 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarping and Matching Subsequences Between Time Series
Jun 18, 2025Comparing time series is essential in various tasks such as clustering and classification. While elastic distance measures that allow warping provide a robust quantitative comparison, a qualitative comparison on top of them is missing. Traditional visualizations focus on point-to-point alignment and do not convey the broader structural relationships at the level of subsequences. This limitation makes it difficult to understand how and where one time series shifts, speeds up or slows down with respect to another. To address this, we propose a novel technique that simplifies the warping path to highlight, quantify and visualize key transformations (shift, compression, difference in amplitude). By offering a clearer representation of how subsequences match between time series, our method enhances interpretability in time series comparison.
Steering the LoCoMotif: Using Domain Knowledge in Time Series Motif Discovery
Feb 17, 2025Time Series Motif Discovery (TSMD) identifies repeating patterns in time series data, but its unsupervised nature might result in motifs that are not interesting to the user. To address this, we propose a framework that allows the user to impose constraints on the motifs to be discovered, where constraints can easily be defined according to the properties of the desired motifs in the application domain. We also propose an efficient implementation of the framework, the LoCoMotif-DoK algorithm. We demonstrate that LoCoMotif-DoK can effectively leverage domain knowledge in real and synthetic data, outperforming other TSMD techniques which only support a limited form of domain knowledge.
Quantitative Evaluation of Motif Sets in Time Series
Dec 12, 2024Time Series Motif Discovery (TSMD), which aims at finding recurring patterns in time series, is an important task in numerous application domains, and many methods for this task exist. These methods are usually evaluated qualitatively. A few metrics for quantitative evaluation, where discovered motifs are compared to some ground truth, have been proposed, but they typically make implicit assumptions that limit their applicability. This paper introduces PROM, a broadly applicable metric that overcomes those limitations, and TSMD-Bench, a benchmark for quantitative evaluation of time series motif discovery. Experiments with PROM and TSMD-Bench show that PROM provides a more comprehensive evaluation than existing metrics, that TSMD-Bench is a more challenging benchmark than earlier ones, and that the combination can help understand the relative performance of TSMD methods. More generally, the proposed approach enables large-scale, systematic performance comparisons in this field.
LoCoMotif: Discovering time-warped motifs in time series
Nov 29, 2023



Time Series Motif Discovery (TSMD) refers to the task of identifying patterns that occur multiple times (possibly with minor variations) in a time series. All existing methods for TSMD have one or more of the following limitations: they only look for the two most similar occurrences of a pattern; they only look for patterns of a pre-specified, fixed length; they cannot handle variability along the time axis; and they only handle univariate time series. In this paper, we present a new method, LoCoMotif, that has none of these limitations. The method is motivated by a concrete use case from physiotherapy. We demonstrate the value of the proposed method on this use case. We also introduce a new quantitative evaluation metric for motif discovery, and benchmark data for comparing TSMD methods. LoCoMotif substantially outperforms the existing methods, on top of being more broadly applicable.
