 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Density EEG Enables the Fastest Visual Brain-Computer Interfaces
Jul 23, 2025Brain-computer interface (BCI) technology establishes a direct communication pathway between the brain and external devices. Current visual BCI systems suffer from insufficient information transfer rates (ITRs) for practical use. Spatial information, a critical component of visual perception, remains underexploited in existing systems because the limited spatial resolution of recording methods hinders the capture of the rich spatiotemporal dynamics of brain signals. This study proposed a frequency-phase-space fusion encoding method, integrated with 256-channel high-density electroencephalogram (EEG) recordings, to develop high-speed BCI systems. In the classical frequency-phase encoding 40-target BCI paradigm, the 256-66, 128-32, and 64-21 electrode configurations brought theoretical ITR increases of 83.66%, 79.99%, and 55.50% over the traditional 64-9 setup. In the proposed frequency-phase-space encoding 200-target BCI paradigm, these increases climbed to 195.56%, 153.08%, and 103.07%. The online BCI system achieved an average actual ITR of 472.7 bpm. This study demonstrates the essential role and immense potential of high-density EEG in decoding the spatiotemporal information of visual stimuli.
Visual tracking brain computer interface
Nov 21, 2023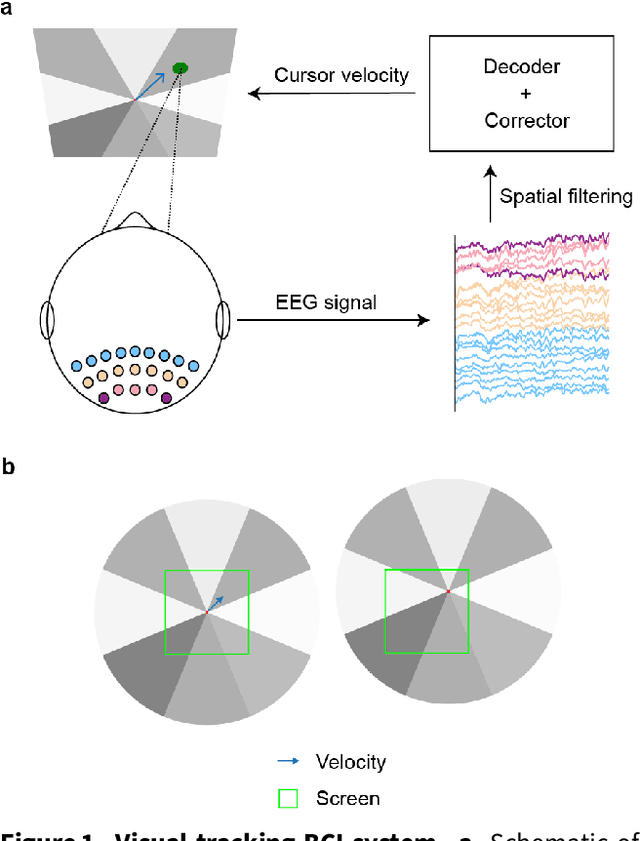
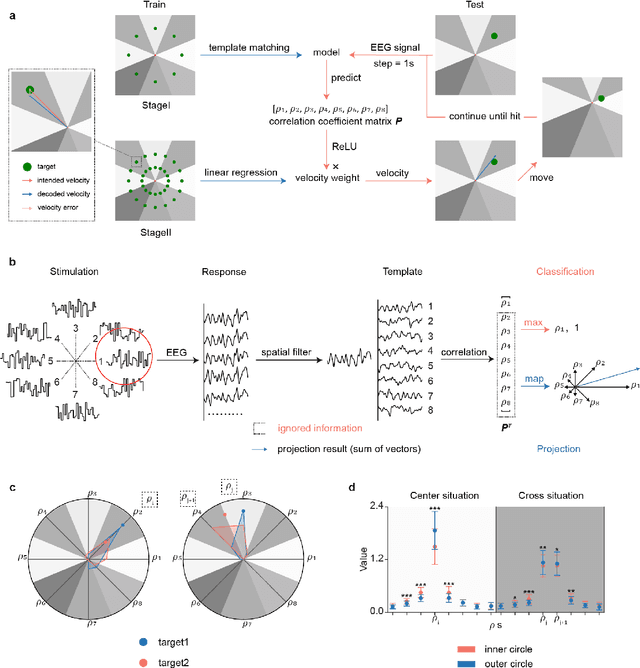
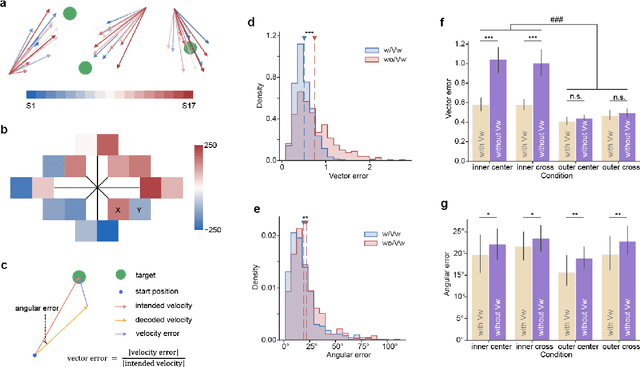
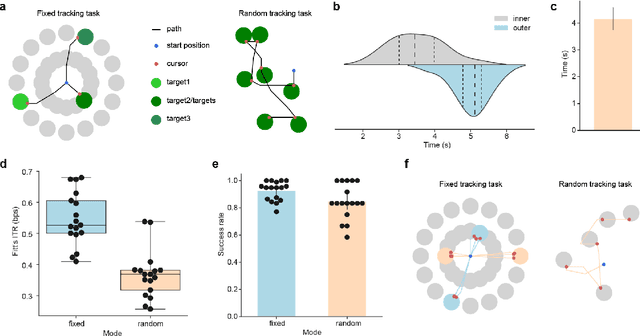
Brain-computer interfaces (BCIs) offer a way to interact with computers without relying on physical movements. Non-invasive electroencephalography (EEG)-based visual BCIs, known for efficient speed and calibration ease, face limitations in continuous tasks due to discrete stimulus design and decoding methods. To achieve continuous control, we implemented a novel spatial encoding stimulus paradigm and devised a corresponding projection method to enable continuous modulation of decoded velocity. Subsequently, we conducted experiments involving 