 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning RGB models to hyperspectral images with trainable tensor decompositions
May 27, 2026Transfer learning makes it possible to use large vision networks on a variety of domains, by specializing their models' general filters to new tasks. However, these networks assume the input images to have 3 input channels, making them incompatible with multi- or hyperspectral images. Current approaches that mitigate this incompatibility sacrifice information in either the image, or the model. This work proposes a novel approach that preserves the image and spatial information present in the model by using partially trainable tensor decompositions. We create such decompositions of pretrained convolutional filters, separating the filters into spatial and spectral components. The spectral components are then replaced with trainable components of higher channel dimensionality. This creates hyperspectral filters that can specialize to new datasets, while retaining the spatial patterns of the original filter. Experiments on a variety of hyperspectral datasets show that our approach is more accurate and robust than other hyperspectral transfer learning methods.
Warping and Matching Subsequences Between Time Series
Jun 18, 2025Comparing time series is essential in various tasks such as clustering and classification. While elastic distance measures that allow warping provide a robust quantitative comparison, a qualitative comparison on top of them is missing. Traditional visualizations focus on point-to-point alignment and do not convey the broader structural relationships at the level of subsequences. This limitation makes it difficult to understand how and where one time series shifts, speeds up or slows down with respect to another. To address this, we propose a novel technique that simplifies the warping path to highlight, quantify and visualize key transformations (shift, compression, difference in amplitude). By offering a clearer representation of how subsequences match between time series, our method enhances interpretability in time series comparison.
dtaianomaly: A Python library for time series anomaly detection
Feb 20, 2025


dtaianomaly is an open-source Python library for time series anomaly detection, designed to bridge the gap between academic research and real-world applications. Our goal is to (1) accelerate the development of novel state-of-the-art anomaly detection techniques through simple extensibility; (2) offer functionality for large-scale experimental validation; and thereby (3) bring cutting-edge research to business and industry through a standardized API, similar to scikit-learn to lower the entry barrier for both new and experienced users. Besides these key features, dtaianomaly offers (1) a broad range of built-in anomaly detectors, (2) support for time series preprocessing, (3) tools for visual analysis, (4) confidence prediction of anomaly scores, (5) runtime and memory profiling, (6) comprehensive documentation, and (7) cross-platform unit testing. The source code of dtaianomaly, documentation, code examples and installation guides are publicly available at https://github.com/ML-KULeuven/dtaianomaly.
Steering the LoCoMotif: Using Domain Knowledge in Time Series Motif Discovery
Feb 17, 2025Time Series Motif Discovery (TSMD) identifies repeating patterns in time series data, but its unsupervised nature might result in motifs that are not interesting to the user. To address this, we propose a framework that allows the user to impose constraints on the motifs to be discovered, where constraints can easily be defined according to the properties of the desired motifs in the application domain. We also propose an efficient implementation of the framework, the LoCoMotif-DoK algorithm. We demonstrate that LoCoMotif-DoK can effectively leverage domain knowledge in real and synthetic data, outperforming other TSMD techniques which only support a limited form of domain knowledge.
Quantitative Evaluation of Motif Sets in Time Series
Dec 12, 2024Time Series Motif Discovery (TSMD), which aims at finding recurring patterns in time series, is an important task in numerous application domains, and many methods for this task exist. These methods are usually evaluated qualitatively. A few metrics for quantitative evaluation, where discovered motifs are compared to some ground truth, have been proposed, but they typically make implicit assumptions that limit their applicability. This paper introduces PROM, a broadly applicable metric that overcomes those limitations, and TSMD-Bench, a benchmark for quantitative evaluation of time series motif discovery. Experiments with PROM and TSMD-Bench show that PROM provides a more comprehensive evaluation than existing metrics, that TSMD-Bench is a more challenging benchmark than earlier ones, and that the combination can help understand the relative performance of TSMD methods. More generally, the proposed approach enables large-scale, systematic performance comparisons in this field.
A Machine Learning Approach Towards SKILL Code Autocompletion
Dec 04, 2023As Moore's Law continues to increase the complexity of electronic systems, Electronic Design Automation (EDA) must advance to meet global demand. An important example of an EDA technology is SKILL, a scripting language used to customize and extend EDA software. Recently, code generation models using the transformer architecture have achieved impressive results in academic settings and have even been used in commercial developer tools to improve developer productivity. To the best of our knowledge, this study is the first to apply transformers to SKILL code autocompletion towards improving the productivity of hardware design engineers. In this study, a novel, data-efficient methodology for generating SKILL code is proposed and experimentally validated. More specifically, we propose a novel methodology for (i) creating a high-quality SKILL dataset with both unlabeled and labeled data, (ii) a training strategy where T5 models pre-trained on general programming language code are fine-tuned on our custom SKILL dataset using unsupervised and supervised learning, and (iii) evaluating synthesized SKILL code. We show that models trained using the proposed methodology outperform baselines in terms of human-judgment score and BLEU score. A major challenge faced was the extremely small amount of available SKILL code data that can be used to train a transformer model to generate SKILL code. Despite our validated improvements, the extremely small dataset available to us was still not enough to train a model that can reliably autocomplete SKILL code. We discuss this and other limitations as well as future work that could address these limitations.
LoCoMotif: Discovering time-warped motifs in time series
Nov 29, 2023



