 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotLight: Shadow-Guided Object Relighting via Diffusion
Nov 27, 2024Recent work has shown that diffusion models can be used as powerful neural rendering engines that can be leveraged for inserting virtual objects into images. Unlike typical physics-based renderers, however, neural rendering engines are limited by the lack of manual control over the lighting setup, which is often essential for improving or personalizing the desired image outcome. In this paper, we show that precise lighting control can be achieved for object relighting simply by specifying the desired shadows of the object. Rather surprisingly, we show that injecting only the shadow of the object into a pre-trained diffusion-based neural renderer enables it to accurately shade the object according to the desired light position, while properly harmonizing the object (and its shadow) within the target background image. Our method, SpotLight, leverages existing neural rendering approaches and achieves controllable relighting results with no additional training. Specifically, we demonstrate its use with two neural renderers from the recent literature. We show that SpotLight achieves superior object compositing results, both quantitatively and perceptually, as confirmed by a user study, outperforming existing diffusion-based models specifically designed for relighting.
ZeroComp: Zero-shot Object Compositing from Image Intrinsics via Diffusion
Oct 10, 2024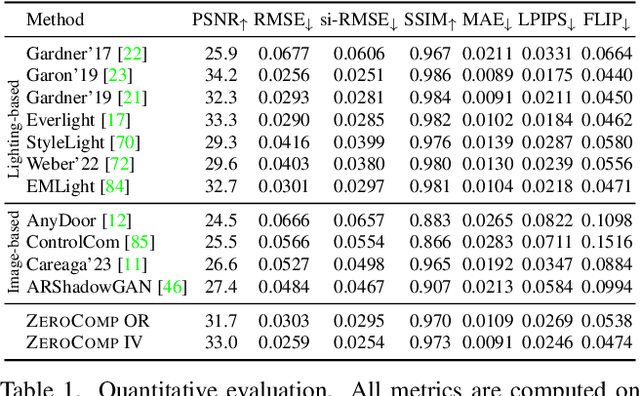
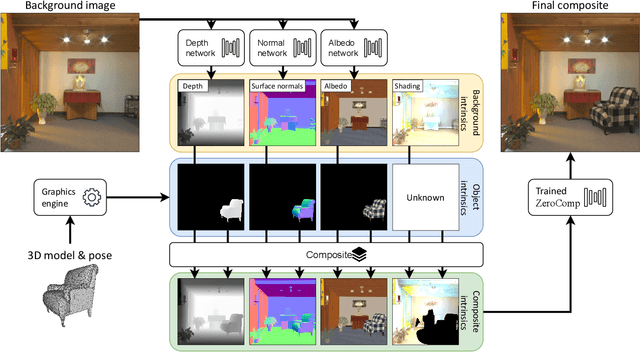
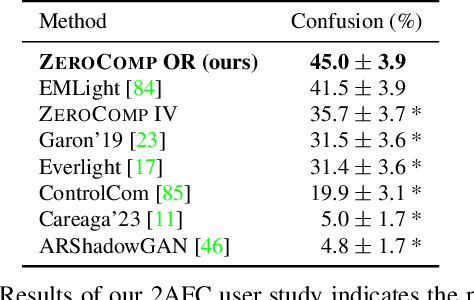

We present ZeroComp, an effective zero-shot 3D object compositing approach that does not require paired composite-scene images during training. Our method leverages ControlNet to condition from intrinsic images and combines it with a Stable Diffusion model to utilize its scene priors, together operating as an effective rendering engine. During training, ZeroComp uses intrinsic images based on geometry, albedo, and masked shading, all without the need for paired images of scenes with and without composite objects. Once trained, it seamlessly integrates virtual 3D objects into scenes, adjusting shading to create realistic composites. We developed a high-quality evaluation dataset and demonstrate that ZeroComp outperforms methods using explicit lighting estimations and generative techniques in quantitative and human perception benchmarks. Additionally, ZeroComp extends to real and outdoor image compositing, even when trained solely on synthetic indoor data, showcasing its effectiveness in image compositing.