17 participants and achieved Fitt's ITR of 0.55 bps for the fixed tracking task and 0.37 bps for the random tracking task. The proposed BCI with a high Fitt's ITR was then integrated into two applications, including painting and gaming. In conclusion, this study proposed a visual BCI-based control method to go beyond discrete commands, allowing natural continuous control based on neural activity.
High-performance cVEP-BCI under minimal calibration
Nov 20, 2023The ultimate goal of brain-computer interfaces (BCIs) based on visual modulation paradigms is to achieve high-speed performance without the burden of extensive calibration. Code-modulated visual evoked potential-based BCIs (cVEP-BCIs) modulated by broadband white noise (WN) offer various advantages, including increased communication speed, expanded encoding target capabilities, and enhanced coding flexibility. However, the complexity of the spatial-temporal patterns under broadband stimuli necessitates extensive calibration for effective target identification in cVEP-BCIs. Consequently, the information transfer rate (ITR) of cVEP-BCI under limited calibration usually stays around 100 bits per minute (bpm), significantly lagging behind state-of-the-art steady-state visual evoked potential-based BCIs (SSVEP-BCIs), which achieve rates above 200 bpm. To enhance the performance of cVEP-BCIs with minimal calibration, we devised an efficient calibration stage involving a brief single-target flickering, lasting less than a minute, to extract generalizable spatial-temporal patterns. Leveraging the calibration data, we developed two complementary methods to construct cVEP temporal patterns: the linear modeling method based on the stimulus sequence and the transfer learning techniques using cross-subject data. As a result, we achieved the highest ITR of 250 bpm under a minute of calibration, which has been shown to be comparable to the state-of-the-art SSVEP paradigms. In summary, our work significantly improved the cVEP performance under few-shot learning, which is expected to expand the practicality and usability of cVEP-BCIs.