AD-MERCS: Modeling Normality and Abnormality in Unsupervised Anomaly Detection
May 22, 2023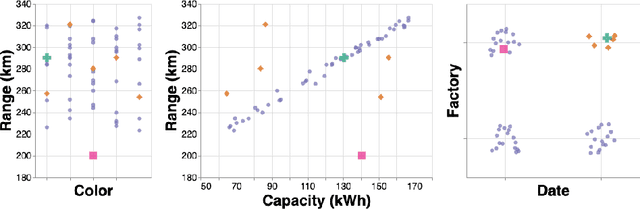
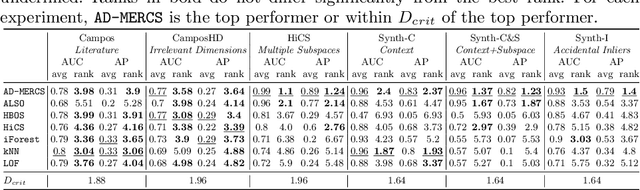
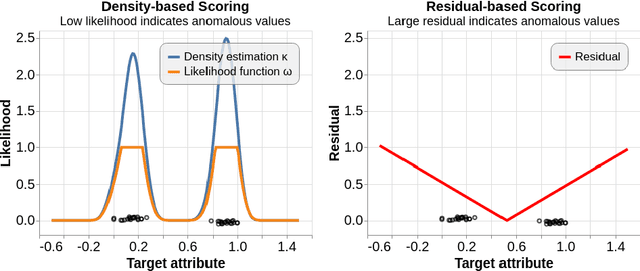

Most anomaly detection systems try to model normal behavior and assume anomalies deviate from it in diverse manners. However, there may be patterns in the anomalies as well. Ideally, an anomaly detection system can exploit patterns in both normal and anomalous behavior. In this paper, we present AD-MERCS, an unsupervised approach to anomaly detection that explicitly aims at doing both. AD-MERCS identifies multiple subspaces of the instance space within which patterns exist, and identifies conditions (possibly in other subspaces) that characterize instances that deviate from these patterns. Experiments show that this modeling of both normality and abnormality makes the anomaly detector performant on a wide range of types of anomalies. Moreover, by identifying patterns and conditions in (low-dimensional) subspaces, the anomaly detector can provide simple explanations of why something is considered an anomaly. These explanations can be both negative (deviation from some pattern) as positive (meeting some condition that is typical for anomalies).
DeepSaDe: Learning Neural Networks that Guarantee Domain Constraint Satisfaction
Mar 02, 2023As machine learning models, specifically neural networks, are becoming increasingly popular, there are concerns regarding their trustworthiness, specially in safety-critical applications, e.g. actions of an autonomous vehicle must be safe. There are approaches that can train neural networks where such domain requirements are enforced as constraints, but they either cannot guarantee that the constraint will be satisfied by all possible predictions (even on unseen data) or they are limited in the type of constraints that can be enforced. In this paper, we present an approach to train neural networks which can enforce a wide variety of constraints and guarantee that the constraint is satisfied by all possible predictions. The approach builds on earlier work where learning linear models is formulated as a constraint satisfaction problem (CSP). To make this idea applicable to neural networks, two crucial new elements are added: constraint propagation over the network layers, and weight updates based on a mix of gradient descent and CSP solving. Evaluation on various machine learning tasks demonstrates that our approach is flexible enough to enforce a wide variety of domain constraints and is able to guarantee them in neural networks.
Automatic Generation of Product Concepts from Positive Examples, with an Application to Music Streaming
Oct 08, 2022
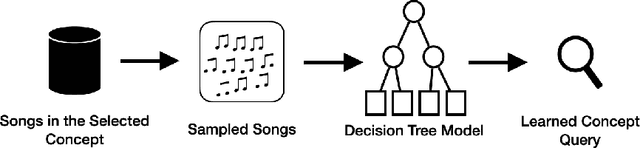
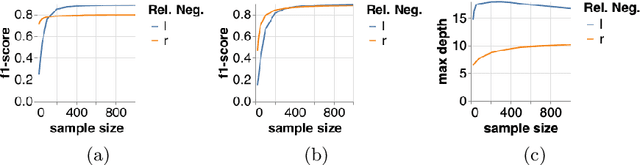
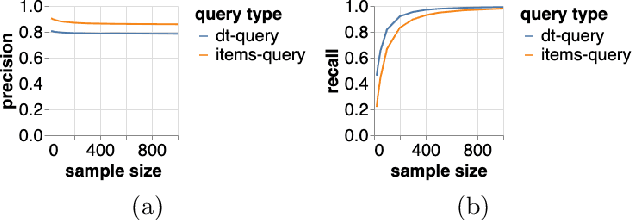
Internet based businesses and products (e.g. e-commerce, music streaming) are becoming more and more sophisticated every day with a lot of focus on improving customer satisfaction. A core way they achieve this is by providing customers with an easy access to their products by structuring them in catalogues using navigation bars and providing recommendations. We refer to these catalogues as product concepts, e.g. product categories on e-commerce websites, public playlists on music streaming platforms. These product concepts typically contain products that are linked with each other through some common features (e.g. a playlist of songs by the same artist). How they are defined in the backend of the system can be different for different products. In this work, we represent product concepts using database queries and tackle two learning problems. First, given sets of products that all belong to the same unknown product concept, we learn a database query that is a representation of this product concept. Second, we learn product concepts and their corresponding queries when the given sets of products are associated with multiple product concepts. To achieve these goals, we propose two approaches that combine the concepts of PU learning with Decision Trees and Clustering. Our experiments demonstrate, via a simulated setup for a music streaming service, that our approach is effective in solving these problems.
