 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput Dropout for Spatially Aligned Modalities
Feb 07, 2020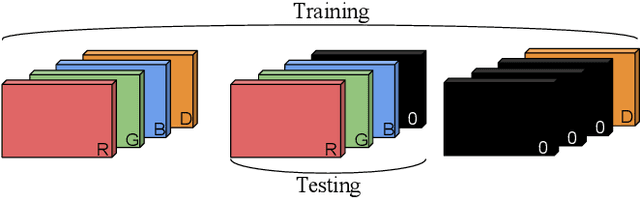
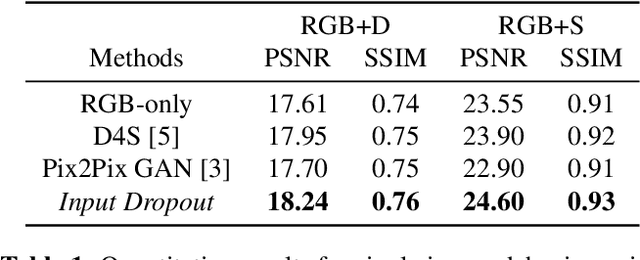

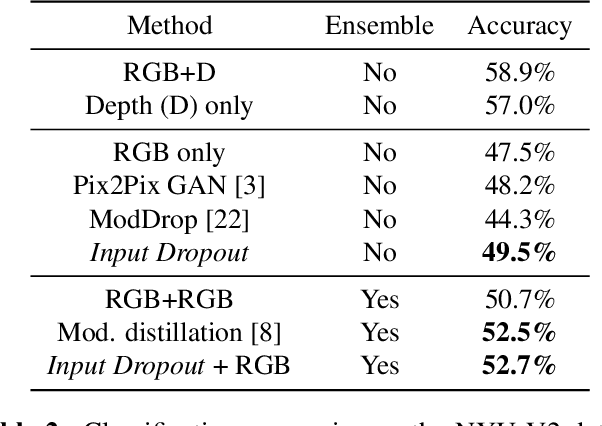
Computer vision datasets containing multiple modalities such as color, depth, and thermal properties are now commonly accessible and useful for solving a wide array of challenging tasks. However, deploying multi-sensor heads is not possible in many scenarios. As such many practical solutions tend to be based on simpler sensors, mostly for cost, simplicity and robustness considerations. In this work, we propose a training methodology to take advantage of these additional modalities available in datasets, even if they are not available at test time. By assuming that the modalities have a strong spatial correlation, we propose Input Dropout, a simple technique that consists in stochastic hiding of one or many input modalities at training time, while using only the canonical (e.g. RGB) modalities at test time. We demonstrate that Input Dropout trivially combines with existing deep convolutional architectures, and improves their performance on a wide range of computer vision tasks such as dehazing, 6-DOF object tracking, pedestrian detection and object classification.
Learning of Image Dehazing Models for Segmentation Tasks
Mar 04, 2019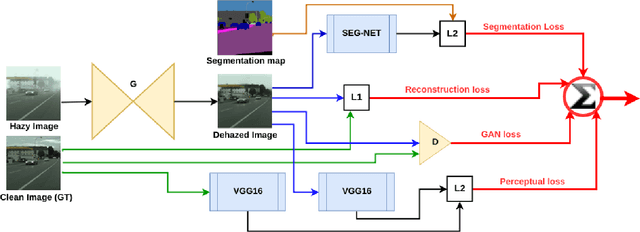
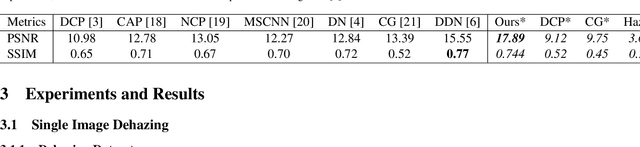

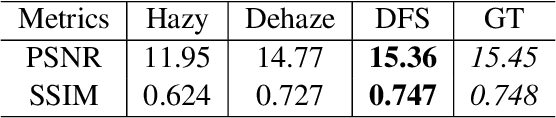
To evaluate their performance, existing dehazing approaches generally rely on distance measures between the generated image and its corresponding ground truth. Despite its ability to produce visually good images, using pixel-based or even perceptual metrics do not guarantee, in general, that the produced image is fit for being used as input for low-level computer vision tasks such as segmentation. To overcome this weakness, we are proposing a novel end-to-end approach for image dehazing, fit for being used as input to an image segmentation procedure, while maintaining the visual quality of the generated images. Inspired by the success of Generative Adversarial Networks (GAN), we propose to optimize the generator by introducing a discriminator network and a loss function that evaluates segmentation quality of dehazed images. In addition, we make use of a supplementary loss function that verifies that the visual and the perceptual quality of the generated image are preserved in hazy conditions. Results obtained using the proposed technique are appealing, with a favorable comparison to state-of-the-art approaches when considering the performance of segmentation algorithms on the hazy images.