 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarping and Matching Subsequences Between Time Series
Jun 18, 2025Comparing time series is essential in various tasks such as clustering and classification. While elastic distance measures that allow warping provide a robust quantitative comparison, a qualitative comparison on top of them is missing. Traditional visualizations focus on point-to-point alignment and do not convey the broader structural relationships at the level of subsequences. This limitation makes it difficult to understand how and where one time series shifts, speeds up or slows down with respect to another. To address this, we propose a novel technique that simplifies the warping path to highlight, quantify and visualize key transformations (shift, compression, difference in amplitude). By offering a clearer representation of how subsequences match between time series, our method enhances interpretability in time series comparison.
Biases in Expected Goals Models Confound Finishing Ability
Jan 18, 2024Expected Goals (xG) has emerged as a popular tool for evaluating finishing skill in soccer analytics. It involves comparing a player's cumulative xG with their actual goal output, where consistent overperformance indicates strong finishing ability. However, the assessment of finishing skill in soccer using xG remains contentious due to players' difficulty in consistently outperforming their cumulative xG. In this paper, we aim to address the limitations and nuances surrounding the evaluation of finishing skill using xG statistics. Specifically, we explore three hypotheses: (1) the deviation between actual and expected goals is an inadequate metric due to the high variance of shot outcomes and limited sample sizes, (2) the inclusion of all shots in cumulative xG calculation may be inappropriate, and (3) xG models contain biases arising from interdependencies in the data that affect skill measurement. We found that sustained overperformance of cumulative xG requires both high shot volumes and exceptional finishing, including all shot types can obscure the finishing ability of proficient strikers, and that there is a persistent bias that makes the actual and expected goals closer for excellent finishers than it really is. Overall, our analysis indicates that we need more nuanced quantitative approaches for investigating a player's finishing ability, which we achieved using a technique from AI fairness to learn an xG model that is calibrated for multiple subgroups of players. As a concrete use case, we show that (1) the standard biased xG model underestimates Messi's GAX by 17% and (2) Messi's GAX is 27% higher than the typical elite high-shot-volume attacker, indicating that Messi is even a more exceptional finisher than people commonly believed.
Elastic Product Quantization for Time Series
Jan 04, 2022
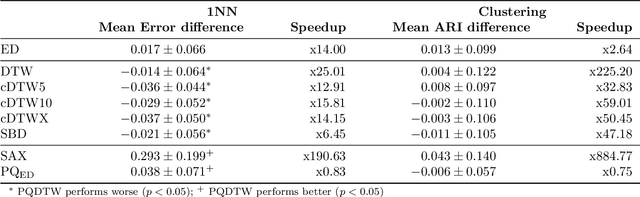


Analyzing numerous or long time series is difficult in practice due to the high storage costs and computational requirements. Therefore, techniques have been proposed to generate compact similarity-preserving representations of time series, enabling real-time similarity search on large in-memory data collections. However, the existing techniques are not ideally suited for assessing similarity when sequences are locally out of phase. In this paper, we propose the use of product quantization for efficient similarity-based comparison of time series under time warping. The idea is to first compress the data by partitioning the time series into equal length sub-sequences which are represented by a short code. The distance between two time series can then be efficiently approximated by pre-computed elastic distances between their codes. The partitioning into sub-sequences forces unwanted alignments, which we address with a pre-alignment step using the maximal overlap discrete wavelet transform (MODWT). To demonstrate the efficiency and accuracy of our method, we perform an extensive experimental evaluation on benchmark datasets in nearest neighbors classification and clustering applications. Overall, the proposed solution emerges as a highly efficient (both in terms of memory usage and computation time) replacement for elastic measures in time series applications.
