Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint-Based Clustering Selection
Paper and Code
Sep 23, 2016
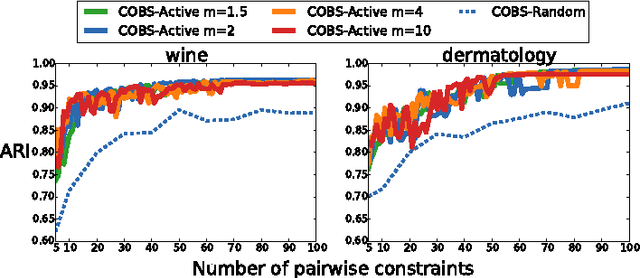

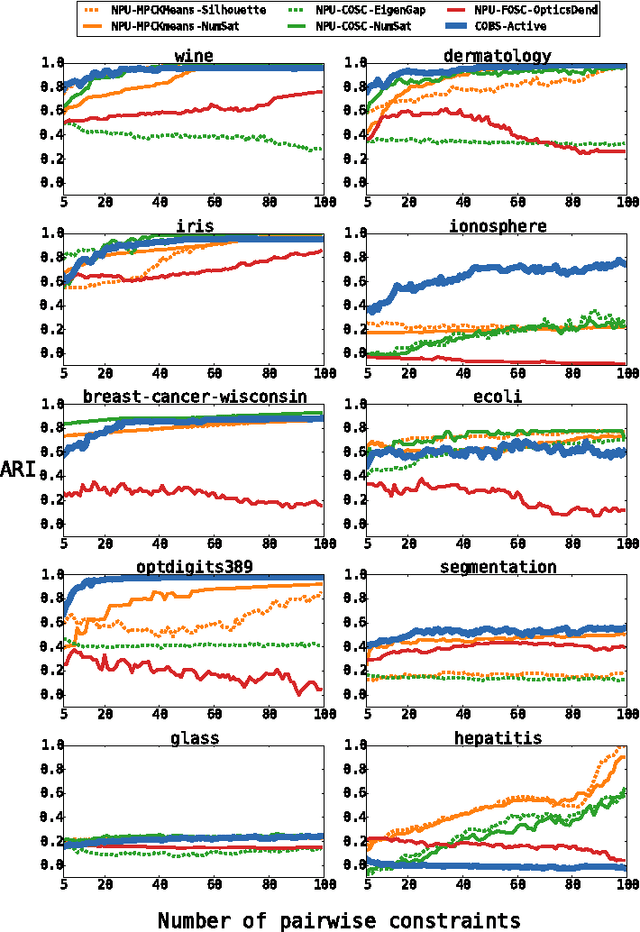
Semi-supervised clustering methods incorporate a limited amount of supervision into the clustering process. Typically, this supervision is provided by the user in the form of pairwise constraints. Existing methods use such constraints in one of the following ways: they adapt their clustering procedure, their similarity metric, or both. All of these approaches operate within the scope of individual clustering algorithms. In contrast, we propose to use constraints to choose between clusterings generated by very different unsupervised clustering algorithms, run with different parameter settings. We empirically show that this simple approach often outperforms existing semi-supervised clustering methods.
View paper on