 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuaRK: A Quantum Reservoir Kernel for Time Series Learning
Feb 14, 2026Quantum reservoir computing offers a promising route for time series learning by modelling sequential data via rich quantum dynamics while the only training required happens at the level of a lightweight classical readout. However, studies featuring efficient and implementable quantum reservoir architectures along with model learning guarantees remain scarce in the literature. To close this gap, we introduce QuaRK, an end-to-end framework that couples a hardware-realistic quantum reservoir featurizer with a kernel-based readout scheme. Given a sequence of sample points, the reservoir injects the points one after the other to yield a compact feature vector from efficiently measured k-local observables using classical shadow tomography, after which a classical kernel-based readout learns the target mapping with explicit regularization and fast optimization. The resulting pipeline exposes clear computational knobs -- circuit width and depth as well as the measurement budget -- while preserving the flexibility of kernel methods to model nonlinear temporal functionals and being scalable to high-dimensional data. We further provide learning-theoretic generalization guarantees for dependent temporal data, linking design and resource choices to finite-sample performance, thereby offering principled guidance for building reliable temporal learners. Empirical experiments validate QuaRK and illustrate the predicted interpolation and generalization behaviours on synthetic beta-mixing time series tasks.
Quantum Gated Recurrent GAN with Gaussian Uncertainty for Network Anomaly Detection
Oct 30, 2025Anomaly detection in time-series data is a critical challenge with significant implications for network security. Recent quantum machine learning approaches, such as quantum kernel methods and variational quantum circuits, have shown promise in capturing complex data distributions for anomaly detection but remain constrained by limited qubit counts. We introduce in this work a novel Quantum Gated Recurrent Unit (QGRU)-based Generative Adversarial Network (GAN) employing Successive Data Injection (SuDaI) and a multi-metric gating strategy for robust network anomaly detection. Our model uniquely utilizes a quantum-enhanced generator that outputs parameters (mean and log-variance) of a Gaussian distribution via reparameterization, combined with a Wasserstein critic to stabilize adversarial training. Anomalies are identified through a novel gating mechanism that initially flags potential anomalies based on Gaussian uncertainty estimates and subsequently verifies them using a composite of critic scores and reconstruction errors. Evaluated on benchmark datasets, our method achieves a high time-series aware F1 score (TaF1) of 89.43% demonstrating superior capability in detecting anomalies accurately and promptly as compared to existing classical and quantum models. Furthermore, the trained QGRU-WGAN was deployed on real IBM Quantum hardware, where it retained high anomaly detection performance, confirming its robustness and practical feasibility on current noisy intermediate-scale quantum (NISQ) devices.
ProMi: An Efficient Prototype-Mixture Baseline for Few-Shot Segmentation with Bounding-Box Annotations
May 18, 2025

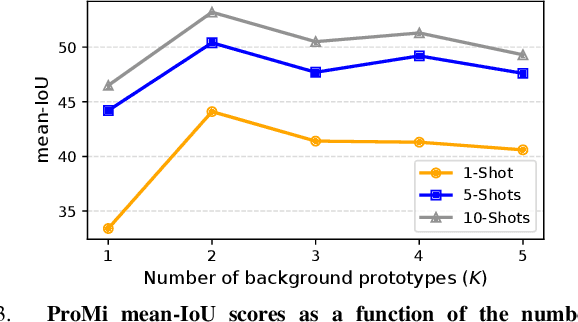

In robotics applications, few-shot segmentation is crucial because it allows robots to perform complex tasks with minimal training data, facilitating their adaptation to diverse, real-world environments. However, pixel-level annotations of even small amount of images is highly time-consuming and costly. In this paper, we present a novel few-shot binary segmentation method based on bounding-box annotations instead of pixel-level labels. We introduce, ProMi, an efficient prototype-mixture-based method that treats the background class as a mixture of distributions. Our approach is simple, training-free, and effective, accommodating coarse annotations with ease. Compared to existing baselines, ProMi achieves the best results across different datasets with significant gains, demonstrating its effectiveness. Furthermore, we present qualitative experiments tailored to real-world mobile robot tasks, demonstrating the applicability of our approach in such scenarios. Our code: https://github.com/ThalesGroup/promi.
