 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAD-MERCS: Modeling Normality and Abnormality in Unsupervised Anomaly Detection
May 22, 2023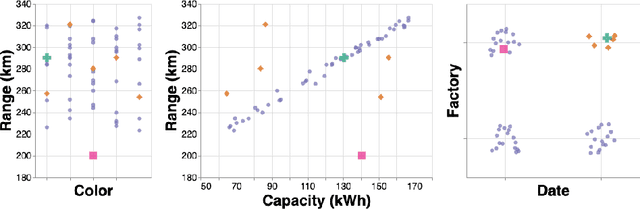
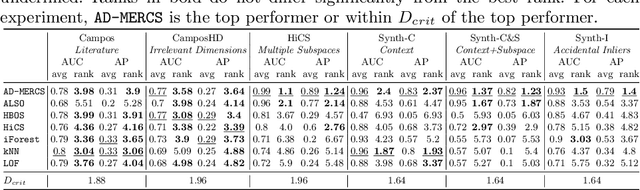
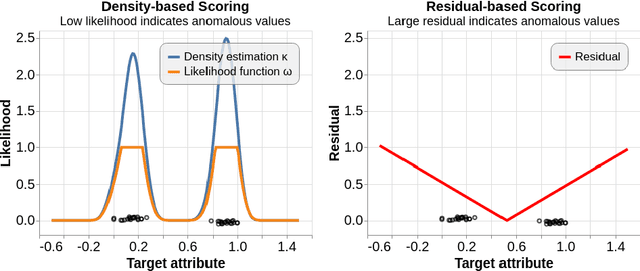

Most anomaly detection systems try to model normal behavior and assume anomalies deviate from it in diverse manners. However, there may be patterns in the anomalies as well. Ideally, an anomaly detection system can exploit patterns in both normal and anomalous behavior. In this paper, we present AD-MERCS, an unsupervised approach to anomaly detection that explicitly aims at doing both. AD-MERCS identifies multiple subspaces of the instance space within which patterns exist, and identifies conditions (possibly in other subspaces) that characterize instances that deviate from these patterns. Experiments show that this modeling of both normality and abnormality makes the anomaly detector performant on a wide range of types of anomalies. Moreover, by identifying patterns and conditions in (low-dimensional) subspaces, the anomaly detector can provide simple explanations of why something is considered an anomaly. These explanations can be both negative (deviation from some pattern) as positive (meeting some condition that is typical for anomalies).
Automatic Generation of Product Concepts from Positive Examples, with an Application to Music Streaming
Oct 08, 2022
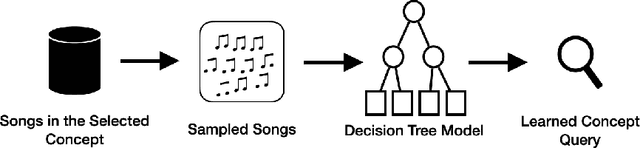
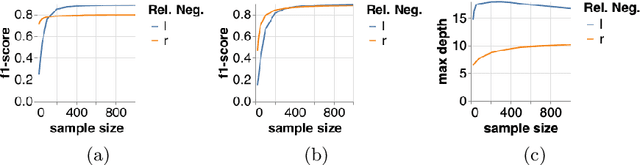
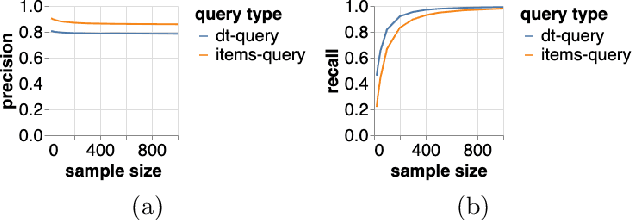
Internet based businesses and products (e.g. e-commerce, music streaming) are becoming more and more sophisticated every day with a lot of focus on improving customer satisfaction. A core way they achieve this is by providing customers with an easy access to their products by structuring them in catalogues using navigation bars and providing recommendations. We refer to these catalogues as product concepts, e.g. product categories on e-commerce websites, public playlists on music streaming platforms. These product concepts typically contain products that are linked with each other through some common features (e.g. a playlist of songs by the same artist). How they are defined in the backend of the system can be different for different products. In this work, we represent product concepts using database queries and tackle two learning problems. First, given sets of products that all belong to the same unknown product concept, we learn a database query that is a representation of this product concept. Second, we learn product concepts and their corresponding queries when the given sets of products are associated with multiple product concepts. To achieve these goals, we propose two approaches that combine the concepts of PU learning with Decision Trees and Clustering. Our experiments demonstrate, via a simulated setup for a music streaming service, that our approach is effective in solving these problems.
