 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate, private, secure, federated U-statistics with higher degree
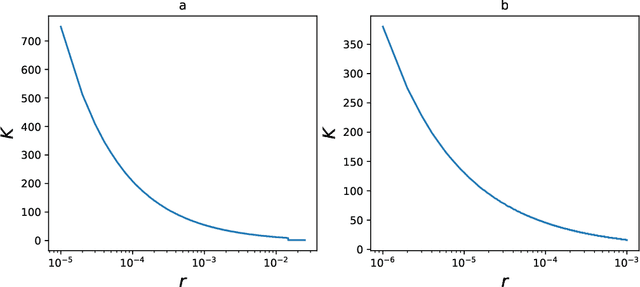
Mar 02, 2026We study the problem of computing a U-statistic with a kernel function f of degree k $\ge$ 2, i.e., the average of some function f over all k-tuples of instances, in a federated learning setting. Ustatistics of degree 2 include several useful statistics such as Kendall's $τ$ coefficient, the Area under the Receiver-Operator Curve and the Gini mean difference. Existing methods provide solutions only under the lower-utility local differential privacy model and/or scale poorly in the size of the domain discretization. In this work, we propose a protocol that securely computes U-statistics of degree k $\ge$ 2 under central differential privacy by leveraging Multi Party Computation (MPC). Our method substantially improves accuracy when compared to prior solutions. We provide a detailed theoretical analysis of its accuracy, communication and computational properties. We evaluate its performance empirically, obtaining favorable results, e.g., for Kendall's $τ$ coefficient, our approach reduces the Mean Squared Error by up to four orders of magnitude over existing baselines.
Gradient Projection onto Historical Descent Directions for Communication-Efficient Federated Learning
Nov 05, 2025Federated Learning (FL) enables decentralized model training across multiple clients while optionally preserving data privacy. However, communication efficiency remains a critical bottleneck, particularly for large-scale models. In this work, we introduce two complementary algorithms: ProjFL, designed for unbiased compressors, and ProjFL+EF, tailored for biased compressors through an Error Feedback mechanism. Both methods rely on projecting local gradients onto a shared client-server subspace spanned by historical descent directions, enabling efficient information exchange with minimal communication overhead. We establish convergence guarantees for both algorithms under strongly convex, convex, and non-convex settings. Empirical evaluations on standard FL classification benchmarks with deep neural networks show that ProjFL and ProjFL+EF achieve accuracy comparable to existing baselines while substantially reducing communication costs.
How to Securely Shuffle? A survey about Secure Shufflers for privacy-preserving computations
Jul 02, 2025Ishai et al. (FOCS'06) introduced secure shuffling as an efficient building block for private data aggregation. Recently, the field of differential privacy has revived interest in secure shufflers by highlighting the privacy amplification they can provide in various computations. Although several works argue for the utility of secure shufflers, they often treat them as black boxes; overlooking the practical vulnerabilities and performance trade-offs of existing implementations. This leaves a central question open: what makes a good secure shuffler? This survey addresses that question by identifying, categorizing, and comparing 26 secure protocols that realize the necessary shuffling functionality. To enable a meaningful comparison, we adapt and unify existing security definitions into a consistent set of properties. We also present an overview of privacy-preserving technologies that rely on secure shufflers, offer practical guidelines for selecting appropriate protocols, and outline promising directions for future work.
Dropout-Robust Mechanisms for Differentially Private and Fully Decentralized Mean Estimation
Jun 04, 2025Achieving differentially private computations in decentralized settings poses significant challenges, particularly regarding accuracy, communication cost, and robustness against information leakage. While cryptographic solutions offer promise, they often suffer from high communication overhead or require centralization in the presence of network failures. Conversely, existing fully decentralized approaches typically rely on relaxed adversarial models or pairwise noise cancellation, the latter suffering from substantial accuracy degradation if parties unexpectedly disconnect. In this work, we propose IncA, a new protocol for fully decentralized mean estimation, a widely used primitive in data-intensive processing. Our protocol, which enforces differential privacy, requires no central orchestration and employs low-variance correlated noise, achieved by incrementally injecting sensitive information into the computation. First, we theoretically demonstrate that, when no parties permanently disconnect, our protocol achieves accuracy comparable to that of a centralized setting-already an improvement over most existing decentralized differentially private techniques. Second, we empirically show that our use of low-variance correlated noise significantly mitigates the accuracy loss experienced by existing techniques in the presence of dropouts.