QuaCK-TSF: Quantum-Classical Kernelized Time Series Forecasting
Aug 21, 2024



Forecasting in probabilistic time series is a complex endeavor that extends beyond predicting future values to also quantifying the uncertainty inherent in these predictions. Gaussian process regression stands out as a Bayesian machine learning technique adept at addressing this multifaceted challenge. This paper introduces a novel approach that blends the robustness of this Bayesian technique with the nuanced insights provided by the kernel perspective on quantum models, aimed at advancing quantum kernelized probabilistic forecasting. We incorporate a quantum feature map inspired by Ising interactions and demonstrate its effectiveness in capturing the temporal dependencies critical for precise forecasting. The optimization of our model's hyperparameters circumvents the need for computationally intensive gradient descent by employing gradient-free Bayesian optimization. Comparative benchmarks against established classical kernel models are provided, affirming that our quantum-enhanced approach achieves competitive performance.
DarSwin-Unet: Distortion Aware Encoder-Decoder Architecture
Jul 24, 2024



Wide-angle fisheye images are becoming increasingly common for perception tasks in applications such as robotics, security, and mobility (e.g. drones, avionics). However, current models often either ignore the distortions in wide-angle images or are not suitable to perform pixel-level tasks. In this paper, we present an encoder-decoder model based on a radial transformer architecture that adapts to distortions in wide-angle lenses by leveraging the physical characteristics defined by the radial distortion profile. In contrast to the original model, which only performs classification tasks, we introduce a U-Net architecture, DarSwin-Unet, designed for pixel level