 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Reinforcement Learning via Probabilistic Logic Shields
Mar 06, 2023Safe Reinforcement learning (Safe RL) aims at learning optimal policies while staying safe. A popular solution to Safe RL is shielding, which uses a logical safety specification to prevent an RL agent from taking unsafe actions. However, traditional shielding techniques are difficult to integrate with continuous, end-to-end deep RL methods. To this end, we introduce Probabilistic Logic Policy Gradient (PLPG). PLPG is a model-based Safe RL technique that uses probabilistic logic programming to model logical safety constraints as differentiable functions. Therefore, PLPG can be seamlessly applied to any policy gradient algorithm while still providing the same convergence guarantees. In our experiments, we show that PLPG learns safer and more rewarding policies compared to other state-of-the-art shielding techniques.
Memory-like Adaptive Modeling Multi-Agent Learning System
Dec 15, 2022In this work, we propose a self-supervised multi-agent system, termed a memory-like adaptive modeling multi-agent learning system (MAMMALS), that realizes online learning towards behavioral pattern clustering tasks for time series. Encoding the visual behaviors as discrete time series(DTS), and training and modeling them in the multi-agent system with a bio-memory-like form. We finally implemented a fully decentralized multi-agent system design framework and completed its feasibility verification in a surveillance video application scenario on vehicle path clustering. In multi-agent learning, using learning methods designed for individual agents will typically perform poorly globally because of the behavior of ignoring the synergy between agents.
Learning Probabilistic Temporal Safety Properties from Examples in Relational Domains
Nov 07, 2022We propose a framework for learning a fragment of probabilistic computation tree logic (pCTL) formulae from a set of states that are labeled as safe or unsafe. We work in a relational setting and combine ideas from relational Markov Decision Processes with pCTL model-checking. More specifically, we assume that there is an unknown relational pCTL target formula that is satisfied by only safe states, and has a horizon of maximum $k$ steps and a threshold probability $\alpha$. The task then consists of learning this unknown formula from states that are labeled as safe or unsafe by a domain expert. We apply principles of relational learning to induce a pCTL formula that is satisfied by all safe states and none of the unsafe ones. This formula can then be used as a safety specification for this domain, so that the system can avoid getting into dangerous situations in future. Following relational learning principles, we introduce a candidate formula generation process, as well as a method for deciding which candidate formula is a satisfactory specification for the given labeled states. The cases where the expert knows and does not know the system policy are treated, however, much of the learning process is the same for both cases. We evaluate our approach on a synthetic relational domain.
Lifted Model Checking for Relational MDPs
Jun 22, 2021

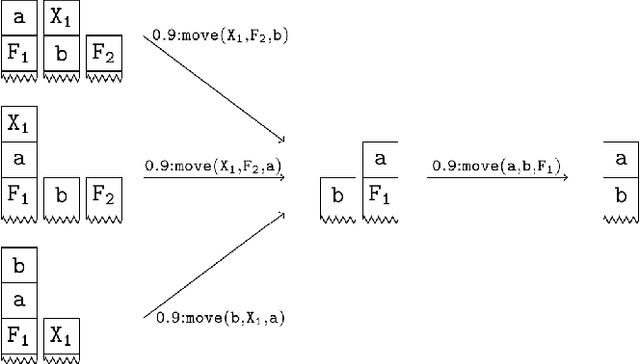
Model checking has been developed for verifying the behaviour of systems with stochastic and non-deterministic behavior. It is used to provide guarantees about such systems. While most model checking methods focus on propositional models, various probabilistic planning and reinforcement frameworks deal with relational domains, for instance, STRIPS planning and relational Markov Decision Processes. Using propositional model checking in relational settings requires one to ground the model, which leads to the well known state explosion problem and intractability. We present pCTL-REBEL, a lifted model checking approach for verifying pCTL properties on relational MDPs. It extends REBEL, the relational Bellman update operator, which is a lifted value iteration approach for model-based relational reinforcement learning, toward relational model-checking. PCTL-REBEL is lifted, which means that rather than grounding, the model exploits symmetries and reasons at an abstract relational level. Theoretically, we show that the pCTL model checking approach is decidable for relational MDPs even for possibly infinite domains provided that the states have a bounded size. Practically, we contribute algorithms and an implementation of lifted relational model checking, and we show that the lifted approach improves the scalability of the model checking approach.
Leaving Goals on the Pitch: Evaluating Decision Making in Soccer
Apr 07, 2021
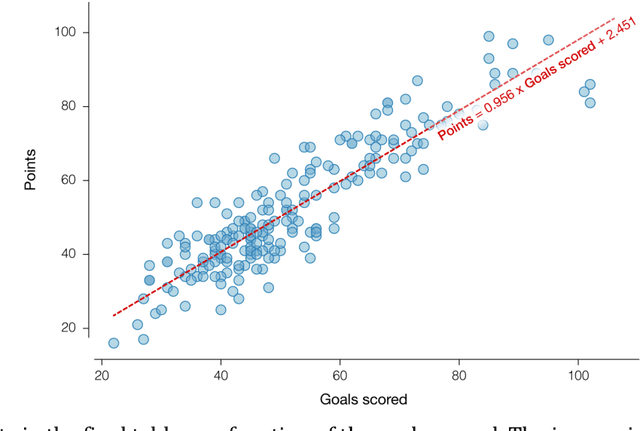
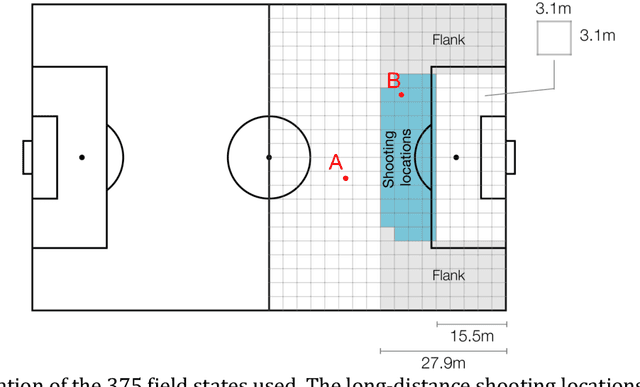

Analysis of the popular expected goals (xG) metric in soccer has determined that a (slightly) smaller number of high-quality attempts will likely yield more goals than a slew of low-quality ones. This observation has driven a change in shooting behavior. Teams are passing up on shots from outside the penalty box, in the hopes of generating a better shot closer to goal later on. This paper evaluates whether this decrease in long-distance shots is warranted. Therefore, we propose a novel generic framework to reason about decision-making in soccer by combining techniques from machine learning and artificial intelligence (AI). First, we model how a team has behaved offensively over the course of two seasons by learning a Markov Decision Process (MDP) from event stream data. Second, we use reasoning techniques arising from the AI literature on verification to each team's MDP. This allows us to reason about the efficacy of certain potential decisions by posing counterfactual questions to the MDP. Our key conclusion is that teams would score more goals if they shot more often from outside the penalty box in a small number of team-specific locations. The proposed framework can easily be extended and applied to analyze other aspects of the game.