Estimating and approaching maximum information rate of noninvasive visual brain-computer interface
Aug 25, 2023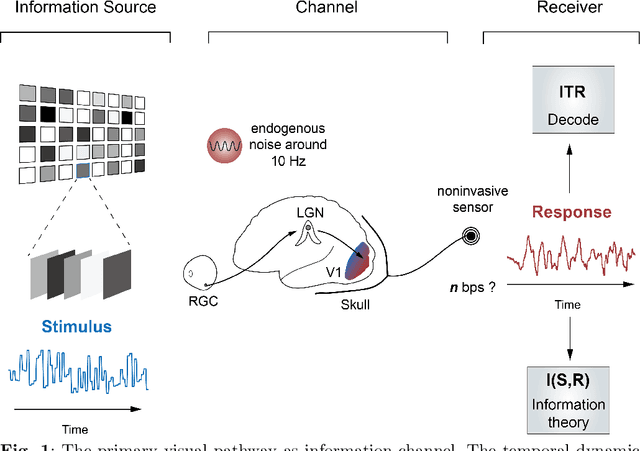
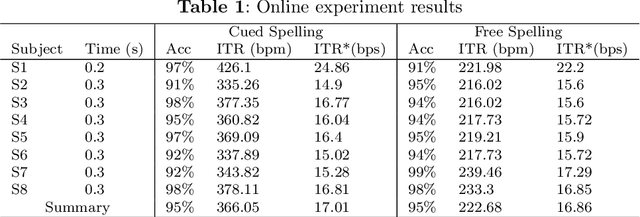
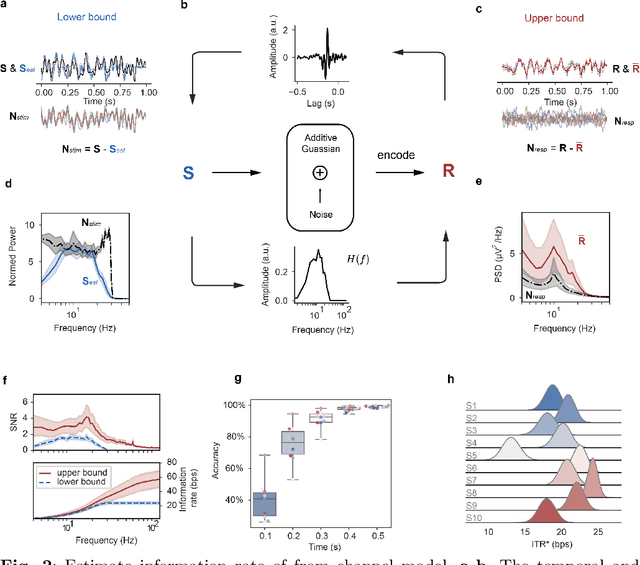

The mission of visual brain-computer interfaces (BCIs) is to enhance information transfer rate (ITR) to reach high speed towards real-life communication. Despite notable progress, noninvasive visual BCIs have encountered a plateau in ITRs, leaving it uncertain whether higher ITRs are achievable. In this study, we investigate the information rate limits of the primary visual channel to explore whether we can and how we should build visual BCI with higher information rate. Using information theory, we estimate a maximum achievable ITR of approximately 63 bits per second (bps) with a uniformly-distributed White Noise (WN) stimulus. Based on this discovery, we propose a broadband WN BCI approach that expands the utilization of stimulus bandwidth, in contrast to the current state-of-the-art visual BCI methods based on steady-state visual evoked potentials (SSVEPs). Through experimental validation, our broadband BCI outperforms the SSVEP BCI by an impressive margin of 7 bps, setting a new record of 50 bps. This achievement demonstrates the possibility of decoding 40 classes of noninvasive neural responses within a short duration of only 0.1 seconds. The information-theoretical framework introduced in this study provides valuable insights applicable to all sensory-evoked BCIs, making a significant step towards the development of next-generation human-machine interaction systems.