Time Series Motif Discovery (TSMD) refers to the task of identifying patterns that occur multiple times (possibly with minor variations) in a time series. All existing methods for TSMD have one or more of the following limitations: they only look for the two most similar occurrences of a pattern; they only look for patterns of a pre-specified, fixed length; they cannot handle variability along the time axis; and they only handle univariate time series. In this paper, we present a new method, LoCoMotif, that has none of these limitations. The method is motivated by a concrete use case from physiotherapy. We demonstrate the value of the proposed method on this use case. We also introduce a new quantitative evaluation metric for motif discovery, and benchmark data for comparing TSMD methods. LoCoMotif substantially outperforms the existing methods, on top of being more broadly applicable.
Deriving Comprehensible Theories from Probabilistic Circuits
Nov 22, 2023The field of Explainable AI (XAI) is seeking to shed light on the inner workings of complex AI models and uncover the rationale behind their decisions. One of the models gaining attention are probabilistic circuits (PCs), which are a general and unified framework for tractable probabilistic models that support efficient computation of various probabilistic queries. Probabilistic circuits guarantee inference that is polynomial in the size of the circuit. In this paper, we improve the explainability of probabilistic circuits by computing a comprehensible, readable logical theory that covers the high-density regions generated by a PC. To achieve this, pruning approaches based on generative significance are used in a new method called PUTPUT (Probabilistic circuit Understanding Through Pruning Underlying logical Theories). The method is applied to a real world use case where music playlists are automatically generated and expressed as readable (database) queries. Evaluation shows that this approach can effectively produce a comprehensible logical theory that describes the high-density regions of a PC and outperforms state of the art methods when exploring the performance-comprehensibility trade-off.
Automated Semiconductor Defect Inspection in Scanning Electron Microscope Images: a Systematic Review
Aug 18, 2023

