 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDarSwin-Unet: Distortion Aware Encoder-Decoder Architecture
Jul 24, 2024



Wide-angle fisheye images are becoming increasingly common for perception tasks in applications such as robotics, security, and mobility (e.g. drones, avionics). However, current models often either ignore the distortions in wide-angle images or are not suitable to perform pixel-level tasks. In this paper, we present an encoder-decoder model based on a radial transformer architecture that adapts to distortions in wide-angle lenses by leveraging the physical characteristics defined by the radial distortion profile. In contrast to the original model, which only performs classification tasks, we introduce a U-Net architecture, DarSwin-Unet, designed for pixel level tasks. Furthermore, we propose a novel strategy that minimizes sparsity when sampling the image for creating its input tokens. Our approach enhances the model capability to handle pixel-level tasks in wide-angle fisheye images, making it more effective for real-world applications. Compared to other baselines, DarSwin-Unet achieves the best results across different datasets, with significant gains when trained on bounded levels of distortions (very low, low, medium, and high) and tested on all, including out-of-distribution distortions. We demonstrate its performance on depth estimation and show through extensive experiments that DarSwin-Unet can perform zero-shot adaptation to unseen distortions of different wide-angle lenses.
DarSwin: Distortion Aware Radial Swin Transformer
Apr 19, 2023
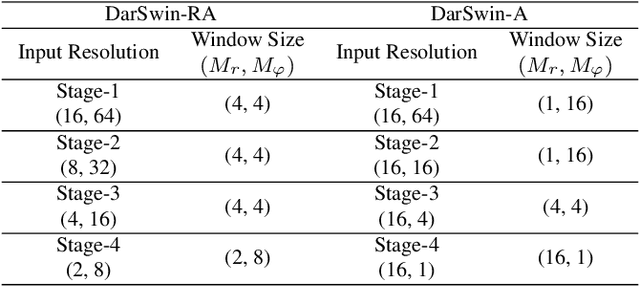

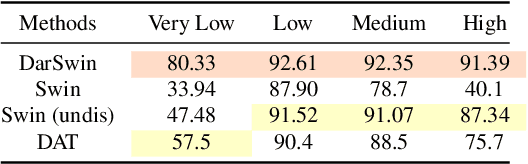
Wide-angle lenses are commonly used in perception tasks requiring a large field of view. Unfortunately, these lenses produce significant distortions making conventional models that ignore the distortion effects unable to adapt to wide-angle images. In this paper, we present a novel transformer-based model that automatically adapts to the distortion produced by wide-angle lenses. We leverage the physical characteristics of such lenses, which are analytically defined by the radial distortion profile (assumed to be known), to develop a distortion aware radial swin transformer (DarSwin). In contrast to conventional transformer-based architectures, DarSwin comprises a radial patch partitioning, a distortion-based sampling technique for creating token embeddings, and a polar position encoding for radial patch merging. We validate our method on classification tasks using synthetically distorted ImageNet data and show through extensive experiments that DarSwin can perform zero-shot adaptation to unseen distortions of different wide-angle lenses. Compared to other baselines, DarSwin achieves the best results (in terms of Top-1 and -5 accuracy), when tested on in-distribution data, with almost 2% (6%) gain in Top-1 accuracy under medium (high) distortion levels, and comparable to the state-of-the-art under low and very low distortion levels (perspective-like images).