SoK: Verifiable Cross-Silo FL
Oct 11, 2024


Federated Learning (FL) is a widespread approach that allows training machine learning (ML) models with data distributed across multiple devices. In cross-silo FL, which often appears in domains like healthcare or finance, the number of participants is moderate, and each party typically represents a well-known organization. For instance, in medicine data owners are often hospitals or data hubs which are well-established entities. However, malicious parties may still attempt to disturb the training procedure in order to obtain certain benefits, for example, a biased result or a reduction in computational load. While one can easily detect a malicious agent when data used for training is public, the problem becomes much more acute when it is necessary to maintain the privacy of the training dataset. To address this issue, there is recently growing interest in developing verifiable protocols, where one can check that parties do not deviate from the training procedure and perform computations correctly. In this paper, we present a systematization of knowledge on verifiable cross-silo FL. We analyze various protocols, fit them in a taxonomy, and compare their efficiency and threat models. We also analyze Zero-Knowledge Proof (ZKP) schemes and discuss how their overall cost in a FL context can be minimized. Lastly, we identify research gaps and discuss potential directions for future scientific work.
DP-SGD with weight clipping
Oct 27, 2023Recently, due to the popularity of deep neural networks and other methods whose training typically relies on the optimization of an objective function, and due to concerns for data privacy, there is a lot of interest in differentially private gradient descent methods. To achieve differential privacy guarantees with a minimum amount of noise, it is important to be able to bound precisely the sensitivity of the information which the participants will observe. In this study, we present a novel approach that mitigates the bias arising from traditional gradient clipping. By leveraging public information concerning the current global model and its location within the search domain, we can achieve improved gradient bounds, leading to enhanced sensitivity determinations and refined noise level adjustments. We extend the state of the art algorithms, present improved differential privacy guarantees requiring less noise and present an empirical evaluation.
Distributed Differentially Private Averaging with Improved Utility and Robustness to Malicious Parties
Jun 12, 2020

Learning from data owned by several parties, as in federated learning, raises challenges regarding the privacy guarantees provided to participants and the correctness of the computation in the presence of malicious parties. We tackle these challenges in the context of distributed averaging, an essential building block of distributed and federated learning. Our first contribution is a novel distributed differentially private protocol which naturally scales with the number of parties. The key idea underlying our protocol is to exchange correlated Gaussian noise along the edges of a network graph, complemented by independent noise added by each party. We analyze the differential privacy guarantees of our protocol and the impact of the graph topology, showing that we can match the accuracy of the trusted curator model even when each party communicates with only a logarithmic number of other parties chosen at random. This is in contrast with protocols in the local model of privacy (with lower accuracy) or based on secure aggregation (where all pairs of users need to exchange messages). Our second contribution is to enable users to prove the correctness of their computations without compromising the efficiency and privacy guarantees of the protocol. Our construction relies on standard cryptographic primitives like commitment schemes and zero knowledge proofs.
Hiding in the Crowd: A Massively Distributed Algorithm for Private Averaging with Malicious Adversaries
Mar 27, 2018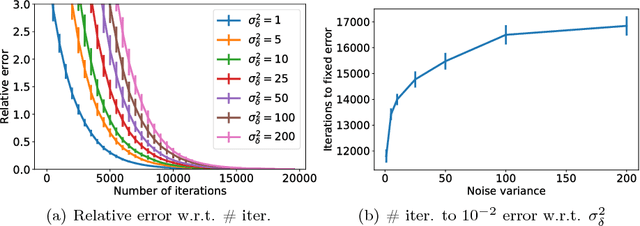
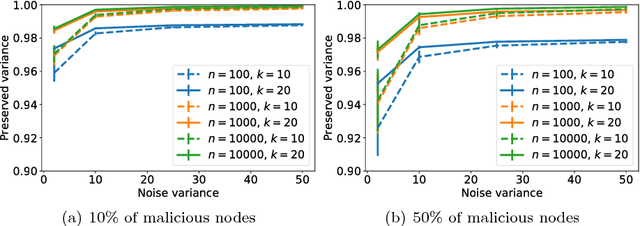
The amount of personal data collected in our everyday interactions with connected devices offers great opportunities for innovative services fueled by machine learning, as well as raises serious concerns for the privacy of individuals. In this paper, we propose a massively distributed protocol for a large set of users to privately compute averages over their joint data, which can then be used to learn predictive models. Our protocol can find a solution of arbitrary accuracy, does not rely on a third party and preserves the privacy of users throughout the execution in both the honest-but-curious and malicious adversary models. Specifically, we prove that the information observed by the adversary (the set of maliciours users) does not significantly reduce the uncertainty in its prediction of private values compared to its prior belief. The level of privacy protection depends on a quantity related to the Laplacian matrix of the network graph and generally improves with the size of the graph. Furthermore, we design a verification procedure which offers protection against malicious users joining the service with the goal of manipulating the outcome of the algorithm.