Leaving Goals on the Pitch: Evaluating Decision Making in Soccer
Apr 07, 2021
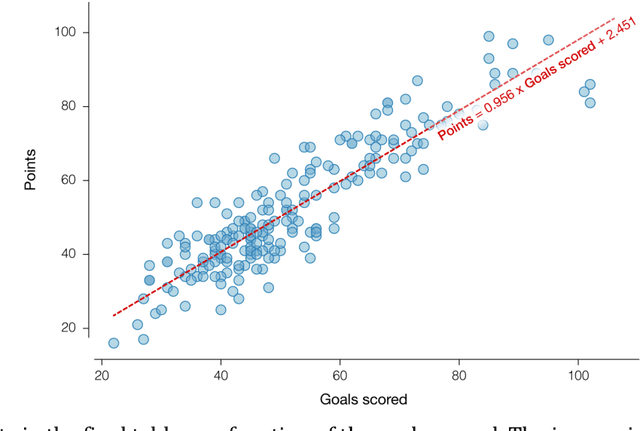
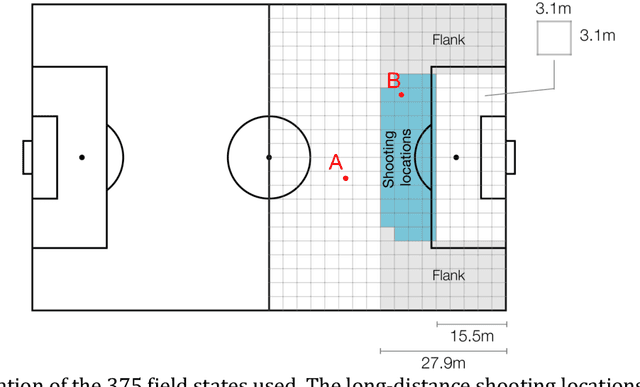

Analysis of the popular expected goals (xG) metric in soccer has determined that a (slightly) smaller number of high-quality attempts will likely yield more goals than a slew of low-quality ones. This observation has driven a change in shooting behavior. Teams are passing up on shots from outside the penalty box, in the hopes of generating a better shot closer to goal later on. This paper evaluates whether this decrease in long-distance shots is warranted. Therefore, we propose a novel generic framework to reason about decision-making in soccer by combining techniques from machine learning and artificial intelligence (AI). First, we model how a team has behaved offensively over the course of two seasons by learning a Markov Decision Process (MDP) from event stream data. Second, we use reasoning techniques arising from the AI literature on verification to each team's MDP. This allows us to reason about the efficacy of certain potential decisions by posing counterfactual questions to the MDP. Our key conclusion is that teams would score more goals if they shot more often from outside the penalty box in a small number of team-specific locations. The proposed framework can easily be extended and applied to analyze other aspects of the game.
Gait Event Detection in Tibial Acceleration Profiles: a Structured Learning Approach
Oct 29, 2019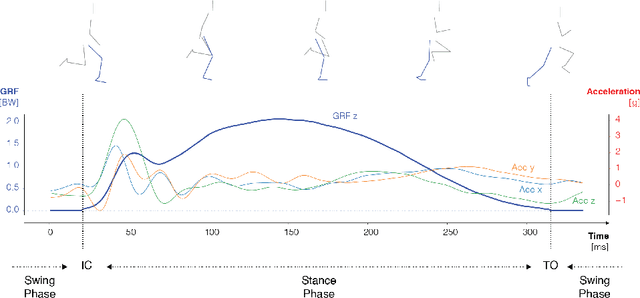

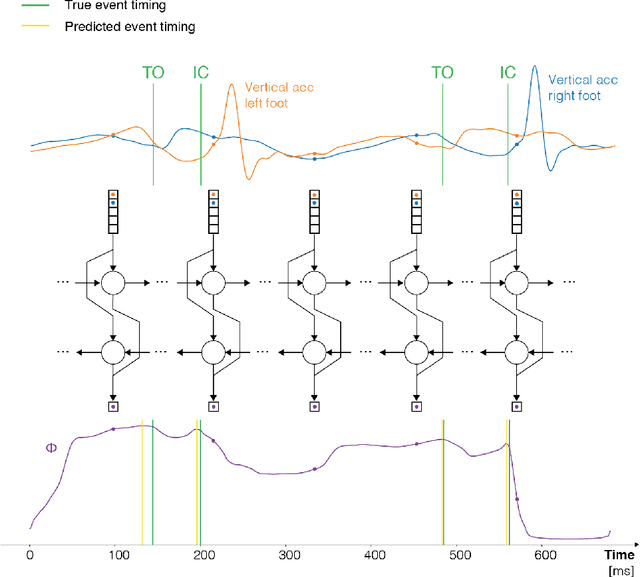
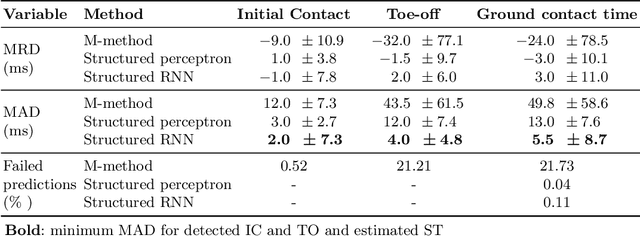
Analysis of runner's data will often examine gait variables with reference to one or more gait events. Two such representative events are the initial contact and toe off events. These correspond respectively to the moments in time when the foot makes the initial contact with the ground and when the foot leaves the ground again. These variables are traditionally measured with a force plate or motion capture system in a lab setting. However, thanks to recent evolutions in wearable technology, the use of accelerometers has become commonplace for prolonged outdoor measurements. Previous research has developed heuristic methods to identify the initial contact and toe off timings based on minima, maxima and thresholds in the acceleration profiles. A significant flaw of these heuristic-based methods is that they are tailored to very specific acceleration profiles, providing no guidelines on how to handle deviant profiles. Therefore, we frame the problem as a structured prediction task and propose a machine learning approach for determining initial foot contact and toe off events from 3D tibial acceleration profiles. With mean absolute errors of 2 ms and 4 ms for respectively the initial contact and toe-off events, our method significantly outperforms the existing heuristic approaches.
