 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Agnostic Image-to-image Translation using Low-Resolution Conditioning
May 11, 2023Generally, image-to-image translation (i2i) methods aim at learning mappings across domains with the assumption that the images used for translation share content (e.g., pose) but have their own domain-specific information (a.k.a. style). Conditioned on a target image, such methods extract the target style and combine it with the source image content, keeping coherence between the domains. In our proposal, we depart from this traditional view and instead consider the scenario where the target domain is represented by a very low-resolution (LR) image, proposing a domain-agnostic i2i method for fine-grained problems, where the domains are related. More specifically, our domain-agnostic approach aims at generating an image that combines visual features from the source image with low-frequency information (e.g. pose, color) of the LR target image. To do so, we present a novel approach that relies on training the generative model to produce images that both share distinctive information of the associated source image and correctly match the LR target image when downscaled. We validate our method on the CelebA-HQ and AFHQ datasets by demonstrating improvements in terms of visual quality. Qualitative and quantitative results show that when dealing with intra-domain image translation, our method generates realistic samples compared to state-of-the-art methods such as StarGAN v2. Ablation studies also reveal that our method is robust to changes in color, it can be applied to out-of-distribution images, and it allows for manual control over the final results.
Image-to-Image Translation with Low Resolution Conditioning
Jul 23, 2021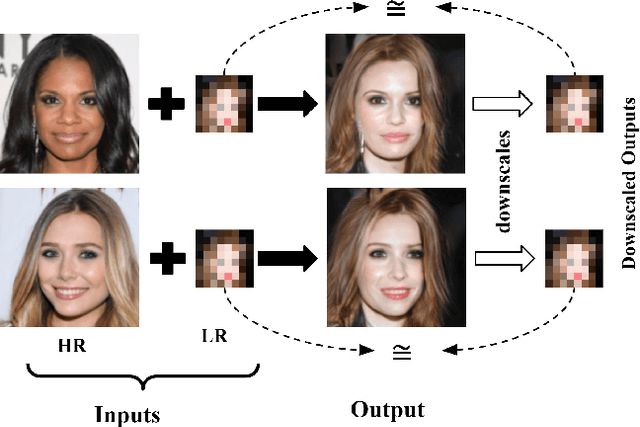
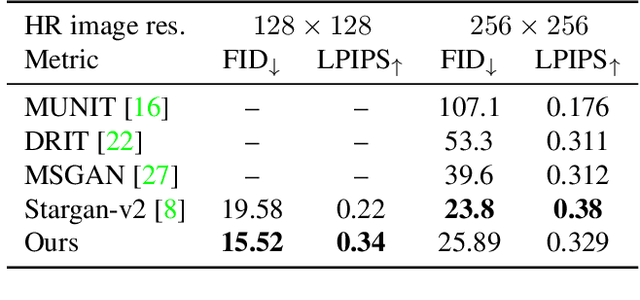
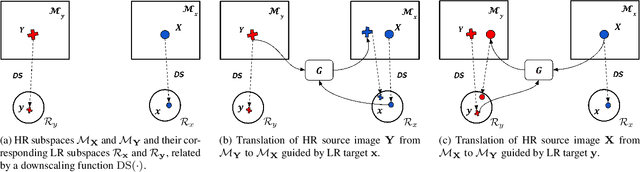
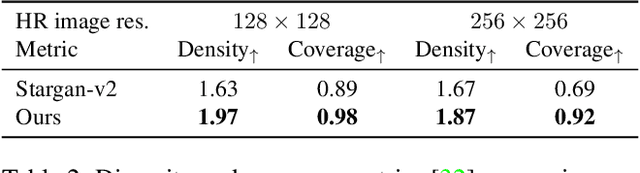
Most image-to-image translation methods focus on learning mappings across domains with the assumption that images share content (e.g., pose) but have their own domain-specific information known as style. When conditioned on a target image, such methods aim to extract the style of the target and combine it with the content of the source image. In this work, we consider the scenario where the target image has a very low resolution. More specifically, our approach aims at transferring fine details from a high resolution (HR) source image to fit a coarse, low resolution (LR) image representation of the target. We therefore generate HR images that share features from both HR and LR inputs. This differs from previous methods that focus on translating a given image style into a target content, our translation approach being able to simultaneously imitate the style and merge the structural information of the LR target. Our approach relies on training the generative model to produce HR target images that both 1) share distinctive information of the associated source image; 2) correctly match the LR target image when downscaled. We validate our method on the CelebA-HQ and AFHQ datasets by demonstrating improvements in terms of visual quality, diversity and coverage. Qualitative and quantitative results show that when dealing with intra-domain image translation, our method generates more realistic samples compared to state-of-the-art methods such as Stargan-v2