Online Sequence Clustering Algorithm for Video Trajectory Analysis
May 15, 2023Target tracking and trajectory modeling have important applications in surveillance video analysis and have received great attention in the fields of road safety and community security. In this work, we propose a lightweight real-time video analysis scheme that uses a model learned from motion patterns to monitor the behavior of objects, which can be used for applications such as real-time representation and prediction. The proposed sequence clustering algorithm based on discrete sequences makes the system have continuous online learning ability. The intrinsic repeatability of the target object trajectory is used to automatically construct the behavioral model in the three processes of feature extraction, cluster learning, and model application. In addition to the discretization of trajectory features and simple model applications, this paper focuses on online clustering algorithms and their incremental learning processes. Finally, through the learning of the trajectory model of the actual surveillance video image, the feasibility of the algorithm is verified. And the characteristics and performance of the clustering algorithm are discussed in the analysis. This scheme has real-time online learning and processing of motion models while avoiding a large number of arithmetic operations, which is more in line with the application scenarios of front-end intelligent perception.
Memory-like Adaptive Modeling Multi-Agent Learning System
Dec 15, 2022In this work, we propose a self-supervised multi-agent system, termed a memory-like adaptive modeling multi-agent learning system (MAMMALS), that realizes online learning towards behavioral pattern clustering tasks for time series. Encoding the visual behaviors as discrete time series(DTS), and training and modeling them in the multi-agent system with a bio-memory-like form. We finally implemented a fully decentralized multi-agent system design framework and completed its feasibility verification in a surveillance video application scenario on vehicle path clustering. In multi-agent learning, using learning methods designed for individual agents will typically perform poorly globally because of the behavior of ignoring the synergy between agents.
A Graphical Social Topology Model for Multi-Object Tracking
Sep 29, 2017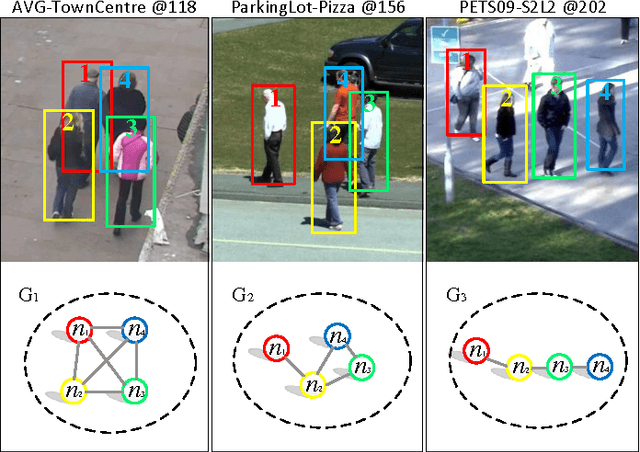

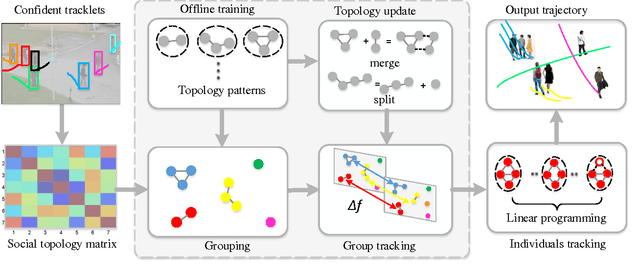
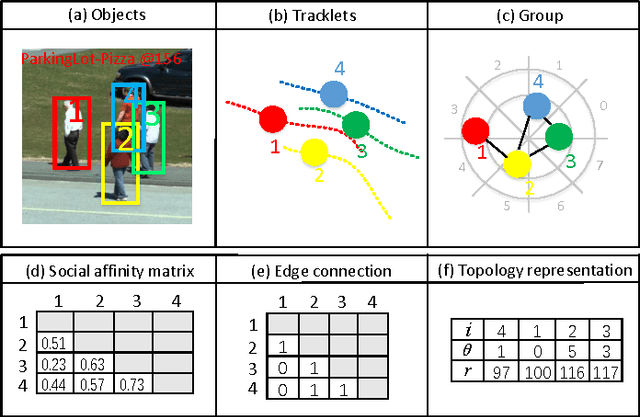
