 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-to-Image Translation with Low Resolution Conditioning
Jul 23, 2021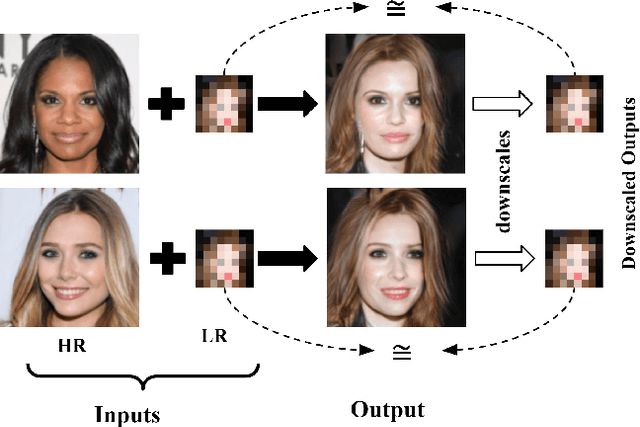
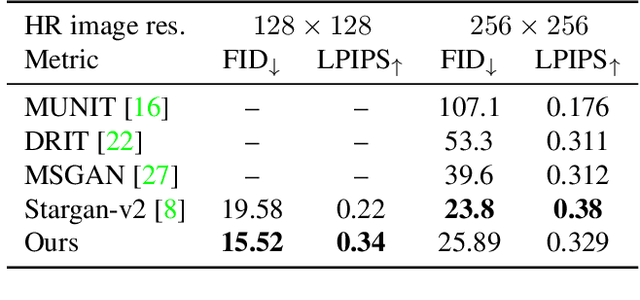
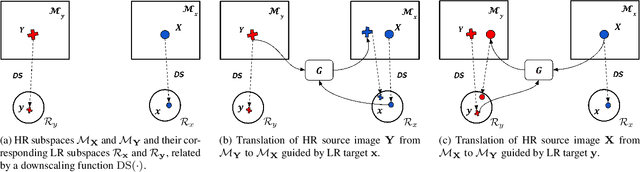
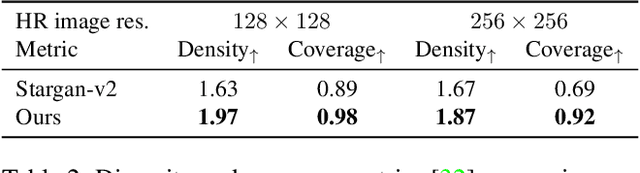
Most image-to-image translation methods focus on learning mappings across domains with the assumption that images share content (e.g., pose) but have their own domain-specific information known as style. When conditioned on a target image, such methods aim to extract the style of the target and combine it with the content of the source image. In this work, we consider the scenario where the target image has a very low resolution. More specifically, our approach aims at transferring fine details from a high resolution (HR) source image to fit a coarse, low resolution (LR) image representation of the target. We therefore generate HR images that share features from both HR and LR inputs. This differs from previous methods that focus on translating a given image style into a target content, our translation approach being able to simultaneously imitate the style and merge the structural information of the LR target. Our approach relies on training the generative model to produce HR target images that both 1) share distinctive information of the associated source image; 2) correctly match the LR target image when downscaled. We validate our method on the CelebA-HQ and AFHQ datasets by demonstrating improvements in terms of visual quality, diversity and coverage. Qualitative and quantitative results show that when dealing with intra-domain image translation, our method generates more realistic samples compared to state-of-the-art methods such as Stargan-v2
A Generative Model for Hallucinating Diverse Versions of Super Resolution Images
Feb 12, 2021
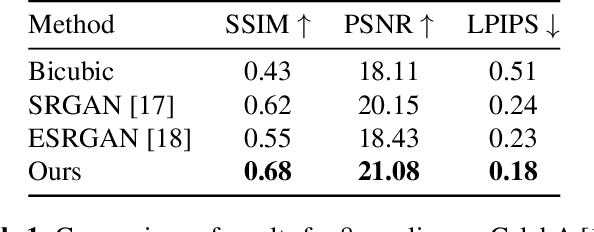
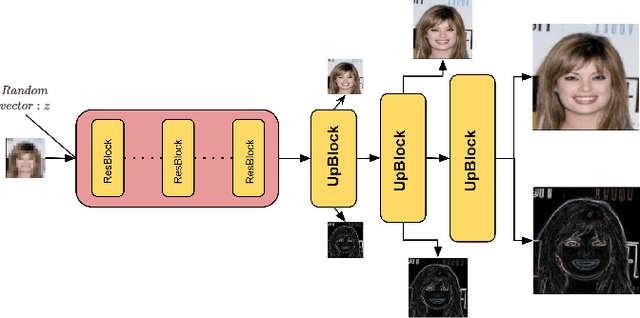
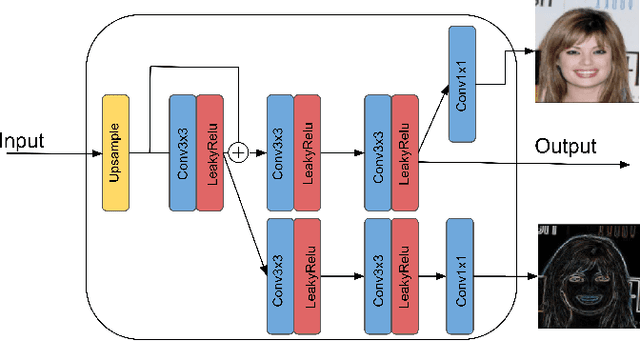
Traditionally, the main focus of image super-resolution techniques is on recovering the most likely high-quality images from low-quality images, using a one-to-one low- to high-resolution mapping. Proceeding that way, we ignore the fact that there are generally many valid versions of high-resolution images that map to a given low-resolution image. We are tackling in this work the problem of obtaining different high-resolution versions from the same low-resolution image using Generative Adversarial Models. Our learning approach makes use of high frequencies available in the training high-resolution images for preserving and exploring in an unsupervised manner the structural information available within these images. Experimental results on the CelebA dataset confirm the effectiveness of the proposed method, which allows the generation of both realistic and diverse high-resolution images from low-resolution images.