A Generative Model for Hallucinating Diverse Versions of Super Resolution Images
Feb 12, 2021
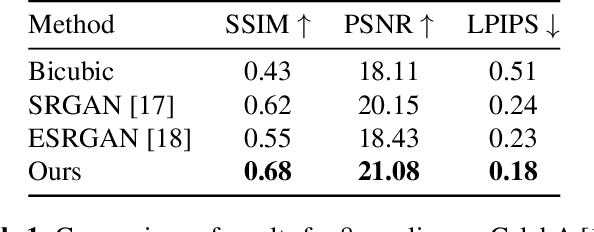
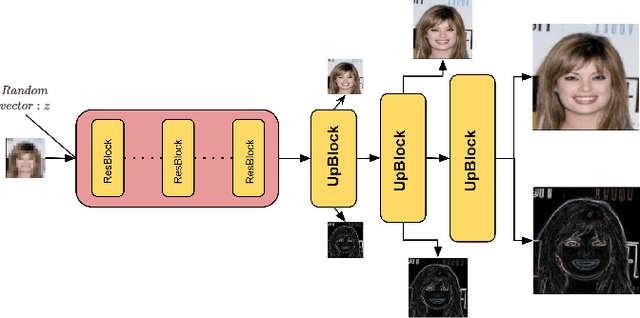
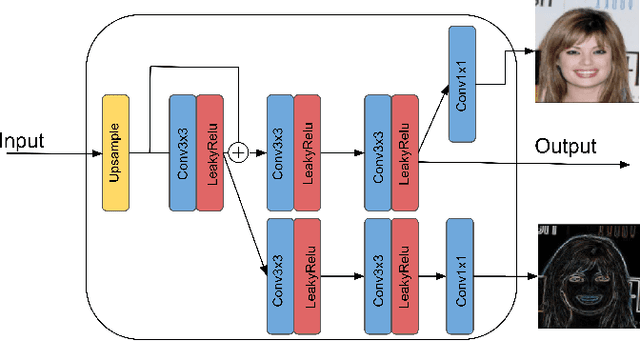
Traditionally, the main focus of image super-resolution techniques is on recovering the most likely high-quality images from low-quality images, using a one-to-one low- to high-resolution mapping. Proceeding that way, we ignore the fact that there are generally many valid versions of high-resolution images that map to a given low-resolution image. We are tackling in this work the problem of obtaining different high-resolution versions from the same low-resolution image using Generative Adversarial Models. Our learning approach makes use of high frequencies available in the training high-resolution images for preserving and exploring in an unsupervised manner the structural information available within these images. Experimental results on the CelebA dataset confirm the effectiveness of the proposed method, which allows the generation of both realistic and diverse high-resolution images from low-resolution images.
Learning of Image Dehazing Models for Segmentation Tasks
Mar 04, 2019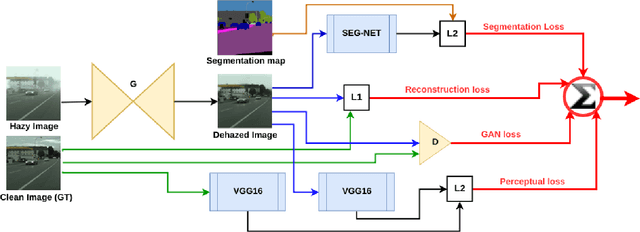
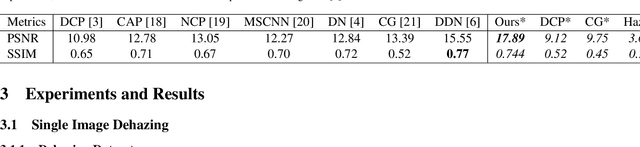

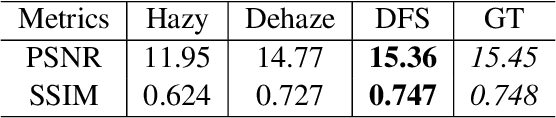
To evaluate their performance, existing dehazing approaches generally rely on distance measures between the generated image and its corresponding ground truth. Despite its ability to produce visually good images, using pixel-based or even perceptual metrics do not guarantee, in general, that the produced image is fit for being used as input for low-level computer vision tasks such as segmentation. To overcome this weakness, we are proposing a novel end-to-end approach for image dehazing, fit for being used as input to an image segmentation procedure, while maintaining the visual quality of the generated images. Inspired by the success of Generative Adversarial Networks (GAN), we propose to optimize the generator by introducing a discriminator network and a loss function that evaluates segmentation quality of dehazed images. In addition, we make use of a supplementary loss function that verifies that the visual and the perceptual quality of the generated image are preserved in hazy conditions. Results obtained using the proposed technique are appealing, with a favorable comparison to state-of-the-art approaches when considering the performance of segmentation algorithms on the hazy images.