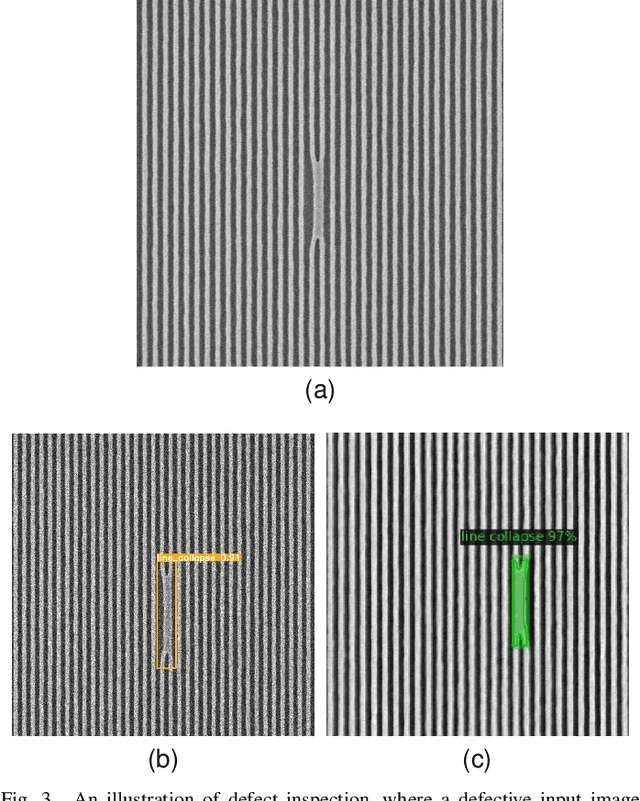

A growing need exists for efficient and accurate methods for detecting defects in semiconductor materials and devices. These defects can have a detrimental impact on the efficiency of the manufacturing process, because they cause critical failures and wafer-yield limitations. As nodes and patterns get smaller, even high-resolution imaging techniques such as Scanning Electron Microscopy (SEM) produce noisy images due to operating close to sensitivity levels and due to varying physical properties of different underlayers or resist materials. This inherent noise is one of the main challenges for defect inspection. One promising approach is the use of machine learning algorithms, which can be trained to accurately classify and locate defects in semiconductor samples. Recently, convolutional neural networks have proved to be particularly useful in this regard. This systematic review provides a comprehensive overview of the state of automated semiconductor defect inspection on SEM images, including the most recent innovations and developments. 38 publications were selected on this topic, indexed in IEEE Xplore and SPIE databases. For each of these, the application, methodology, dataset, results, limitations and future work were summarized. A comprehensive overview and analysis of their methods is provided. Finally, promising avenues for future work in the field of SEM-based defect inspection are suggested.
AD-MERCS: Modeling Normality and Abnormality in Unsupervised Anomaly Detection
May 22, 2023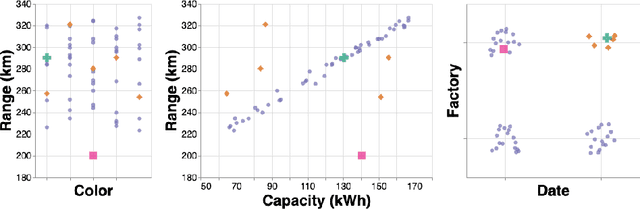
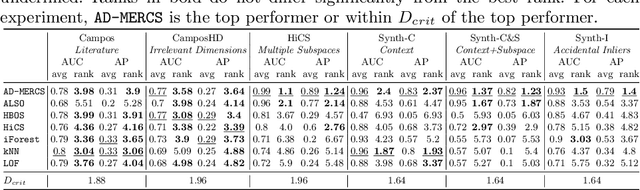
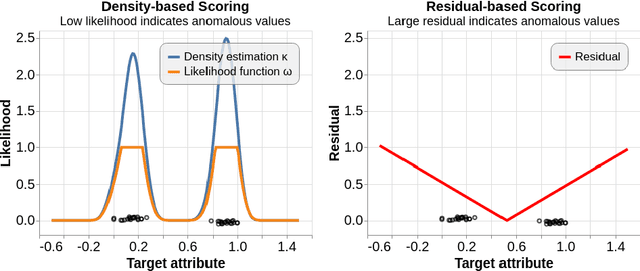

Most anomaly detection systems try to model normal behavior and assume anomalies deviate from it in diverse manners. However, there may be patterns in the anomalies as well. Ideally, an anomaly detection system can exploit patterns in both normal and anomalous behavior. In this paper, we present AD-MERCS, an unsupervised approach to anomaly detection that explicitly aims at doing both. AD-MERCS identifies multiple subspaces of the instance space within which patterns exist, and identifies conditions (possibly in other subspaces) that characterize instances that deviate from these patterns. Experiments show that this modeling of both normality and abnormality makes the anomaly detector performant on a wide range of types of anomalies. Moreover, by identifying patterns and conditions in (low-dimensional) subspaces, the anomaly detector can provide simple explanations of why something is considered an anomaly. These explanations can be both negative (deviation from some pattern) as positive (meeting some condition that is typical for anomalies).