 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Representation Learning for Multimodal Brain Activity Translation
Sep 27, 2024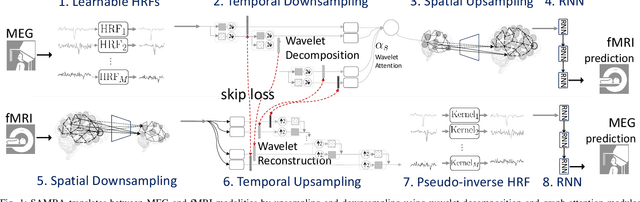
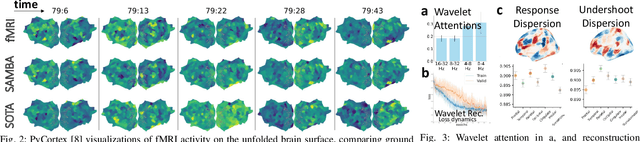
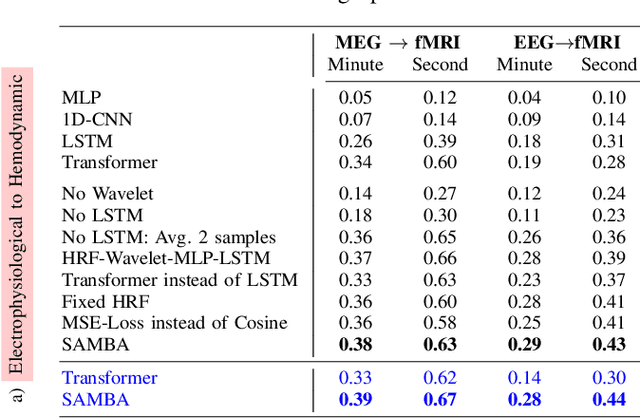
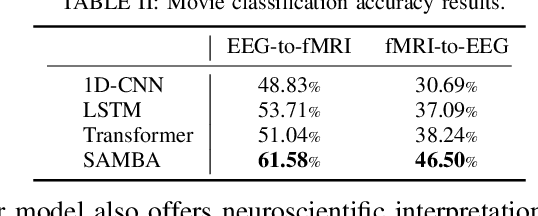
Neuroscience employs diverse neuroimaging techniques, each offering distinct insights into brain activity, from electrophysiological recordings such as EEG, which have high temporal resolution, to hemodynamic modalities such as fMRI, which have increased spatial precision. However, integrating these heterogeneous data sources remains a challenge, which limits a comprehensive understanding of brain function. We present the Spatiotemporal Alignment of Multimodal Brain Activity (SAMBA) framework, which bridges the spatial and temporal resolution gaps across modalities by learning a unified latent space free of modality-specific biases. SAMBA introduces a novel attention-based wavelet decomposition for spectral filtering of electrophysiological recordings, graph attention networks to model functional connectivity between functional brain units, and recurrent layers to capture temporal autocorrelations in brain signal. We show that the training of SAMBA, aside from achieving translation, also learns a rich representation of brain information processing. We showcase this classify external stimuli driving brain activity from the representation learned in hidden layers of SAMBA, paving the way for broad downstream applications in neuroscience research and clinical contexts.
