 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOBRAS-TS: A new approach to Semi-Supervised Clustering of Time Series
May 02, 2018

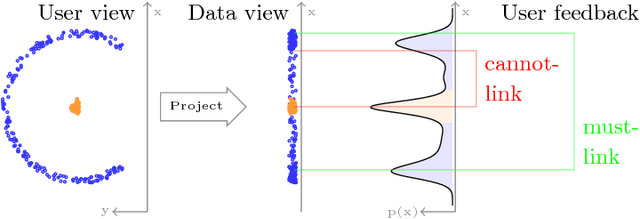
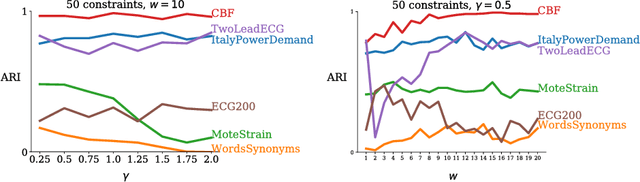
Clustering is ubiquitous in data analysis, including analysis of time series. It is inherently subjective: different users may prefer different clusterings for a particular dataset. Semi-supervised clustering addresses this by allowing the user to provide examples of instances that should (not) be in the same cluster. This paper studies semi-supervised clustering in the context of time series. We show that COBRAS, a state-of-the-art semi-supervised clustering method, can be adapted to this setting. We refer to this approach as COBRAS-TS. An extensive experimental evaluation supports the following claims: (1) COBRAS-TS far outperforms the current state of the art in semi-supervised clustering for time series, and thus presents a new baseline for the field; (2) COBRAS-TS can identify clusters with separated components; (3) COBRAS-TS can identify clusters that are characterized by small local patterns; (4) a small amount of semi-supervision can greatly improve clustering quality for time series; (5) the choice of the clustering algorithm matters (contrary to earlier claims in the literature).
COBRAS: Fast, Iterative, Active Clustering with Pairwise Constraints
Mar 29, 2018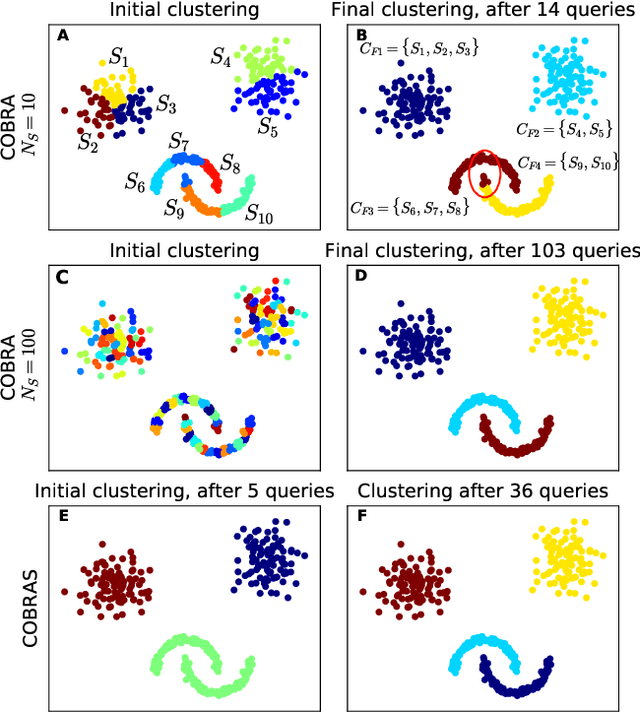
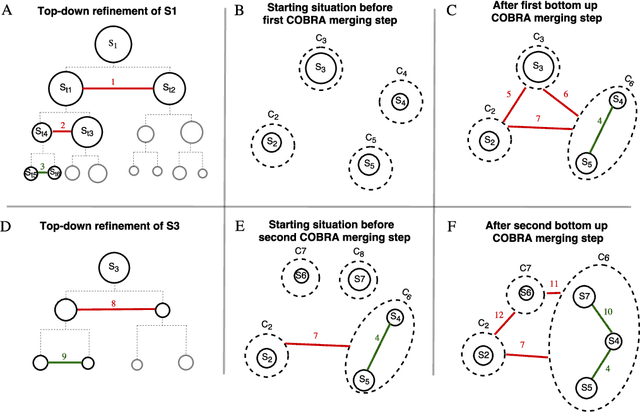
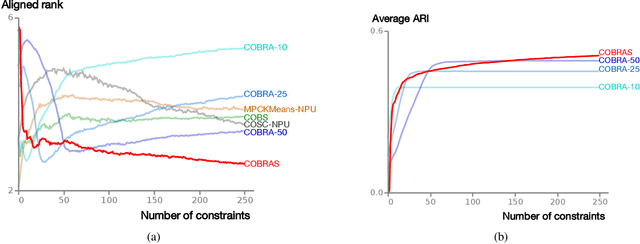
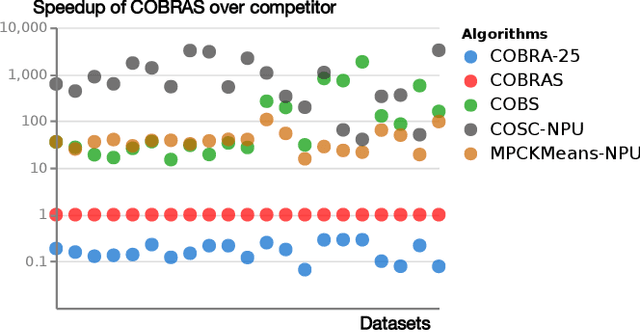
Constraint-based clustering algorithms exploit background knowledge to construct clusterings that are aligned with the interests of a particular user. This background knowledge is often obtained by allowing the clustering system to pose pairwise queries to the user: should these two elements be in the same cluster or not? Active clustering methods aim to minimize the number of queries needed to obtain a good clustering by querying the most informative pairs first. Ideally, a user should be able to answer a couple of these queries, inspect the resulting clustering, and repeat these two steps until a satisfactory result is obtained. We present COBRAS, an approach to active clustering with pairwise constraints that is suited for such an interactive clustering process. A core concept in COBRAS is that of a super-instance: a local region in the data in which all instances are assumed to belong to the same cluster. COBRAS constructs such super-instances in a top-down manner to produce high-quality results early on in the clustering process, and keeps refining these super-instances as more pairwise queries are given to get more detailed clusterings later on. We experimentally demonstrate that COBRAS produces good clusterings at fast run times, making it an excellent candidate for the iterative clustering scenario outlined above.
COBRA: A Fast and Simple Method for Active Clustering with Pairwise Constraints
Jan 30, 2018



