 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Federated Graph-Filtering for Recommender Systems
Jan 28, 2025Recommender systems often rely on graph-based filters, such as normalized item-item adjacency matrices and low-pass filters. While effective, the centralized computation of these components raises concerns about privacy, security, and the ethical use of user data. This work proposes two decentralized frameworks for securely computing these critical graph components without centralizing sensitive information. The first approach leverages lightweight Multi-Party Computation and distributed singular vector computations to privately compute key graph filters. The second extends this framework by incorporating low-rank approximations, enabling a trade-off between communication efficiency and predictive performance. Empirical evaluations on benchmark datasets demonstrate that the proposed methods achieve comparable accuracy to centralized state-of-the-art systems while ensuring data confidentiality and maintaining low communication costs. Our results highlight the potential for privacy-preserving decentralized architectures to bridge the gap between utility and user data protection in modern recommender systems.
Scrutinizing the Vulnerability of Decentralized Learning to Membership Inference Attacks
Dec 17, 2024



The primary promise of decentralized learning is to allow users to engage in the training of machine learning models in a collaborative manner while keeping their data on their premises and without relying on any central entity. However, this paradigm necessitates the exchange of model parameters or gradients between peers. Such exchanges can be exploited to infer sensitive information about training data, which is achieved through privacy attacks (e.g Membership Inference Attacks -- MIA). In order to devise effective defense mechanisms, it is important to understand the factors that increase/reduce the vulnerability of a given decentralized learning architecture to MIA. In this study, we extensively explore the vulnerability to MIA of various decentralized learning architectures by varying the graph structure (e.g number of neighbors), the graph dynamics, and the aggregation strategy, across diverse datasets and data distributions. Our key finding, which to the best of our knowledge we are the first to report, is that the vulnerability to MIA is heavily correlated to (i) the local model mixing strategy performed by each node upon reception of models from neighboring nodes and (ii) the global mixing properties of the communication graph. We illustrate these results experimentally using four datasets and by theoretically analyzing the mixing properties of various decentralized architectures. Our paper draws a set of lessons learned for devising decentralized learning systems that reduce by design the vulnerability to MIA.
Differentially private and decentralized randomized power method
Nov 04, 2024
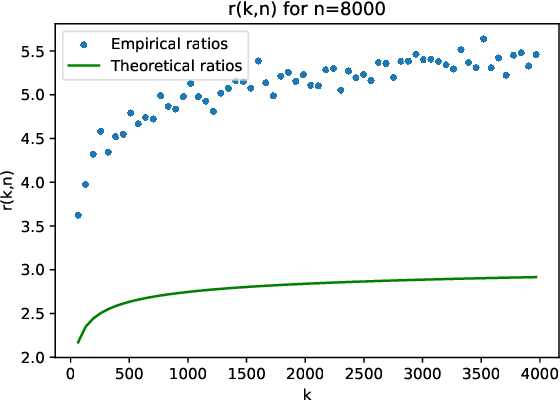
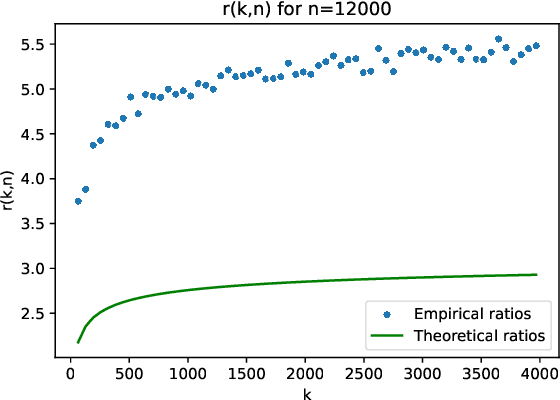

The randomized power method has gained significant interest due to its simplicity and efficient handling of large-scale spectral analysis and recommendation tasks. As modern datasets contain sensitive private information, we need to give formal guarantees on the possible privacy leaks caused by this method. This paper focuses on enhancing privacy preserving variants of the method. We propose a strategy to reduce the variance of the noise introduced to achieve Differential Privacy (DP). We also adapt the method to a decentralized framework with a low computational and communication overhead, while preserving the accuracy. We leverage Secure Aggregation (a form of Multi-Party Computation) to allow the algorithm to perform computations using data distributed among multiple users or devices, without revealing individual data. We show that it is possible to use a noise scale in the decentralized setting that is similar to the one in the centralized setting. We improve upon existing convergence bounds for both the centralized and decentralized versions. The proposed method is especially relevant for decentralized applications such as distributed recommender systems, where privacy concerns are paramount.
MoP-CLIP: A Mixture of Prompt-Tuned CLIP Models for Domain Incremental Learning
Jul 11, 2023



Despite the recent progress in incremental learning, addressing catastrophic forgetting under distributional drift is still an open and important problem. Indeed, while state-of-the-art domain incremental learning (DIL) methods perform satisfactorily within known domains, their performance largely degrades in the presence of novel domains. This limitation hampers their generalizability, and restricts their scalability to more realistic settings where train and test data are drawn from different distributions. To address these limitations, we present a novel DIL approach based on a mixture of prompt-tuned CLIP models (MoP-CLIP), which generalizes the paradigm of S-Prompting to handle both in-distribution and out-of-distribution data at inference. In particular, at the training stage we model the features distribution of every class in each domain, learning individual text and visual prompts to adapt to a given domain. At inference, the learned distributions allow us to identify whether a given test sample belongs to a known domain, selecting the correct prompt for the classification task, or from an unseen domain, leveraging a mixture of the prompt-tuned CLIP models. Our empirical evaluation reveals the poor performance of existing DIL methods under domain shift, and suggests that the proposed MoP-CLIP performs competitively in the standard DIL settings while outperforming state-of-the-art methods in OOD scenarios. These results demonstrate the superiority of MoP-CLIP, offering a robust and general solution to the problem of domain incremental learning.