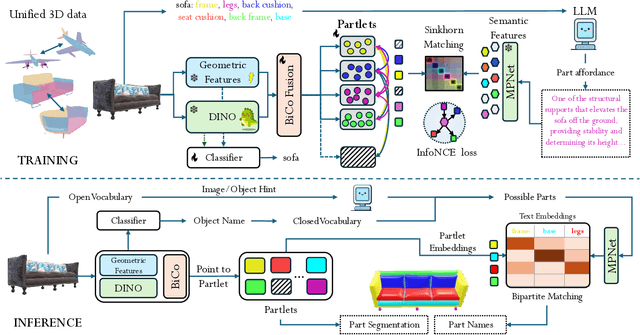
We address semantic 3D part segmentation: decomposing objects into parts with meaningful names. While datasets exist with part annotations, their definitions are inconsistent across datasets, limiting robust training. Previous methods produce unlabeled decompositions or retrieve single parts without complete shape annotations. We propose ALIGN-Parts, which formulates part naming as a direct set alignment task. Our method decomposes shapes into partlets - implicit 3D part representations - matched to part descriptions via bipartite assignment. We combine geometric cues from 3D part fields, appearance from multi-view vision features, and semantic knowledge from language-model-generated affordance descriptions. Text-alignment loss ensures partlets share embedding space with text, enabling a theoretically open-vocabulary matching setup, given sufficient data. Our efficient and novel, one-shot, 3D part segmentation and naming method finds applications in several downstream tasks, including serving as a scalable annotation engine. As our model supports zero-shot matching to arbitrary descriptions and confidence-calibrated predictions for known categories, with human verification, we create a unified ontology that aligns PartNet, 3DCoMPaT++, and Find3D, consisting of 1,794 unique 3D parts. We also show examples from our newly created Tex-Parts dataset. We also introduce 2 novel metrics appropriate for the named 3D part segmentation task.
Do You Know Where Your Camera Is? View-Invariant Policy Learning with Camera Conditioning
Oct 02, 2025We study view-invariant imitation learning by explicitly conditioning policies on camera extrinsics. Using Plucker embeddings of per-pixel rays, we show that conditioning on extrinsics significantly improves generalization across viewpoints for standard behavior cloning policies, including ACT, Diffusion Policy, and SmolVLA. To evaluate policy robustness under realistic viewpoint shifts, we introduce six manipulation tasks in RoboSuite and ManiSkill that pair "fixed" and "randomized" scene variants, decoupling background cues from camera pose. Our analysis reveals that policies without extrinsics often infer camera pose using visual cues from static backgrounds in fixed scenes; this shortcut collapses when workspace geometry or camera placement shifts. Conditioning on extrinsics restores performance and yields robust RGB-only control without depth. We release the tasks, demonstrations, and code at https://ripl.github.io/know_your_camera/ .
Generative Blocks World: Moving Things Around in Pictures
Jun 25, 2025We describe Generative Blocks World to interact with the scene of a generated image by manipulating simple geometric abstractions. Our method represents scenes as assemblies of convex 3D primitives, and the same scene can be represented by different numbers of primitives, allowing an editor to move either whole structures or small details. Once the scene geometry has been edited, the image is generated by a flow-based method which is conditioned on depth and a texture hint. Our texture hint takes into account the modified 3D primitives, exceeding texture-consistency provided by existing key-value caching techniques. These texture hints (a) allow accurate object and camera moves and (b) largely preserve the identity of objects depicted. Quantitative and qualitative experiments demonstrate that our approach outperforms prior works in visual fidelity, editability, and compositional generalization.
Visual Jenga: Discovering Object Dependencies via Counterfactual Inpainting
Mar 27, 2025This paper proposes a novel scene understanding task called Visual Jenga. Drawing inspiration from the game Jenga, the proposed task involves progressively removing objects from a single image until only the background remains. Just as Jenga players must understand structural dependencies to maintain tower stability, our task reveals the intrinsic relationships between scene elements by systematically exploring which objects can be removed while preserving scene coherence in both physical and geometric sense. As a starting point for tackling the Visual Jenga task, we propose a simple, data-driven, training-free approach that is surprisingly effective on a range of real-world images. The principle behind our approach is to utilize the asymmetry in the pairwise relationships between objects within a scene and employ a large inpainting model to generate a set of counterfactuals to quantify the asymmetry.