Clustering is inherently ill-posed: there often exist multiple valid clusterings of a single dataset, and without any additional information a clustering system has no way of knowing which clustering it should produce. This motivates the use of constraints in clustering, as they allow users to communicate their interests to the clustering system. Active constraint-based clustering algorithms select the most useful constraints to query, aiming to produce a good clustering using as few constraints as possible. We propose COBRA, an active method that first over-clusters the data by running K-means with a $K$ that is intended to be too large, and subsequently merges the resulting small clusters into larger ones based on pairwise constraints. In its merging step, COBRA is able to keep the number of pairwise queries low by maximally exploiting constraint transitivity and entailment. We experimentally show that COBRA outperforms the state of the art in terms of clustering quality and runtime, without requiring the number of clusters in advance.
Constraint-Based Clustering Selection
Sep 23, 2016
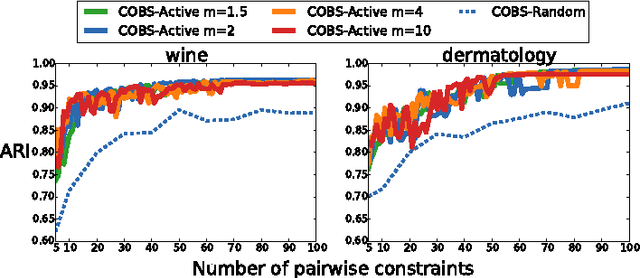

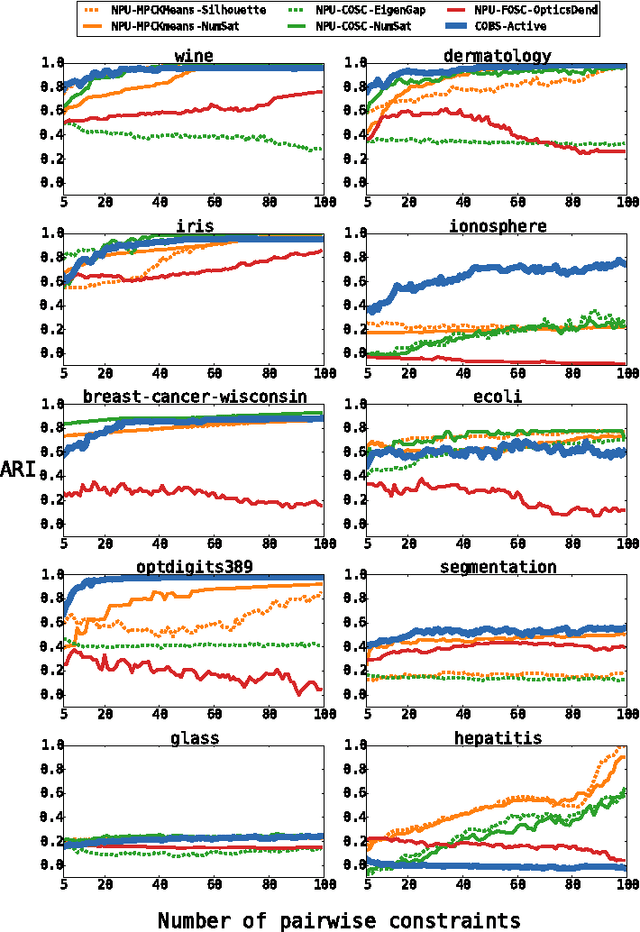
Semi-supervised clustering methods incorporate a limited amount of supervision into the clustering process. Typically, this supervision is provided by the user in the form of pairwise constraints. Existing methods use such constraints in one of the following ways: they adapt their clustering procedure, their similarity metric, or both. All of these approaches operate within the scope of individual clustering algorithms. In contrast, we propose to use constraints to choose between clusterings generated by very different unsupervised clustering algorithms, run with different parameter settings. We empirically show that this simple approach often outperforms existing semi-supervised clustering methods.