 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiskard : Byzantine Robust and Confidential Aggregation for Large-Scale Decentralized Learning
Jun 17, 2026Dealing simultaneously with confidentiality and Byzantine behaviors in decentralized learning is a challenging problem. Indeed, in decentralized learning, clients train a machine learning model while keeping their data locally and share their model parameters or gradients with a set of neighbors. While enforcing confidentiality calls for hiding the exchanged model parameters/gradients (e.g., by using cryptographic techniques), dealing with Byzantine contributions often requires inspecting the latter. Hence, most research works address these objectives separately. A recent line of work proposes to employ secure multi-party computation (MPC) to implement robust aggregators against model poisoning, thereby enforcing both confidentiality and Byzantine resilience. However, these solutions scale badly: they either require all-to-all communication between participants or delegate the entire computation to a small subset, whose computational and communication load grows proportionally with the size of the network. In this paper, we present Giskard, a protocol for confidential and Byzantine-robust decentralized aggregation. Giskard organizes $n$ parties into a tree of committees of size $O(\log n)$ and evaluates a coordinate-wise approximate median via a committee-adapted distributed binary search over the value domain, using BGW-style MPC within each committee. We assess Giskard both theoretically by proving its security and confidentiality properties and experimentally through extensive experiments involving up to one million participants. Compared to its closest competitors, Giskard reduces per-party communication complexity asymptotically while exhibiting comparable model utility under up to $n/4$ Byzantine parties.
Dropout-Robust Mechanisms for Differentially Private and Fully Decentralized Mean Estimation
Jun 04, 2025Achieving differentially private computations in decentralized settings poses significant challenges, particularly regarding accuracy, communication cost, and robustness against information leakage. While cryptographic solutions offer promise, they often suffer from high communication overhead or require centralization in the presence of network failures. Conversely, existing fully decentralized approaches typically rely on relaxed adversarial models or pairwise noise cancellation, the latter suffering from substantial accuracy degradation if parties unexpectedly disconnect. In this work, we propose IncA, a new protocol for fully decentralized mean estimation, a widely used primitive in data-intensive processing. Our protocol, which enforces differential privacy, requires no central orchestration and employs low-variance correlated noise, achieved by incrementally injecting sensitive information into the computation. First, we theoretically demonstrate that, when no parties permanently disconnect, our protocol achieves accuracy comparable to that of a centralized setting-already an improvement over most existing decentralized differentially private techniques. Second, we empirically show that our use of low-variance correlated noise significantly mitigates the accuracy loss experienced by existing techniques in the presence of dropouts.
Secure Federated Graph-Filtering for Recommender Systems
Jan 28, 2025Recommender systems often rely on graph-based filters, such as normalized item-item adjacency matrices and low-pass filters. While effective, the centralized computation of these components raises concerns about privacy, security, and the ethical use of user data. This work proposes two decentralized frameworks for securely computing these critical graph components without centralizing sensitive information. The first approach leverages lightweight Multi-Party Computation and distributed singular vector computations to privately compute key graph filters. The second extends this framework by incorporating low-rank approximations, enabling a trade-off between communication efficiency and predictive performance. Empirical evaluations on benchmark datasets demonstrate that the proposed methods achieve comparable accuracy to centralized state-of-the-art systems while ensuring data confidentiality and maintaining low communication costs. Our results highlight the potential for privacy-preserving decentralized architectures to bridge the gap between utility and user data protection in modern recommender systems.
Scrutinizing the Vulnerability of Decentralized Learning to Membership Inference Attacks
Dec 17, 2024