tasks. Furthermore, we propose a novel strategy that minimizes sparsity when sampling the image for creating its input tokens. Our approach enhances the model capability to handle pixel-level tasks in wide-angle fisheye images, making it more effective for real-world applications. Compared to other baselines, DarSwin-Unet achieves the best results across different datasets, with significant gains when trained on bounded levels of distortions (very low, low, medium, and high) and tested on all, including out-of-distribution distortions. We demonstrate its performance on depth estimation and show through extensive experiments that DarSwin-Unet can perform zero-shot adaptation to unseen distortions of different wide-angle lenses.
Neural Active Learning Meets the Partial Monitoring Framework
May 14, 2024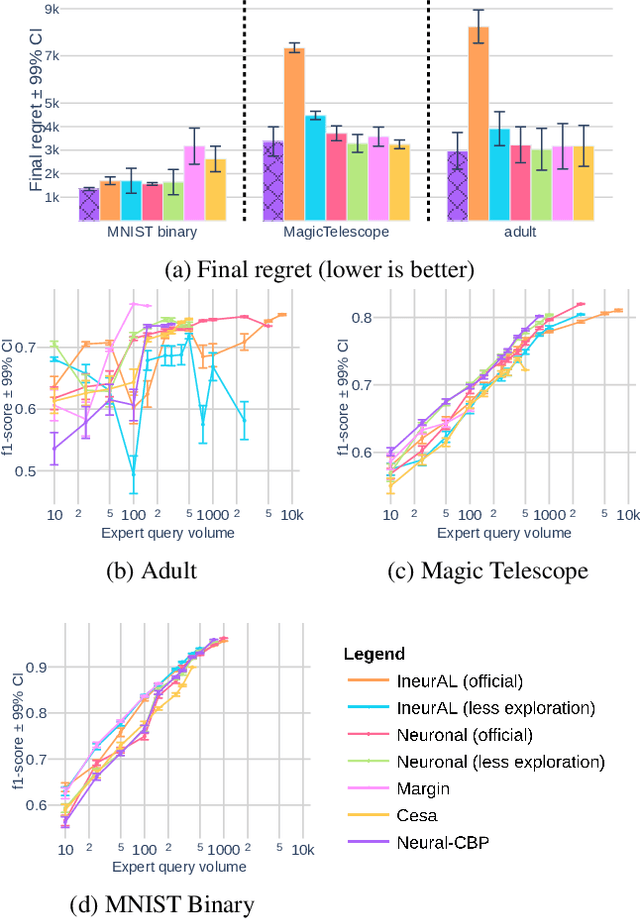
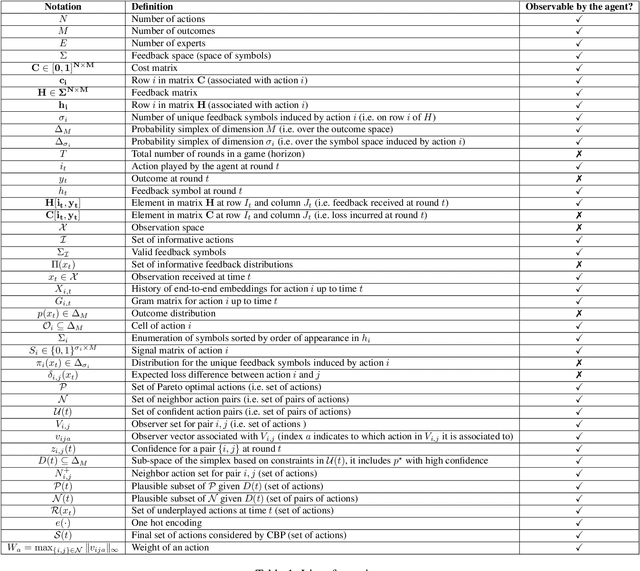
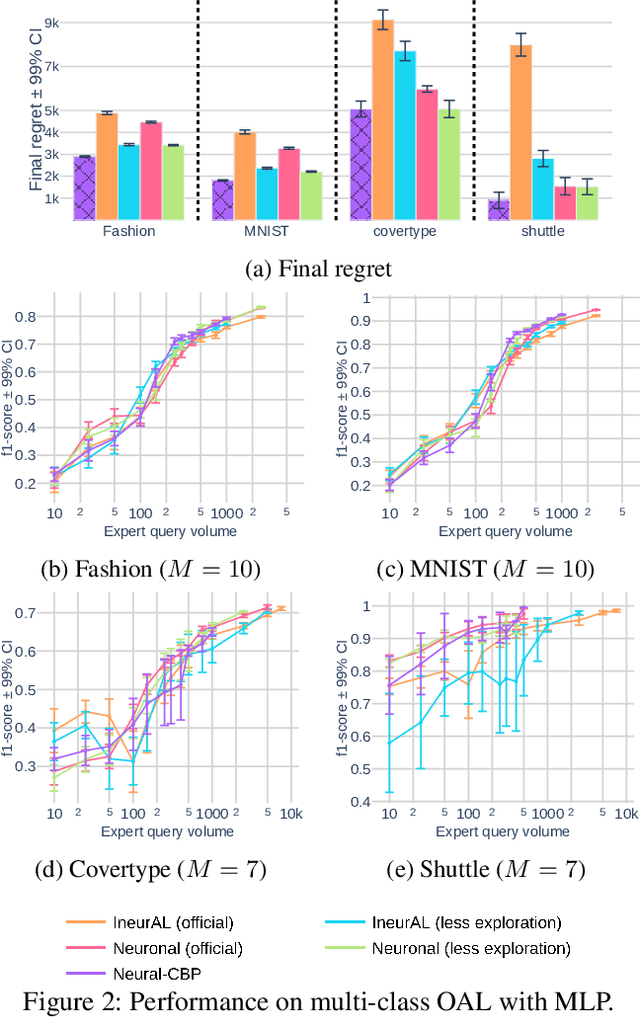
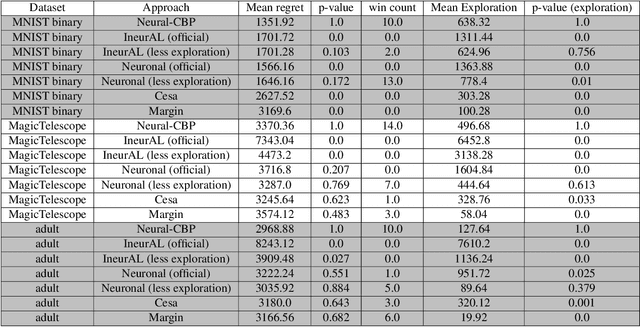
We focus on the online-based active learning (OAL) setting where an agent operates over a stream of observations and trades-off between the costly acquisition of information (labelled observations) and the cost of prediction errors. We propose a novel foundation for OAL tasks based on partial monitoring, a theoretical framework specialized in online learning from partially informative actions. We show that previously studied binary and multi-class OAL tasks are instances of partial monitoring. We expand the real-world potential of OAL by introducing a new class of cost-sensitive OAL tasks. We propose NeuralCBP, the first PM strategy that accounts for predictive uncertainty with deep neural networks. Our extensive empirical evaluation on open source datasets shows that NeuralCBP has favorable performance against state-of-the-art baselines on multiple binary, multi-class and cost-sensitive OAL tasks.