Density-based Isometric Mapping
Mar 04, 2024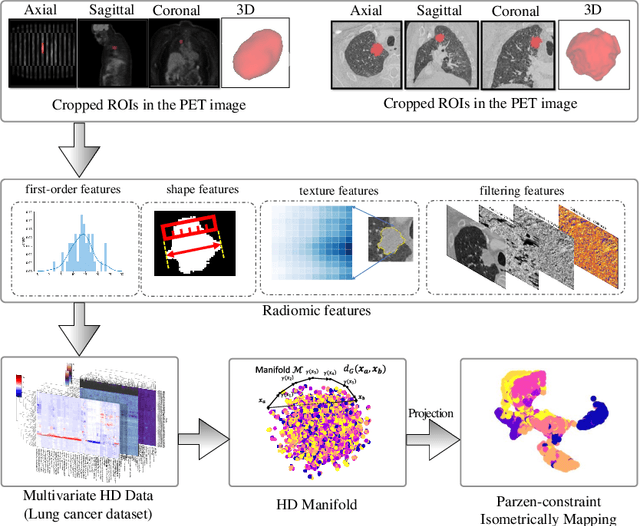
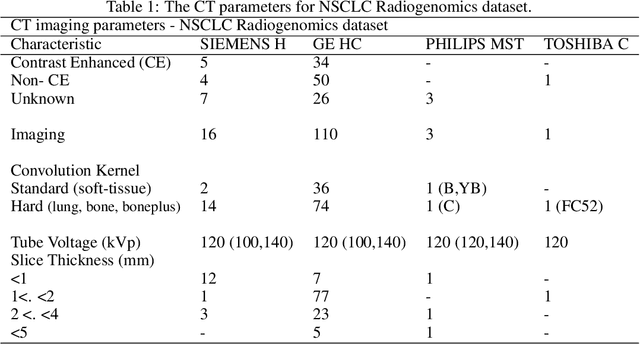
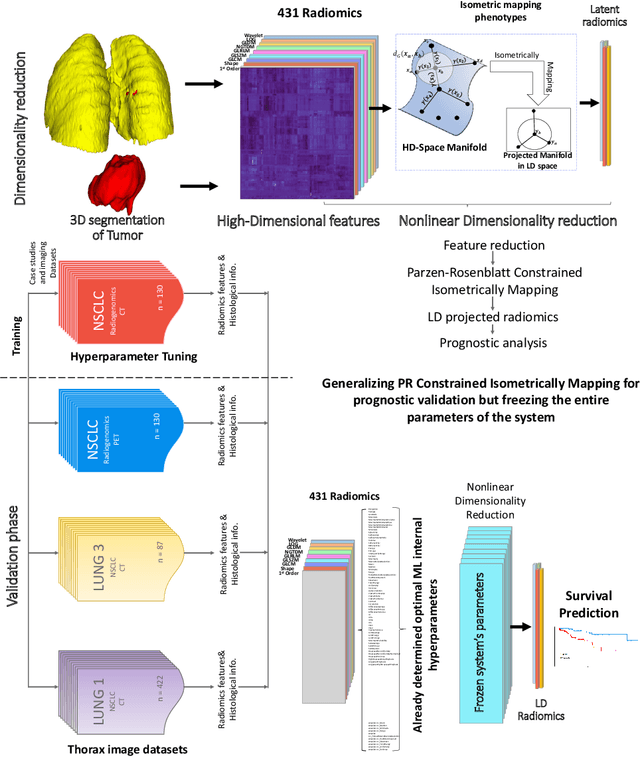
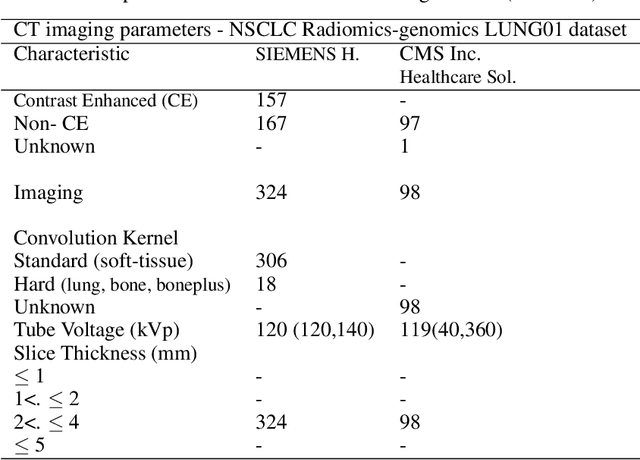
The isometric mapping method employs the shortest path algorithm to estimate the Euclidean distance between points on High dimensional (HD) manifolds. This may not be sufficient for weakly uniformed HD data as it could lead to overestimating distances between far neighboring points, resulting in inconsistencies between the intrinsic (local) and extrinsic (global) distances during the projection. To address this issue, we modify the shortest path algorithm by adding a novel constraint inspired by the Parzen-Rosenblatt (PR) window, which helps to maintain the uniformity of the constructed shortest-path graph in Isomap. Multiple imaging datasets overall of 72,236 cases, 70,000 MINST data, 1596 from multiple Chest-XRay pneumonia datasets, and three NSCLC CT/PET datasets with a total of 640 lung cancer patients, were used to benchmark and validate PR-Isomap. 431 imaging biomarkers were extracted from each modality. Our results indicate that PR-Isomap projects HD attributes into a lower-dimensional (LD) space while preserving information, visualized by the MNIST dataset indicating the maintaining local and global distances. PR-Isomap achieved the highest comparative accuracies of 80.9% (STD:5.8) for pneumonia and 78.5% (STD:4.4), 88.4% (STD:1.4), and 61.4% (STD:11.4) for three NSCLC datasets, with a confidence interval of 95% for outcome prediction. Similarly, the multivariate Cox model showed higher overall survival, measured with c-statistics and log-likelihood test, of PR-Isomap compared to other dimensionality reduction methods. Kaplan Meier survival curve also signifies the notable ability of PR-Isomap to distinguish between high-risk and low-risk patients using multimodal imaging biomarkers preserving HD imaging characteristics for precision medicine.
Domain Agnostic Image-to-image Translation using Low-Resolution Conditioning
May 11, 2023Generally, image-to-image translation (i2i) methods aim at learning mappings across domains with the assumption that the images used for translation share content (e.g., pose) but have their own domain-specific information (a.k.a. style). Conditioned on a target image, such methods extract the target style and combine it with the source image content, keeping coherence between the domains. In our proposal, we depart from this traditional view and instead consider the scenario where the target domain is