Combining Predictions under Uncertainty: The Case of Random Decision Trees
Aug 15, 2022A common approach to aggregate classification estimates in an ensemble of decision trees is to either use voting or to average the probabilities for each class. The latter takes uncertainty into account, but not the reliability of the uncertainty estimates (so to say, the "uncertainty about the uncertainty"). More generally, much remains unknown about how to best combine probabilistic estimates from multiple sources. In this paper, we investigate a number of alternative prediction methods. Our methods are inspired by the theories of probability, belief functions and reliable classification, as well as a principle that we call evidence accumulation. Our experiments on a variety of data sets are based on random decision trees which guarantees a high diversity in the predictions to be combined. Somewhat unexpectedly, we found that taking the average over the probabilities is actually hard to beat. However, evidence accumulation showed consistently better results on all but very small leafs.
* Preprint version. Appeared in: Discovery Science. 24th International Conference, DS 2021, Halifax, NS, Canada, October 11 to 13, 2021, Proceedings. See https://ds2021.cs.dal.ca/ for further information
SaDe: Learning Models that Provably Satisfy Domain Constraints
Dec 08, 2021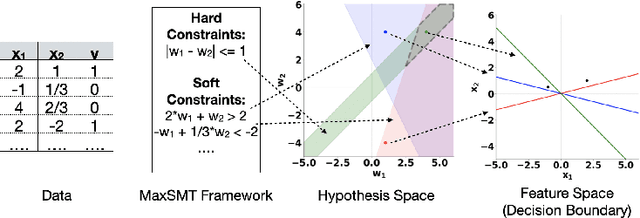

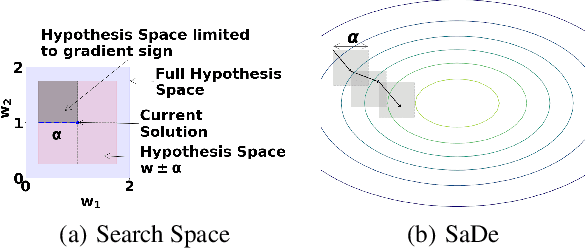
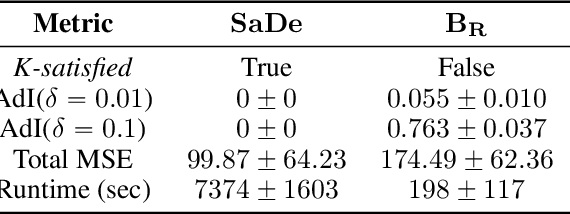
With increasing real world applications of machine learning, models are often required to comply with certain domain based requirements, e.g., safety guarantees in aircraft systems, legal constraints in a loan approval model. A natural way to represent these properties is in the form of constraints. Including such constraints in machine learning is typically done by the means of regularization, which does not guarantee satisfaction of the constraints. In this paper, we present a machine learning approach that can handle a wide variety of constraints, and guarantee that these constraints will be satisfied by the model even on unseen data. We cast machine learning as a maximum satisfiability problem, and solve it using a novel algorithm SaDe which combines constraint satisfaction with gradient descent. We demonstrate on three use cases that this approach learns models that provably satisfy the given constraints.
Feature Interactions in XGBoost
Jul 11, 2020In this paper, we investigate how feature interactions can be identified to be used as constraints in the gradient boosting tree models using XGBoost's implementation. Our results show that accurate identification of these constraints can help improve the performance of baseline XGBoost model significantly. Further, the improvement in the model structure can also lead to better interpretability.