Who Will Win It? An In-game Win Probability Model for Football
Jun 12, 2019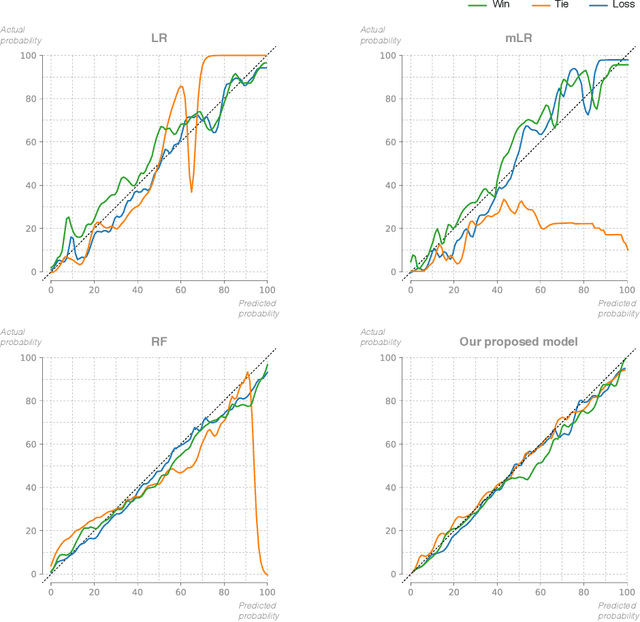
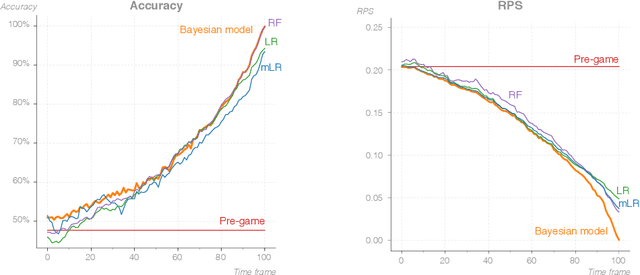
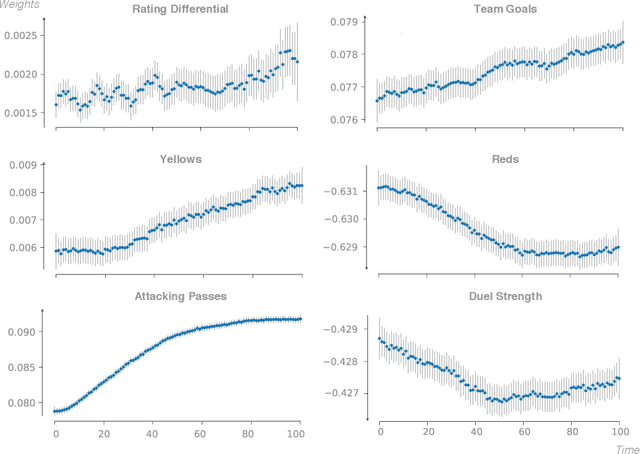
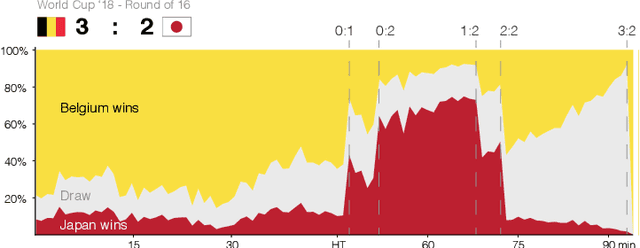
In-game win probability is a statistical metric that provides a sports team's likelihood of winning at any given point in a game, based on the performance of historical teams in the same situation. In-game win-probability models have been extensively studied in baseball, basketball and American football. These models serve as a tool to enhance the fan experience, evaluate in game-decision making and measure the risk-reward balance for coaching decisions. In contrast, they have received less attention in association football, because its low-scoring nature makes it far more challenging to analyze. In this paper, we build an in-game win probability model for football. Specifically, we first show that porting existing approaches, both in terms of the predictive models employed and the features considered, does not yield good in-game win-probability estimates for football. Second, we introduce our own Bayesian statistical model that utilizes a set of eight variables to predict the running win, tie and loss probabilities for the home team. We train our model using event data from the last four seasons of the major European football competitions. Our results indicate that our model provides well-calibrated probabilities. Finally, we elaborate on two use cases for our win probability metric: enhancing the fan experience and evaluating performance in crucial situations.