represented by a very low-resolution (LR) image, proposing a domain-agnostic i2i method for fine-grained problems, where the domains are related. More specifically, our domain-agnostic approach aims at generating an image that combines visual features from the source image with low-frequency information (e.g. pose, color) of the LR target image. To do so, we present a novel approach that relies on training the generative model to produce images that both share distinctive information of the associated source image and correctly match the LR target image when downscaled. We validate our method on the CelebA-HQ and AFHQ datasets by demonstrating improvements in terms of visual quality. Qualitative and quantitative results show that when dealing with intra-domain image translation, our method generates realistic samples compared to state-of-the-art methods such as StarGAN v2. Ablation studies also reveal that our method is robust to changes in color, it can be applied to out-of-distribution images, and it allows for manual control over the final results.
DarSwin: Distortion Aware Radial Swin Transformer
Apr 19, 2023
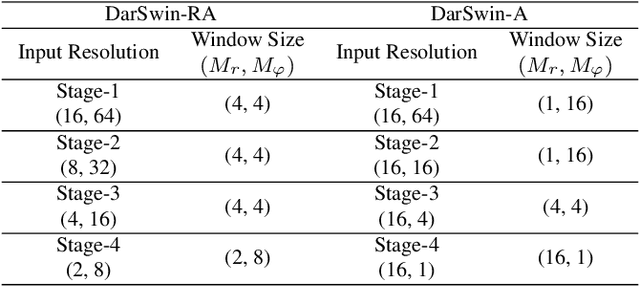

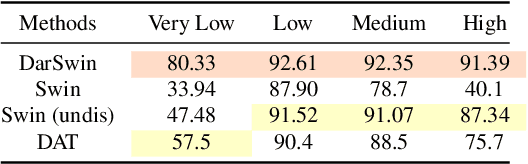
Wide-angle lenses are commonly used in perception tasks requiring a large field of view. Unfortunately, these lenses produce significant distortions making conventional models that ignore the distortion effects unable to adapt to wide-angle images. In this paper, we present a novel transformer-based model that automatically adapts to the distortion produced by wide-angle lenses. We leverage the physical characteristics of such lenses, which are analytically defined by the radial distortion profile (assumed to be known), to develop a distortion aware radial swin transformer (DarSwin). In contrast to conventional transformer-based architectures, DarSwin comprises a radial patch partitioning, a distortion-based sampling technique for creating token embeddings, and a polar position encoding for radial patch merging. We validate our method on classification tasks using synthetically distorted ImageNet data and show through extensive experiments that DarSwin can perform zero-shot adaptation to unseen distortions of different wide-angle lenses. Compared to other baselines, DarSwin achieves the best results (in terms of Top-1 and -5 accuracy), when tested on in-distribution data, with almost 2% (6%) gain in Top-1 accuracy under medium (high) distortion levels, and comparable to the state-of-the-art under low and very low distortion levels (perspective-like images).