Accumulating Knowledge for Lifelong Online Learning
Oct 26, 2018

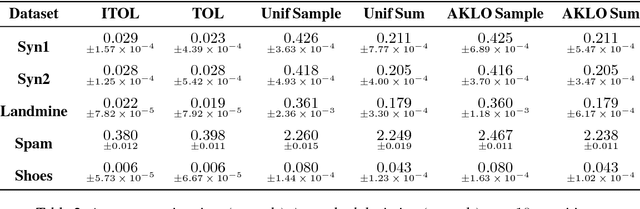
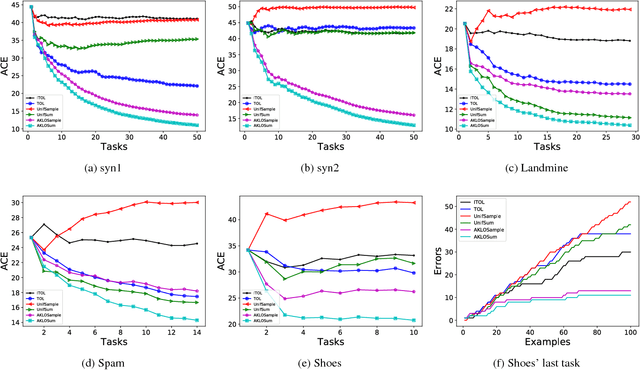
Lifelong learning can be viewed as a continuous transfer learning procedure over consecutive tasks, where learning a given task depends on accumulated knowledge --- the so-called knowledge base. Most published work on lifelong learning makes a batch processing of each task, implying that a data collection step is required beforehand. We are proposing a new framework, lifelong online learning, in which the learning procedure for each task is interactive. This is done through a computationally efficient algorithm where the predicted result for a given task is made by combining two intermediate predictions: by using only the information from the current task and by relying on the accumulated knowledge. In this work, two challenges are tackled: making no assumption on the task generation distribution, and processing with a possibly unknown number of instances for each task. We are providing a theoretical analysis of this algorithm, with a cumulative error upper bound for each task. We find that under some mild conditions, the algorithm can still benefit from a small cumulative error even when facing few interactions. Moreover, we provide experimental results on both synthetic and real datasets that validate the correct behavior and practical usefulness of the proposed algorithm.
Diversity regularization in deep ensembles
Feb 22, 2018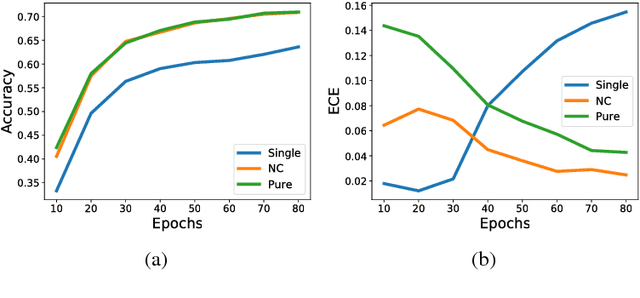

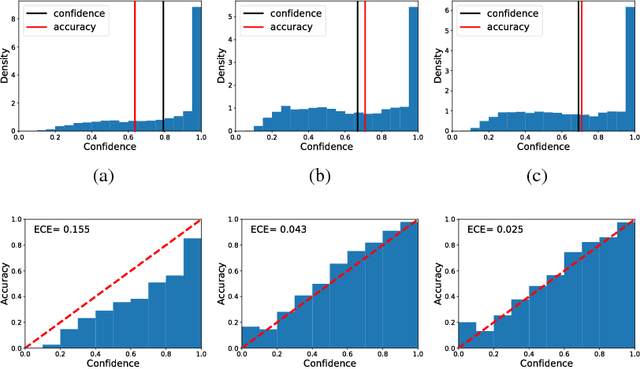

Calibrating the confidence of supervised learning models is important for a variety of contexts where the certainty over predictions should be reliable. However, it has been reported that deep neural network models are often too poorly calibrated for achieving complex tasks requiring reliable uncertainty estimates in their prediction. In this work, we are proposing a strategy for training deep ensembles with a diversity function regularization, which improves the calibration property while maintaining a similar prediction accuracy.