Editable Indoor Lighting Estimation
Nov 09, 2022
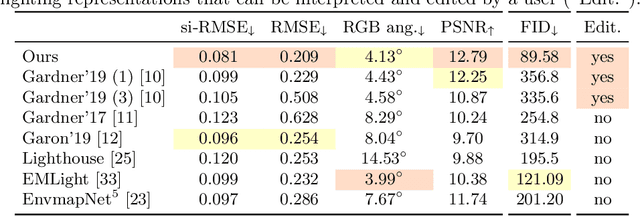
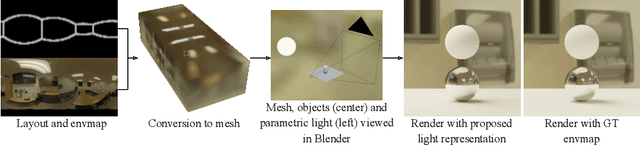
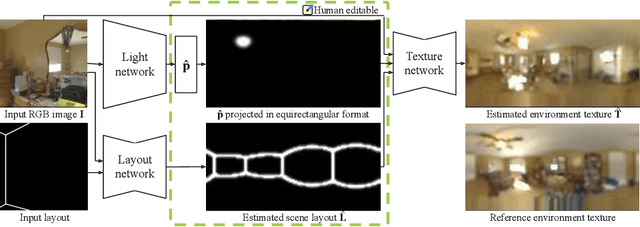
We present a method for estimating lighting from a single perspective image of an indoor scene. Previous methods for predicting indoor illumination usually focus on either simple, parametric lighting that lack realism, or on richer representations that are difficult or even impossible to understand or modify after prediction. We propose a pipeline that estimates a parametric light that is easy to edit and allows renderings with strong shadows, alongside with a non-parametric texture with high-frequency information necessary for realistic rendering of specular objects. Once estimated, the predictions obtained with our model are interpretable and can easily be modified by an artist/user with a few mouse clicks. Quantitative and qualitative results show that our approach makes indoor lighting estimation easier to handle by a casual user, while still producing competitive results.
RGB-D-E: Event Camera Calibration for Fast 6-DOF Object Tracking
Jun 09, 2020

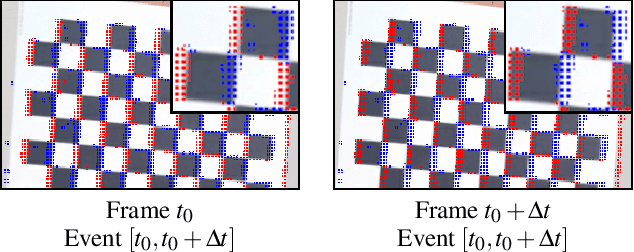
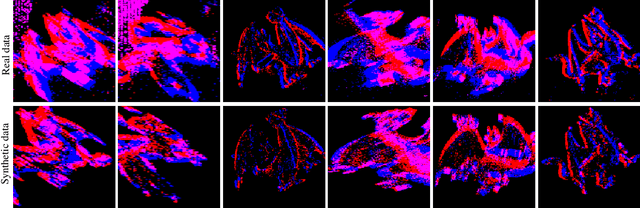
Augmented reality devices require multiple sensors to perform various tasks such as localization and tracking. Currently, popular cameras are mostly frame-based (e.g. RGB and Depth) which impose a high data bandwidth and power usage. With the necessity for low power and more responsive augmented reality systems, using solely frame-based sensors imposes limits to the various algorithms that needs high frequency data from the environement. As such, event-based sensors have become increasingly popular due to their low power, bandwidth and latency, as well as their very high frequency data acquisition capabilities. In this paper, we propose, for the first time, to use an event-based camera to increase the speed of 3D object tracking in 6 degrees of freedom. This application requires handling very high object speed to convey compelling AR experiences. To this end, we propose a new system which combines a recent RGB-D sensor (Kinect Azure) with an event camera (DAVIS346). We develop a deep learning approach, which combines an existing RGB-D network along with a novel event-based network in a cascade fashion, and demonstrate that our approach significantly improves the robustness of a state-of-the-art frame-based 6-DOF object tracker using our RGB-D-E pipeline.