Randomized Confidence Bounds for Stochastic Partial Monitoring
Feb 07, 2024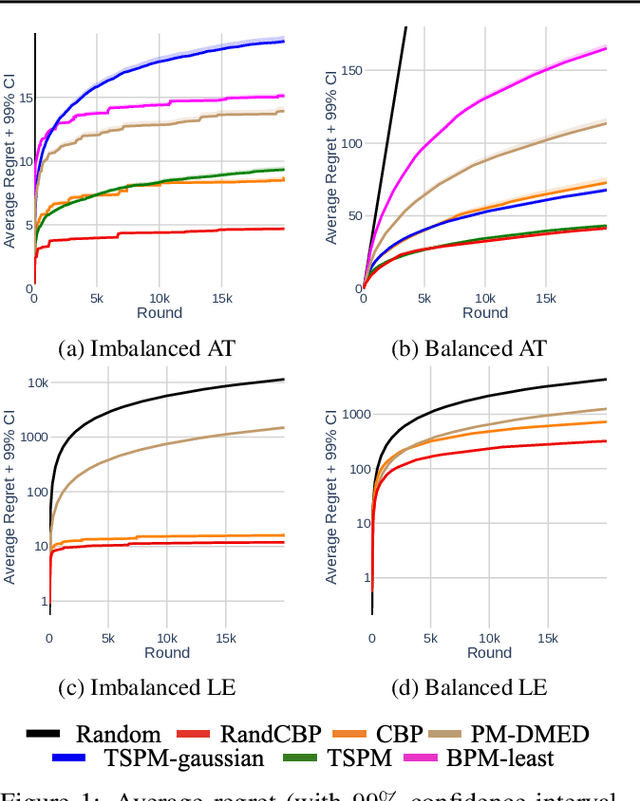
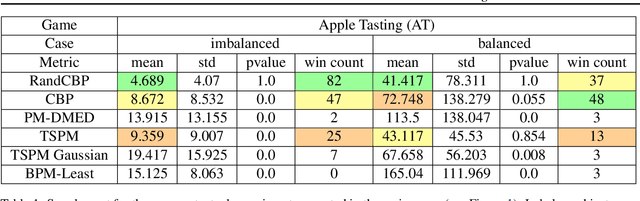
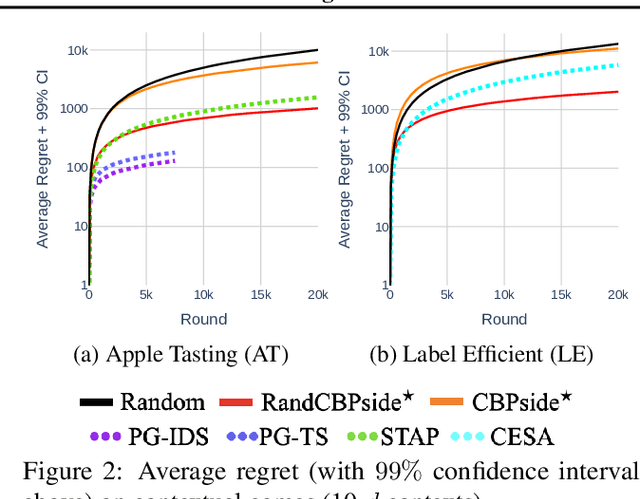

The partial monitoring (PM) framework provides a theoretical formulation of sequential learning problems with incomplete feedback. On each round, a learning agent plays an action while the environment simultaneously chooses an outcome. The agent then observes a feedback signal that is only partially informative about the (unobserved) outcome. The agent leverages the received feedback signals to select actions that minimize the (unobserved) cumulative loss. In contextual PM, the outcomes depend on some side information that is observable by the agent before selecting the action on each round. In this paper, we consider the contextual and non-contextual PM settings with stochastic outcomes. We introduce a new class of strategies based on the randomization of deterministic confidence bounds, that extend regret guarantees to settings where existing stochastic strategies are not applicable. Our experiments show that the proposed RandCBP and RandCBPside* strategies improve state-of-the-art baselines in PM games. To encourage the adoption of the PM framework, we design a use case on the real-world problem of monitoring the error rate of any deployed classification system.