Tracking multiple objects is a challenging task when objects move in groups and occlude each other. Existing methods have investigated the problems of group division and group energy-minimization; however, lacking overall object-group topology modeling limits their ability in handling complex object and group dynamics. Inspired with the social affinity property of moving objects, we propose a Graphical Social Topology (GST) model, which estimates the group dynamics by jointly modeling the group structure and the states of objects using a topological representation. With such topology representation, moving objects are not only assigned to groups, but also dynamically connected with each other, which enables in-group individuals to be correctly associated and the cohesion of each group to be precisely modeled. Using well-designed topology learning modules and topology training, we infer the birth/death and merging/splitting of dynamic groups. With the GST model, the proposed multi-object tracker can naturally facilitate the occlusion problem by treating the occluded object and other in-group members as a whole while leveraging overall state transition. Experiments on both RGB and RGB-D datasets confirm that the proposed multi-object tracker improves the state-of-the-arts especially in crowded scenes.
Robust Guided Image Filtering
Mar 28, 2017


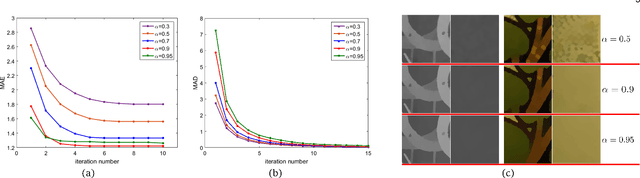
The process of using one image to guide the filtering process of another one is called Guided Image Filtering (GIF). The main challenge of GIF is the structure inconsistency between the guidance image and the target image. Besides, noise in the target image is also a challenging issue especially when it is heavy. In this paper, we propose a general framework for Robust Guided Image Filtering (RGIF), which contains a data term and a smoothness term, to solve the two issues mentioned above. The data term makes our model simultaneously denoise the target image and perform GIF which is robust against the heavy noise. The smoothness term is able to make use of the property of both the guidance image and the target image which is robust against the structure inconsistency. While the resulting model is highly non-convex, it can be solved through the proposed Iteratively Re-weighted Least Squares (IRLS) in an efficient manner. For challenging applications such as guided depth map upsampling, we further develop a data-driven parameter optimization scheme to properly determine the parameter in our model. This optimization scheme can help to preserve small structures and sharp depth edges even for a large upsampling factor (8x for example). Moreover, the specially designed structure of the data term and the smoothness term makes our model perform well in edge-preserving smoothing for single-image tasks (i.e., the guidance image is the target image itself). This paper is an extension of our previous work [1], [2].