Input Dropout for Spatially Aligned Modalities
Feb 07, 2020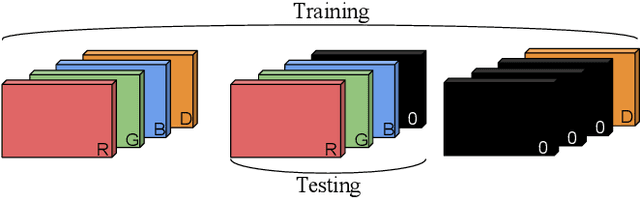
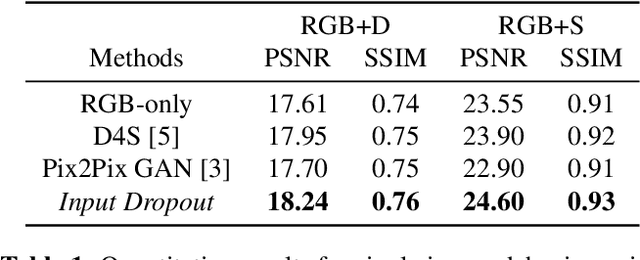

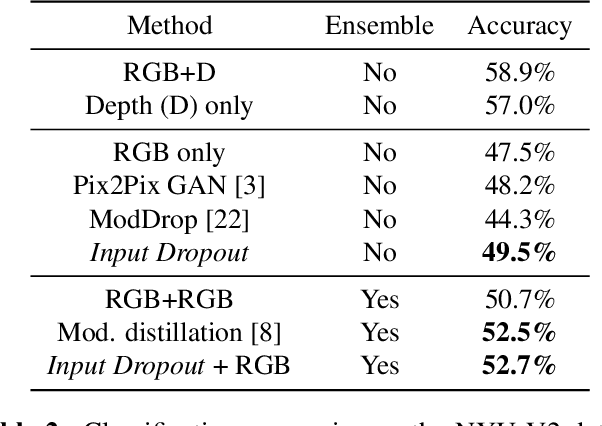
Computer vision datasets containing multiple modalities such as color, depth, and thermal properties are now commonly accessible and useful for solving a wide array of challenging tasks. However, deploying multi-sensor heads is not possible in many scenarios. As such many practical solutions tend to be based on simpler sensors, mostly for cost, simplicity and robustness considerations. In this work, we propose a training methodology to take advantage of these additional modalities available in datasets, even if they are not available at test time. By assuming that the modalities have a strong spatial correlation, we propose Input Dropout, a simple technique that consists in stochastic hiding of one or many input modalities at training time, while using only the canonical (e.g. RGB) modalities at test time. We demonstrate that Input Dropout trivially combines with existing deep convolutional architectures, and improves their performance on a wide range of computer vision tasks such as dehazing, 6-DOF object tracking, pedestrian detection and object classification.