COBRAS: Fast, Iterative, Active Clustering with Pairwise Constraints
Mar 29, 2018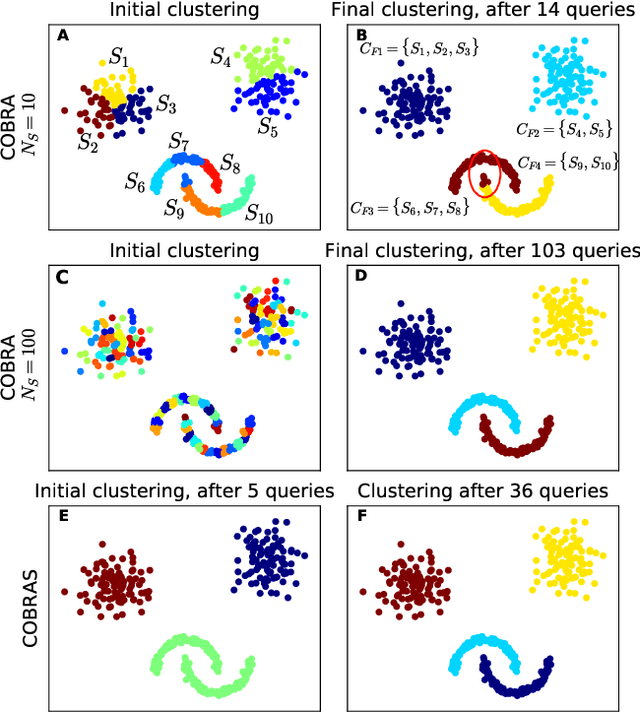
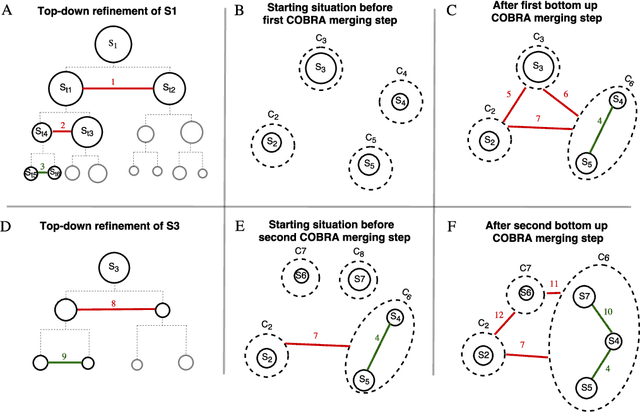
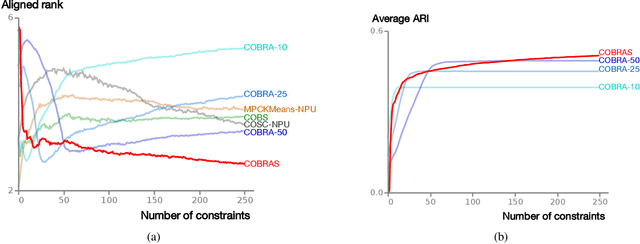
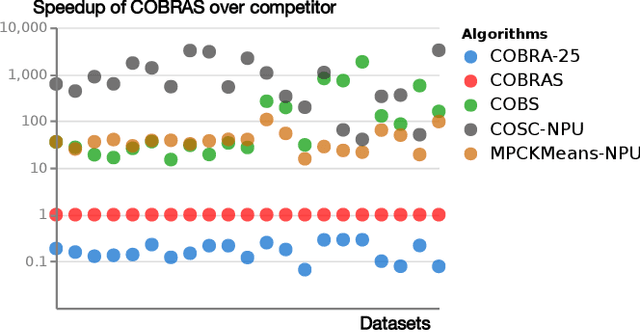
Constraint-based clustering algorithms exploit background knowledge to construct clusterings that are aligned with the interests of a particular user. This background knowledge is often obtained by allowing the clustering system to pose pairwise queries to the user: should these two elements be in the same cluster or not? Active clustering methods aim to minimize the number of queries needed to obtain a good clustering by querying the most informative pairs first. Ideally, a user should be able to answer a couple of these queries, inspect the resulting clustering, and repeat these two steps until a satisfactory result is obtained. We present COBRAS, an approach to active clustering with pairwise constraints that is suited for such an interactive clustering process. A core concept in COBRAS is that of a super-instance: a local region in the data in which all instances are assumed to belong to the same cluster. COBRAS constructs such super-instances in a top-down manner to produce high-quality results early on in the clustering process, and keeps refining these super-instances as more pairwise queries are given to get more detailed clusterings later on. We experimentally demonstrate that COBRAS produces good clusterings at fast run times, making it an excellent candidate for the iterative clustering scenario outlined above.