The primary promise of decentralized learning is to allow users to engage in the training of machine learning models in a collaborative manner while keeping their data on their premises and without relying on any central entity. However, this paradigm necessitates the exchange of model parameters or gradients between peers. Such exchanges can be exploited to infer sensitive information about training data, which is achieved through privacy attacks (e.g Membership Inference Attacks -- MIA). In order to devise effective defense mechanisms, it is important to understand the factors that increase/reduce the vulnerability of a given decentralized learning architecture to MIA. In this study, we extensively explore the vulnerability to MIA of various decentralized learning architectures by varying the graph structure (e.g number of neighbors), the graph dynamics, and the aggregation strategy, across diverse datasets and data distributions. Our key finding, which to the best of our knowledge we are the first to report, is that the vulnerability to MIA is heavily correlated to (i) the local model mixing strategy performed by each node upon reception of models from neighboring nodes and (ii) the global mixing properties of the communication graph. We illustrate these results experimentally using four datasets and by theoretically analyzing the mixing properties of various decentralized architectures. Our paper draws a set of lessons learned for devising decentralized learning systems that reduce by design the vulnerability to MIA.
Differentially private and decentralized randomized power method
Nov 04, 2024
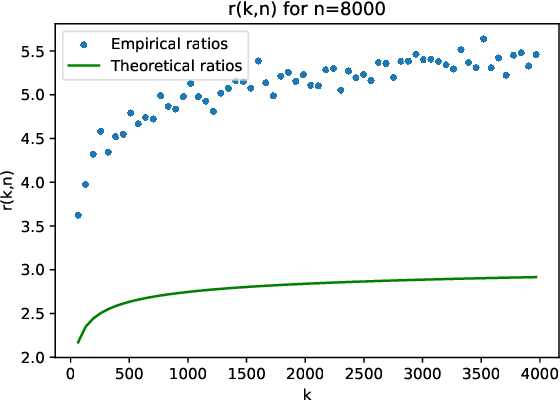
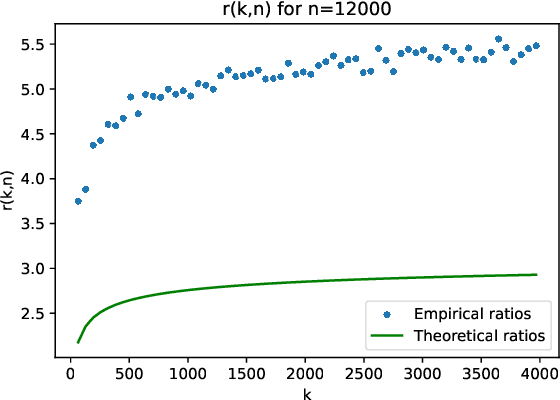

The randomized power method has gained significant interest due to its simplicity and efficient handling of large-scale spectral analysis and recommendation tasks. As modern datasets contain sensitive private information, we need to give formal guarantees on the possible privacy leaks caused by this method. This paper focuses on enhancing privacy preserving variants of the method. We propose a strategy to reduce the variance of the noise introduced to achieve Differential Privacy (DP). We also adapt the method to a decentralized framework with a low computational and communication overhead, while preserving the accuracy. We leverage Secure Aggregation (a form of Multi-Party Computation) to allow the algorithm to perform computations using data distributed among multiple users or devices, without revealing individual data. We show that it is possible to use a noise scale in the decentralized setting that is similar to the one in the centralized setting. We improve upon existing convergence bounds for both the centralized and decentralized versions. The proposed method is especially relevant for decentralized applications such as distributed recommender systems, where privacy concerns are paramount.
Distributed Differentially Private Averaging with Improved Utility and Robustness to Malicious Parties
Jun 12, 2020

Learning from data owned by several parties, as in federated learning, raises challenges regarding the privacy guarantees provided to participants and the correctness of the computation in the presence of malicious parties. We tackle these challenges in the context of distributed averaging, an essential building block of distributed and federated learning. Our first contribution is a novel distributed differentially private protocol which naturally scales with the number of parties. The key idea underlying our protocol is to exchange correlated Gaussian noise along the edges of a network graph, complemented by independent noise added by each party. We analyze the differential privacy guarantees of our protocol and the impact of the graph topology, showing that we can match the accuracy of the trusted curator model even when each party communicates with only a logarithmic number of other parties chosen at random. This is in contrast with protocols in the local model of privacy (with lower accuracy) or based on secure aggregation (where all pairs of users need to exchange messages). Our second contribution is to enable users to prove the correctness of their computations without compromising the efficiency and privacy guarantees of the protocol. Our construction relies on standard cryptographic primitives like commitment schemes and zero knowledge proofs.