Learning to Match Templates for Unseen Instance Detection
Nov 26, 2019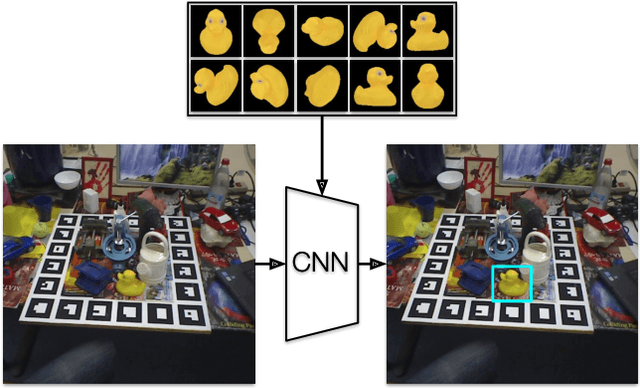
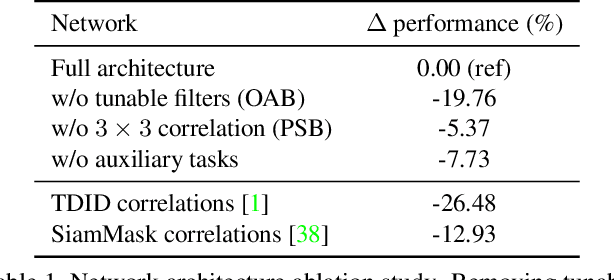


Detecting objects in images is a quintessential problem in computer vision. Much of the focus in the literature has been on the problem of identifying the bounding box of a particular type of objects in an image. Yet, in many contexts such as robotics and augmented reality, it is more important to find a specific object instance---a unique toy or a custom industrial part for example---rather than a generic object class. Here, applications can require a rapid shift from one object instance to another, thus requiring fast turnaround which affords little-to-no training time. In this context, we propose a method for detecting objects that are unknown at training time. Our approach frames the problem as one of learned template matching, where a network is trained to match the template of an object in an image. The template is obtained by rendering a textured 3D model of the object. At test time, we provide a novel 3D object, and the network is able to successfully detect it, even under significant occlusion. Our method offers an improvement of almost 30 mAP over the previous template matching methods on the challenging Occluded Linemod (overall mAP of 50.7). With no access to the objects at training time, our method still yields detection results that are on par with existing ones that are allowed to train on the objects. By reviving this research direction in the context of more powerful, deep feature extractors, our work sets the stage for more development in the area of unseen object instance detection.
Fast Spatially-Varying Indoor Lighting Estimation
Jun 10, 2019
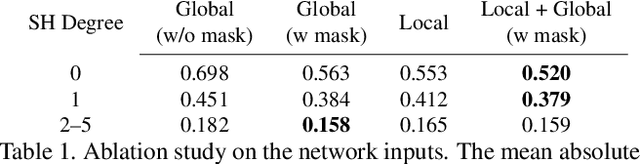

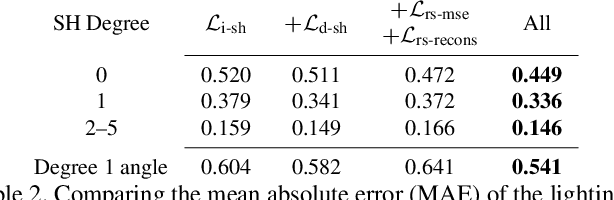
We propose a real-time method to estimate spatiallyvarying indoor lighting from a single RGB image. Given an image and a 2D location in that image, our CNN estimates a 5th order spherical harmonic representation of the lighting at the given location in less than 20ms on a laptop mobile graphics card. While existing approaches estimate a single, global lighting representation or require depth as input, our method reasons about local lighting without requiring any geometry information. We demonstrate, through quantitative experiments including a user study, that our results achieve lower lighting estimation errors and are preferred by users over the state-of-the-art. Our approach can be used directly for augmented reality applications, where a virtual object is relit realistically at any position in the scene in real-time.