Matching Feature Sets for Few-Shot Image Classification
Apr 02, 2022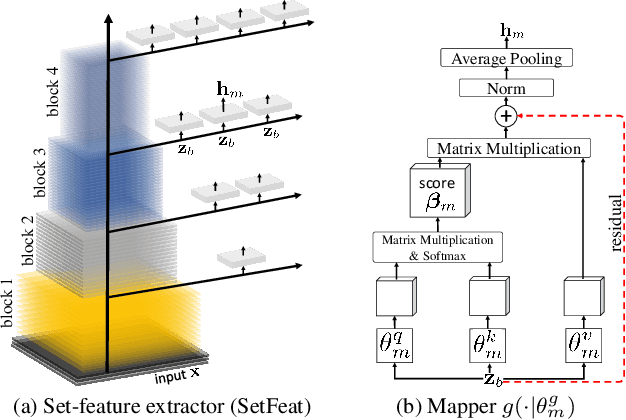
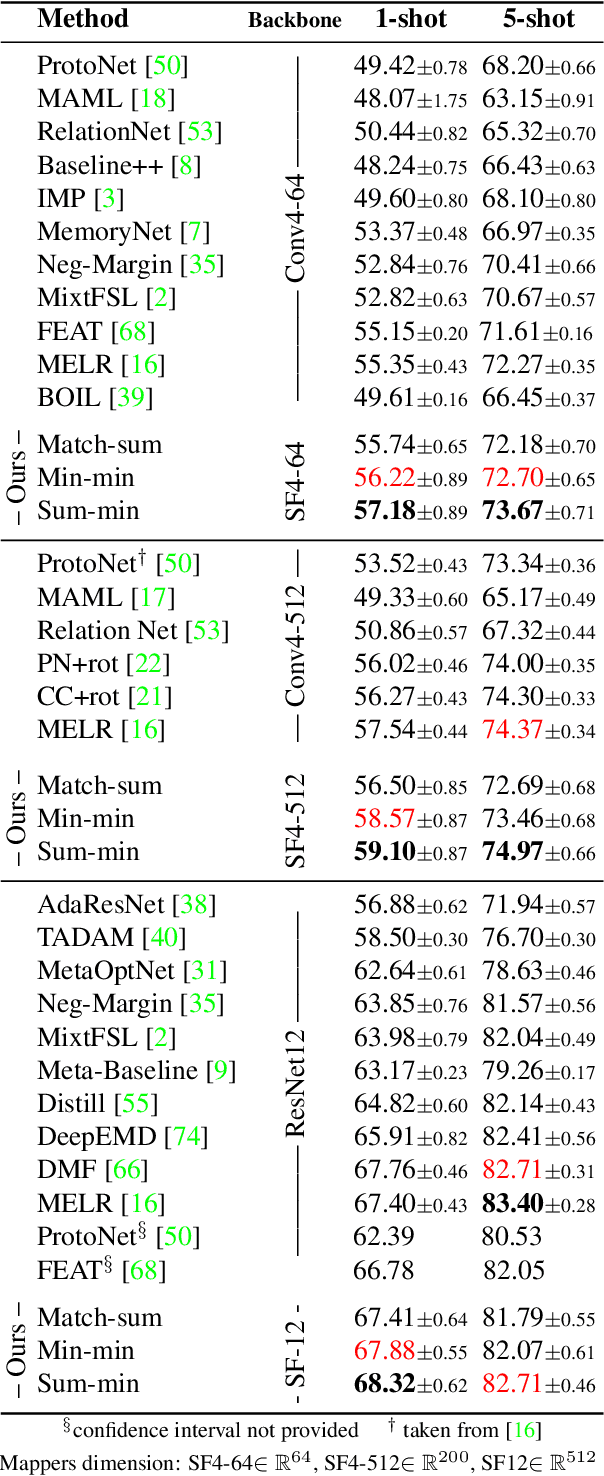
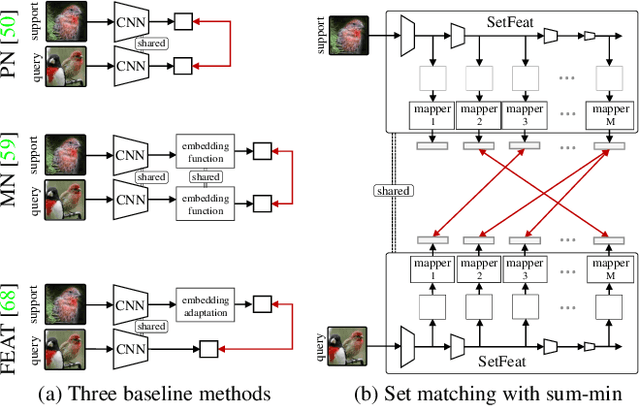
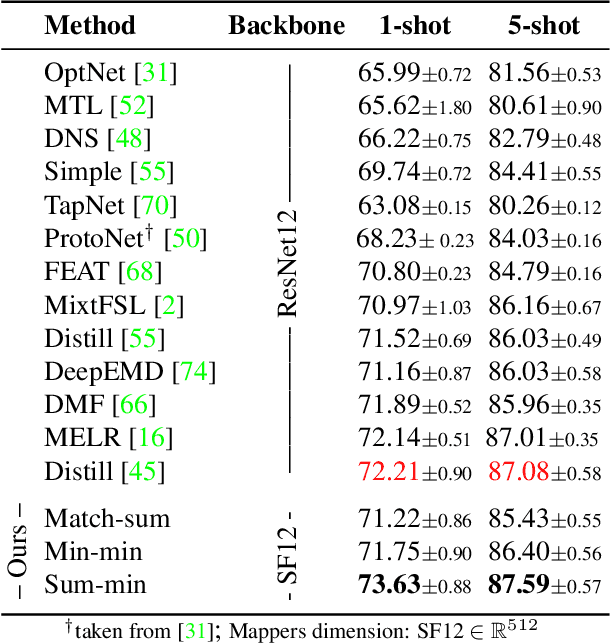
In image classification, it is common practice to train deep networks to extract a single feature vector per input image. Few-shot classification methods also mostly follow this trend. In this work, we depart from this established direction and instead propose to extract sets of feature vectors for each image. We argue that a set-based representation intrinsically builds a richer representation of images from the base classes, which can subsequently better transfer to the few-shot classes. To do so, we propose to adapt existing feature extractors to instead produce sets of feature vectors from images. Our approach, dubbed SetFeat, embeds shallow self-attention mechanisms inside existing encoder architectures. The attention modules are lightweight, and as such our method results in encoders that have approximately the same number of parameters as their original versions. During training and inference, a set-to-set matching metric is used to perform image classification. The effectiveness of our proposed architecture and metrics is demonstrated via thorough experiments on standard few-shot datasets -- namely miniImageNet, tieredImageNet, and CUB -- in both the 1- and 5-shot scenarios. In all cases but one, our method outperforms the state-of-the-art.