Learning from networked examples
Jun 03, 2017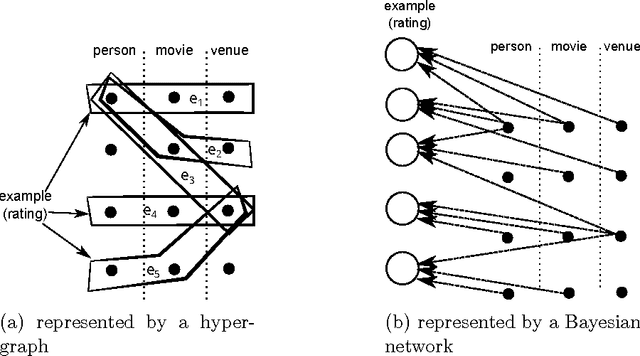
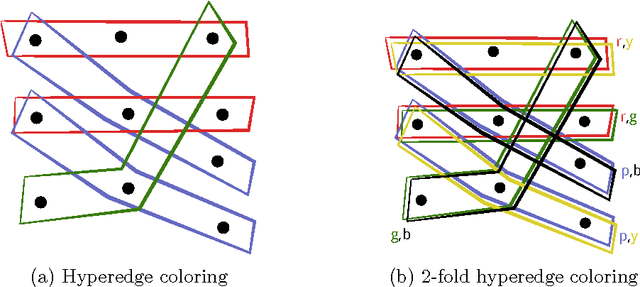
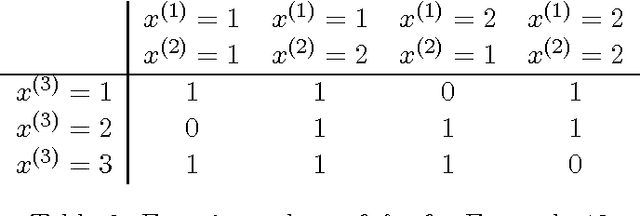
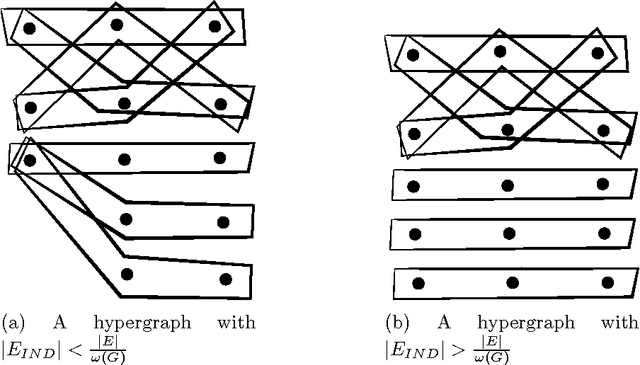
Many machine learning algorithms are based on the assumption that training examples are drawn independently. However, this assumption does not hold anymore when learning from a networked sample because two or more training examples may share some common objects, and hence share the features of these shared objects. We show that the classic approach of ignoring this problem potentially can have a harmful effect on the accuracy of statistics, and then consider alternatives. One of these is to only use independent examples, discarding other information. However, this is clearly suboptimal. We analyze sample error bounds in this networked setting, providing significantly improved results. An important component of our approach is formed by efficient sample weighting schemes, which leads to novel concentration inequalities.
Learning from networked examples in a k-partite graph
Feb 18, 2017
Many machine learning algorithms are based on the assumption that training examples are drawn independently. However, this assumption does not hold anymore when learning from a networked sample where two or more training examples may share common features. We propose an efficient weighting method for learning from networked examples and show the sample error bound which is better than previous work.