* CVPR19
A Framework for Evaluating 6-DOF Object Trackers
Sep 06, 2018
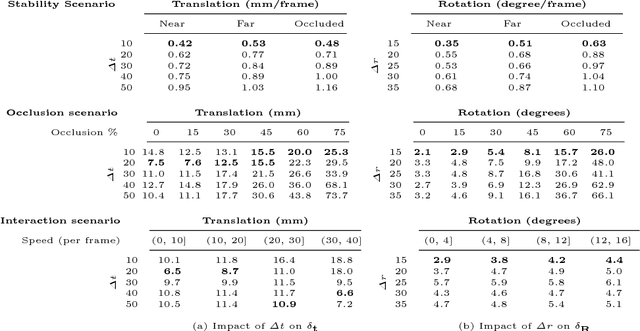


We present a challenging and realistic novel dataset for evaluating 6-DOF object tracking algorithms. Existing datasets show serious limitations---notably, unrealistic synthetic data, or real data with large fiducial markers---preventing the community from obtaining an accurate picture of the state-of-the-art. Using a data acquisition pipeline based on a commercial motion capture system for acquiring accurate ground truth poses of real objects with respect to a Kinect V2 camera, we build a dataset which contains a total of 297 calibrated sequences. They are acquired in three different scenarios to evaluate the performance of trackers: stability, robustness to occlusion and accuracy during challenging interactions between a person and the object. We conduct an extensive study of a deep 6-DOF tracking architecture and determine a set of optimal parameters. We enhance the architecture and the training methodology to train a 6-DOF tracker that can robustly generalize to objects never seen during training, and demonstrate favorable performance compared to previous approaches trained specifically on the objects to track.
Deep 6-DOF Tracking
Aug 15, 2017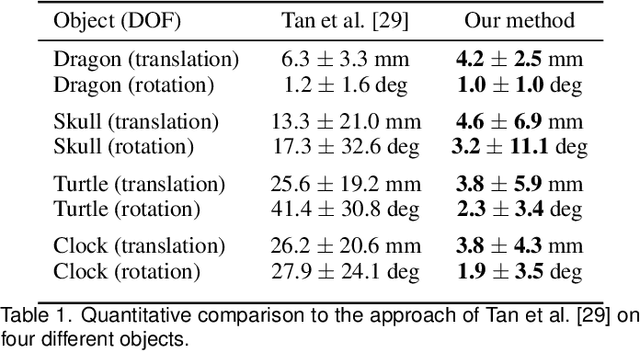

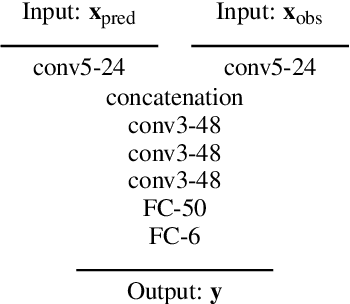
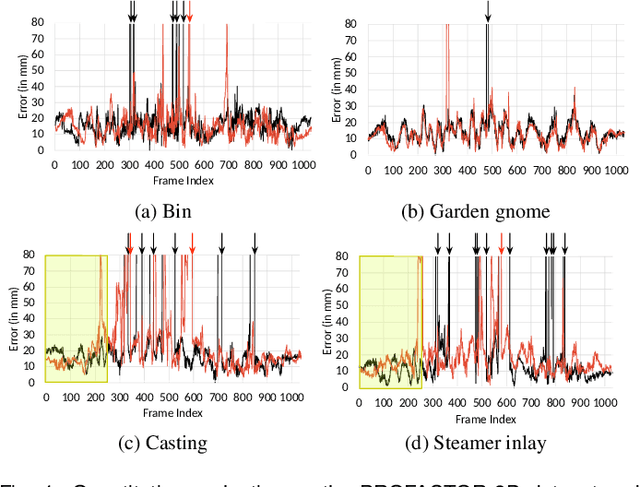
We present a temporal 6-DOF tracking method which leverages deep learning to achieve state-of-the-art performance on challenging datasets of real world capture. Our method is both more accurate and more robust to occlusions than the existing best performing approaches while maintaining real-time performance. To assess its efficacy, we evaluate our approach on several challenging RGBD sequences of real objects in a variety of conditions. Notably, we systematically evaluate robustness to occlusions through a series of sequences where the object to be tracked is increasingly occluded. Finally, our approach is purely data-driven and does not require any hand-designed features: robust tracking is automatically learned from data.
* 9 pages, 9 figures, ISMAR 2017, TVCG special edition Website: http://vision.gel.ulaval.ca/~jflalonde/projects/deepTracking/index.html