Persistent Mixture Model Networks for Few-Shot Image Classification
Nov 24, 2020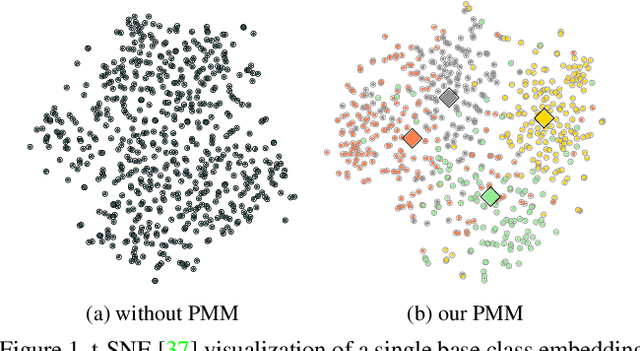
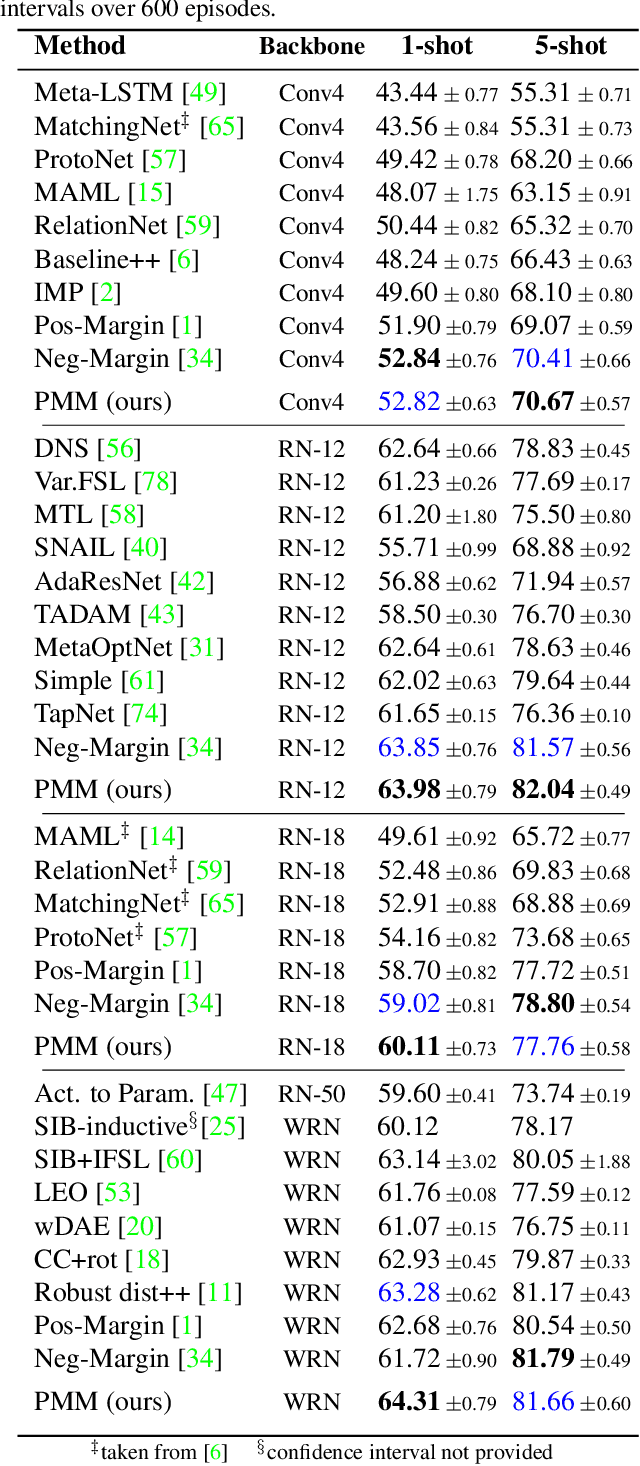
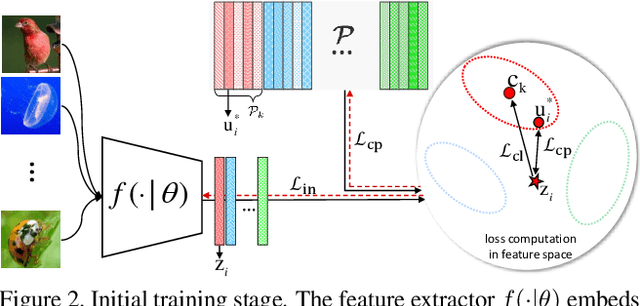
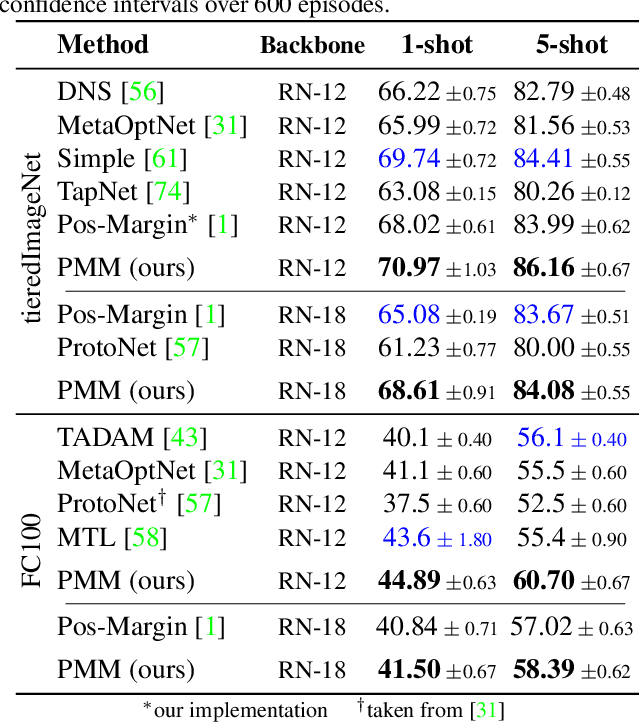
We introduce Persistent Mixture Model (PMM) networks for representation learning in the few-shot image classification context. While previous methods represent classes with a single centroid or rely on post hoc clustering methods, our method learns a mixture model for each base class jointly with the data representation in an end-to-end manner. The PMM training algorithm is organized into two main stages: 1) initial training and 2) progressive following. First, the initial estimate for multi-component mixtures is learned for each class in the base domain using a combination of two loss functions (competitive and collaborative). The resulting network is then progressively refined through a leader-follower learning procedure, which uses the current estimate of the learner as a fixed "target" network. This target network is used to make a consistent assignment of instances to mixture components, in order to increase performance while stabilizing the training. The effectiveness of our joint representation/mixture learning approach is demonstrated with extensive experiments on four standard datasets and four backbones. In particular, we demonstrate that when we combine our robust representation with recent alignment- and margin-based approaches, we achieve new state-of-the-art results in the inductive setting, with an absolute accuracy for 5-shot classification of 82.45% on miniImageNet, 88.20% with tieredImageNet, and 60.70% in FC100, all using the ResNet-12 backbone.