Successive Data Injection in Conditional Quantum GAN Applied to Time Series Anomaly Detection
Oct 08, 2023Classical GAN architectures have shown interesting results for solving anomaly detection problems in general and for time series anomalies in particular, such as those arising in communication networks. In recent years, several quantum GAN architectures have been proposed in the literature. When detecting anomalies in time series using QGANs, huge challenges arise due to the limited number of qubits compared to the size of the data. To address these challenges, we propose a new high-dimensional encoding approach, named Successive Data Injection (SuDaI). In this approach, we explore a larger portion of the quantum state than that in the conventional angle encoding, the method used predominantly in the literature, through repeated data injections into the quantum state. SuDaI encoding allows us to adapt the QGAN for anomaly detection with network data of a much higher dimensionality than with the existing known QGANs implementations. In addition, SuDaI encoding applies to other types of high-dimensional time series and can be used in contexts beyond anomaly detection and QGANs, opening up therefore multiple fields of application.
MoP-CLIP: A Mixture of Prompt-Tuned CLIP Models for Domain Incremental Learning
Jul 11, 2023



Despite the recent progress in incremental learning, addressing catastrophic forgetting under distributional drift is still an open and important problem. Indeed, while state-of-the-art domain incremental learning (DIL) methods perform satisfactorily within known domains, their performance largely degrades in the presence of novel domains. This limitation hampers their generalizability, and restricts their scalability to more realistic settings where train and test data are drawn from different distributions. To address these limitations, we present a novel DIL approach based on a mixture of prompt-tuned CLIP models (MoP-CLIP), which generalizes the paradigm of S-Prompting to handle both in-distribution and out-of-distribution data at inference. In particular, at the training stage we model the features distribution of every class in each domain, learning individual text and visual prompts to adapt to a given domain. At inference, the learned distributions allow us to identify whether a given test sample belongs to a known domain, selecting the correct prompt for the classification task, or from an unseen domain, leveraging a mixture of the prompt-tuned CLIP models. Our empirical evaluation reveals the poor performance of existing DIL methods under domain shift, and suggests that the proposed MoP-CLIP performs competitively in the standard DIL settings while outperforming state-of-the-art methods in OOD scenarios. These results demonstrate the superiority of MoP-CLIP, offering a robust and general solution to the problem of domain incremental learning.
Causal Analysis for Robust Interpretability of Neural Networks
May 15, 2023



Interpreting the inner function of neural networks is crucial for the trustworthy development and deployment of these black-box models. Prior interpretability methods focus on correlation-based measures to attribute model decisions to individual examples. However, these measures are susceptible to noise and spurious correlations encoded in the model during the training phase (e.g., biased inputs, model overfitting, or misspecification). Moreover, this process has proven to result in noisy and unstable attributions that prevent any transparent understanding of the model's behavior. In this paper, we develop a robust interventional-based method grounded by causal analysis to capture cause-effect mechanisms in pre-trained neural networks and their relation to the prediction. Our novel approach relies on path interventions to infer the causal mechanisms within hidden layers and isolate relevant and necessary information (to model prediction), avoiding noisy ones. The result is task-specific causal explanatory graphs that can audit model behavior and express the actual causes underlying its performance. We apply our method to vision models trained on classification tasks. On image classification tasks, we provide extensive quantitative experiments to show that our approach can capture more stable and faithful explanations than standard attribution-based methods. Furthermore, the underlying causal graphs reveal the neural interactions in the model, making it a valuable tool in other applications (e.g., model repair).