From an Image to a Scene: Learning to Imagine the World from a Million 360 Videos
Dec 10, 2024Three-dimensional (3D) understanding of objects and scenes play a key role in humans' ability to interact with the world and has been an active area of research in computer vision, graphics, and robotics. Large scale synthetic and object-centric 3D datasets have shown to be effective in training models that have 3D understanding of objects. However, applying a similar approach to real-world objects and scenes is difficult due to a lack of large-scale data. Videos are a potential source for real-world 3D data, but finding diverse yet corresponding views of the same content has shown to be difficult at scale. Furthermore, standard videos come with fixed viewpoints, determined at the time of capture. This restricts the ability to access scenes from a variety of more diverse and potentially useful perspectives. We argue that large scale 360 videos can address these limitations to provide: scalable corresponding frames from diverse views. In this paper, we introduce 360-1M, a 360 video dataset, and a process for efficiently finding corresponding frames from diverse viewpoints at scale. We train our diffusion-based model, Odin, on 360-1M. Empowered by the largest real-world, multi-view dataset to date, Odin is able to freely generate novel views of real-world scenes. Unlike previous methods, Odin can move the camera through the environment, enabling the model to infer the geometry and layout of the scene. Additionally, we show improved performance on standard novel view synthesis and 3D reconstruction benchmarks.
LumiNet: Latent Intrinsics Meets Diffusion Models for Indoor Scene Relighting
Dec 03, 2024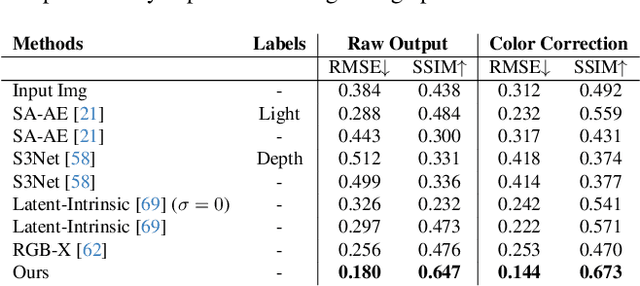



We introduce LumiNet, a novel architecture that leverages generative models and latent intrinsic representations for effective lighting transfer. Given a source image and a target lighting image, LumiNet synthesizes a relit version of the source scene that captures the target's lighting. Our approach makes two key contributions: a data curation strategy from the StyleGAN-based relighting model for our training, and a modified diffusion-based ControlNet that processes both latent intrinsic properties from the source image and latent extrinsic properties from the target image. We further improve lighting transfer through a learned adaptor (MLP) that injects the target's latent extrinsic properties via cross-attention and fine-tuning. Unlike traditional ControlNet, which generates images with conditional maps from a single scene, LumiNet processes latent representations from two different images - preserving geometry and albedo from the source while transferring lighting characteristics from the target. Experiments demonstrate that our method successfully transfers complex lighting phenomena including specular highlights and indirect illumination across scenes with varying spatial layouts and materials, outperforming existing approaches on challenging indoor scenes using only images as input.
SpotLight: Shadow-Guided Object Relighting via Diffusion
Nov 27, 2024Recent work has shown that diffusion models can be used as powerful neural rendering engines that can be leveraged for inserting virtual objects into images. Unlike typical physics-based renderers, however, neural rendering engines are limited by the lack of manual control over the lighting setup, which is often essential for improving or personalizing the desired image outcome. In this paper, we show that precise lighting control can be achieved for object relighting simply by specifying the desired shadows of the object. Rather surprisingly, we show that injecting only the shadow of the object into a pre-trained diffusion-based neural renderer enables it to accurately shade the object according to the desired light position, while properly harmonizing the object (and its shadow) within the target background image. Our method, SpotLight, leverages existing neural rendering approaches and achieves controllable relighting results with no additional training. Specifically, we demonstrate its use with two neural renderers from the recent literature. We show that SpotLight achieves superior object compositing results, both quantitatively and perceptually, as confirmed by a user study, outperforming existing diffusion-based models specifically designed for relighting.
ScribbleLight: Single Image Indoor Relighting with Scribbles
Nov 26, 2024Image-based relighting of indoor rooms creates an immersive virtual understanding of the space, which is useful for interior design, virtual staging, and real estate. Relighting indoor rooms from a single image is especially challenging due to complex illumination interactions between multiple lights and cluttered objects featuring a large variety in geometrical and material complexity. Recently, generative models have been successfully applied to image-based relighting conditioned on a target image or a latent code, albeit without detailed local lighting control. In this paper, we introduce ScribbleLight, a generative model that supports local fine-grained control of lighting effects through scribbles that describe changes in lighting. Our key technical novelty is an Albedo-conditioned Stable Image Diffusion model that preserves the intrinsic color and texture of the original image after relighting and an encoder-decoder-based ControlNet architecture that enables geometry-preserving lighting effects with normal map and scribble annotations. We demonstrate ScribbleLight's ability to create different lighting effects (e.g., turning lights on/off, adding highlights, cast shadows, or indirect lighting from unseen lights) from sparse scribble annotations.