Associative Alignment for Few-shot Image Classification
Dec 11, 2019
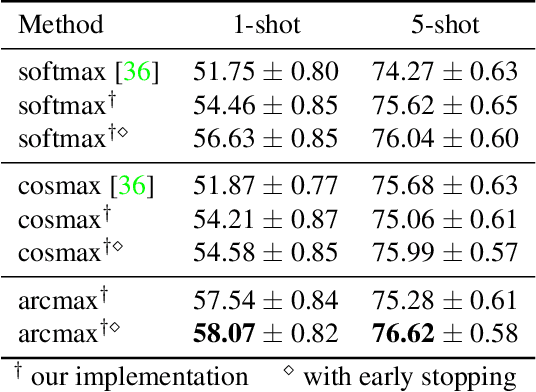

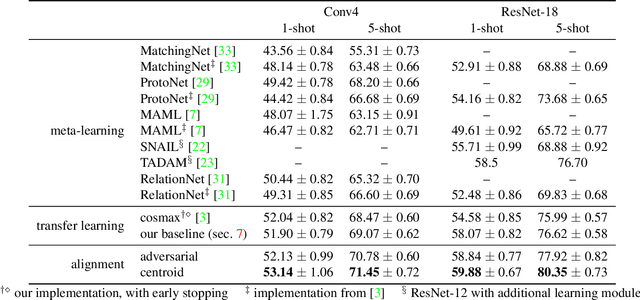
Few-shot image classification aims at training a model by using only a few (e.g., 5 or even 1) examples of novel classes. The established way of doing so is to rely on a larger set of base data for either pre-training a model, or for training in a meta-learning context. Unfortunately, these approaches often suffer from overfitting since the models can easily memorize all of the novel samples. This paper mitigates this issue and proposes to leverage part of the base data by aligning the novel training instances to the closely related ones in the base training set. This expands the size of the effective novel training set by adding extra related base instances to the few novel ones, thereby allowing to train the entire network. Doing so limits overfitting and simultaneously strengthens the generalization capabilities of the network. We propose two associative alignment strategies: 1) a conditional adversarial alignment loss based on the Wasserstein distance; and 2) a metric-learning loss for minimizing the distance between related base samples and the centroid of novel instances in the feature space. Experiments on two standard datasets demonstrate that combining our centroid-based alignment loss results in absolute accuracy improvements of 4.4%, 1.2%, and 6.0% in 5-shot learning over the state of the art for object recognition, fine-grained classification, and cross-domain adaptation, respectively.
Energy Saving Additive Neural Network
Feb 09, 2017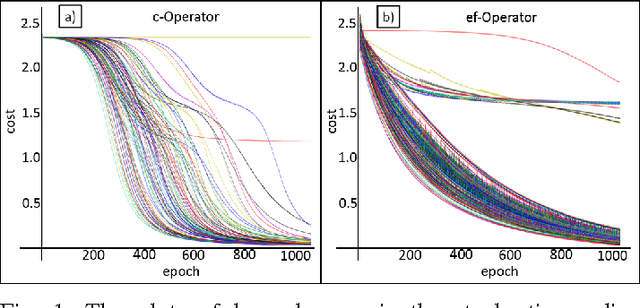
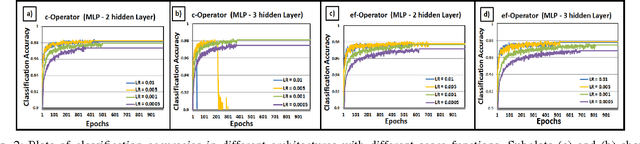
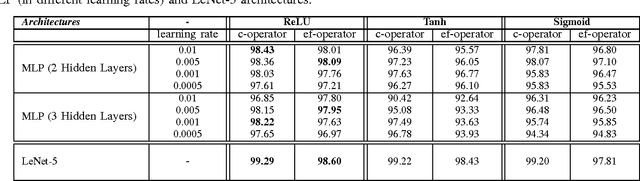
In recent years, machine learning techniques based on neural networks for mobile computing become increasingly popular. Classical multi-layer neural networks require matrix multiplications at each stage. Multiplication operation is not an energy efficient operation and consequently it drains the battery of the mobile device. In this paper, we propose a new energy efficient neural network with the universal approximation property over space of Lebesgue integrable functions. This network, called, additive neural network, is very suitable for mobile computing. The neural structure is based on a novel vector product definition, called ef-operator, that permits a multiplier-free implementation. In ef-operation, the "product" of two real numbers is defined as the sum of their absolute values, with the sign determined by the sign of the product of the numbers. This "product" is used to construct a vector product in $R^N$. The vector product induces the $l_1$ norm. The proposed additive neural network successfully solves the XOR problem. The experiments on MNIST dataset show that the classification performances of the proposed additive neural networks are very similar to the corresponding multi-layer perceptron and convolutional neural networks (LeNet).