Data Driven Robust Image Guided Depth Map Restoration
Dec 26, 2015
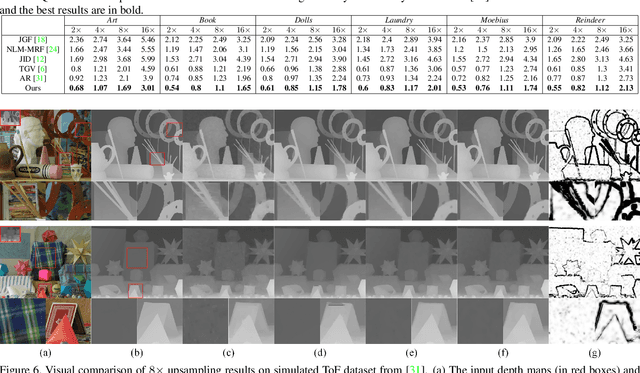
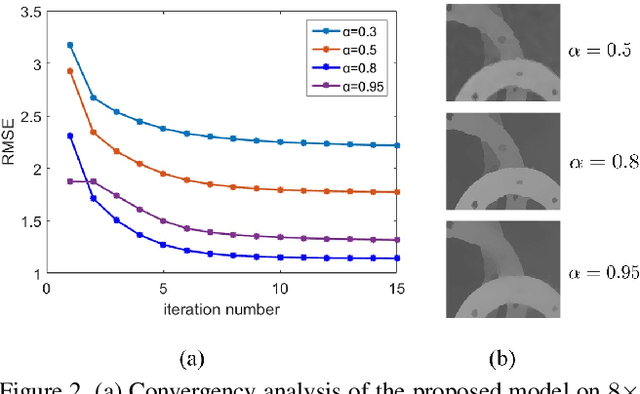
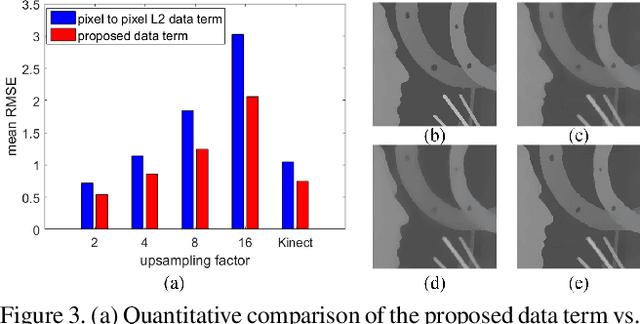
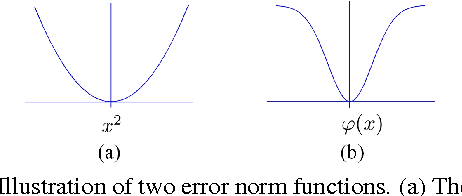
Depth maps captured by modern depth cameras such as Kinect and Time-of-Flight (ToF) are usually contaminated by missing data, noises and suffer from being of low resolution. In this paper, we present a robust method for high-quality restoration of a degraded depth map with the guidance of the corresponding color image. We solve the problem in an energy optimization framework that consists of a novel robust data term and smoothness term. To accommodate not only the noise but also the inconsistency between depth discontinuities and the color edges, we model both the data term and smoothness term with a robust exponential error norm function. We propose to use Iteratively Re-weighted Least Squares (IRLS) methods for efficiently solving the resulting highly non-convex optimization problem. More importantly, we further develop a data-driven adaptive parameter selection scheme to properly determine the parameter in the model. We show that the proposed approach can preserve fine details and sharp depth discontinuities even for a large upsampling factor ($8\times$ for example). Experimental results on both simulated and real datasets demonstrate that the proposed method outperforms recent state-of-the-art methods in coping with the heavy noise, preserving sharp depth discontinuities and suppressing the texture copy artifacts.
Robust High Quality Image Guided Depth Upsampling
Jun 17, 2015


Time-of-Flight (ToF) depth sensing camera is able to obtain depth maps at a high frame rate. However, its low resolution and sensitivity to the noise are always a concern. A popular solution is upsampling the obtained noisy low resolution depth map with the guidance of the companion high resolution color image. However, due to the constrains in the existing upsampling models, the high resolution depth map obtained in such way may suffer from either texture copy artifacts or blur of depth discontinuity. In this paper, a novel optimization framework is proposed with the brand new data term and smoothness term. The comprehensive experiments using both synthetic data and real data show that the proposed method well tackles the problem of texture copy artifacts and blur of depth discontinuity. It also demonstrates sufficient robustness to the noise. Moreover, a data driven scheme is proposed to adaptively estimate the parameter in the upsampling optimization framework. The encouraging performance is maintained even in the case of large upsampling e.g. $8\times$ and $16\times$.