 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenDial: Continuous Attribute Control in Text-to-Video via Spatiotemporal Token Offsets
Mar 29, 2026We present TokenDial, a framework for continuous, slider-style attribute control in pretrained text-to-video generation models. While modern generators produce strong holistic videos, they offer limited control over how much an attribute changes (e.g., effect intensity or motion magnitude) without drifting identity, background, or temporal coherence. TokenDial is built on the observation: additive offsets in the intermediate spatiotemporal visual patch-token space form a semantic control direction, where adjusting the offset magnitude yields coherent, predictable edits for both appearance and motion dynamics. We learn attribute-specific token offsets without retraining the backbone, using pretrained understanding signals: semantic direction matching for appearance and motion-magnitude scaling for motion. We demonstrate TokenDial's effectiveness on diverse attributes and prompts, achieving stronger controllability and higher-quality edits than state-of-the-art baselines, supported by extensive quantitative evaluation and human studies.
Controllable Layered Image Generation for Real-World Editing
Jan 21, 2026Recent image generation models have shown impressive progress, yet they often struggle to yield controllable and consistent results when users attempt to edit specific elements within an existing image. Layered representations enable flexible, user-driven content creation, but existing approaches often fail to produce layers with coherent compositing relationships, and their object layers typically lack realistic visual effects such as shadows and reflections. To overcome these limitations, we propose LASAGNA, a novel, unified framework that generates an image jointly with its composing layers--a photorealistic background and a high-quality transparent foreground with compelling visual effects. Unlike prior work, LASAGNA efficiently learns correct image composition from a wide range of conditioning inputs--text prompts, foreground, background, and location masks--offering greater controllability for real-world applications. To enable this, we introduce LASAGNA-48K, a new dataset composed of clean backgrounds and RGBA foregrounds with physically grounded visual effects. We also propose LASAGNABENCH, the first benchmark for layer editing. We demonstrate that LASAGNA excels in generating highly consistent and coherent results across multiple image layers simultaneously, enabling diverse post-editing applications that accurately preserve identity and visual effects. LASAGNA-48K and LASAGNABENCH will be publicly released to foster open research in the community. The project page is https://rayjryang.github.io/LASAGNA-Page/.
DecisionLLM: Large Language Models for Long Sequence Decision Exploration
Jan 15, 2026Long-sequence decision-making, which is usually addressed through reinforcement learning (RL), is a critical component for optimizing strategic operations in dynamic environments, such as real-time bidding in computational advertising. The Decision Transformer (DT) introduced a powerful paradigm by framing RL as an autoregressive sequence modeling problem. Concurrently, Large Language Models (LLMs) have demonstrated remarkable success in complex reasoning and planning tasks. This inspires us whether LLMs, which share the same Transformer foundation, but operate at a much larger scale, can unlock new levels of performance in long-horizon sequential decision-making problem. This work investigates the application of LLMs to offline decision making tasks. A fundamental challenge in this domain is the LLMs' inherent inability to interpret continuous values, as they lack a native understanding of numerical magnitude and order when values are represented as text strings. To address this, we propose treating trajectories as a distinct modality. By learning to align trajectory data with natural language task descriptions, our model can autoregressively predict future decisions within a cohesive framework we term DecisionLLM. We establish a set of scaling laws governing this paradigm, demonstrating that performance hinges on three factors: model scale, data volume, and data quality. In offline experimental benchmarks and bidding scenarios, DecisionLLM achieves strong performance. Specifically, DecisionLLM-3B outperforms the traditional Decision Transformer (DT) by 69.4 on Maze2D umaze-v1 and by 0.085 on AuctionNet. It extends the AIGB paradigm and points to promising directions for future exploration in online bidding.
VerifyBench: Benchmarking Reference-based Reward Systems for Large Language Models
May 21, 2025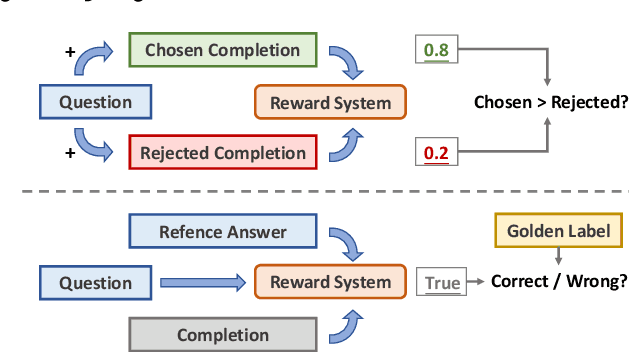
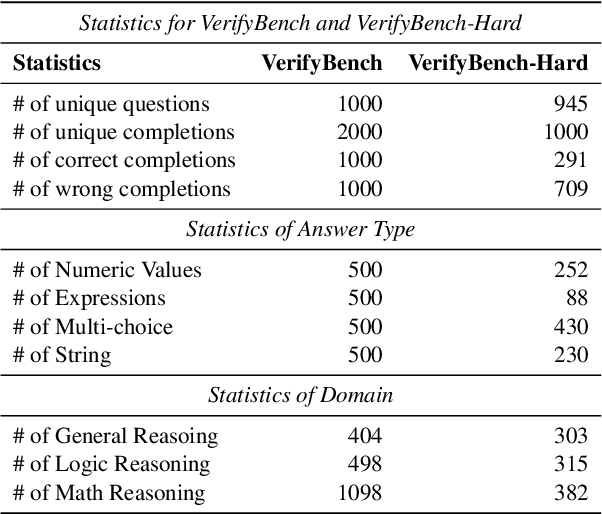
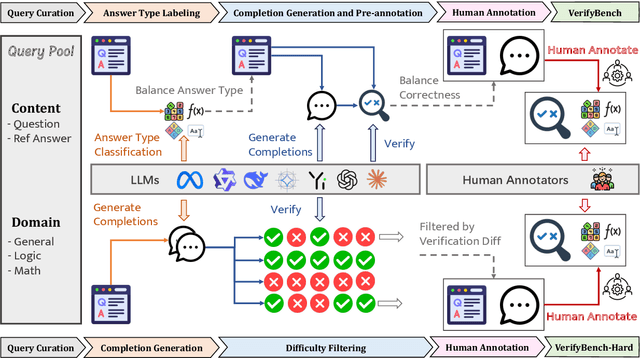
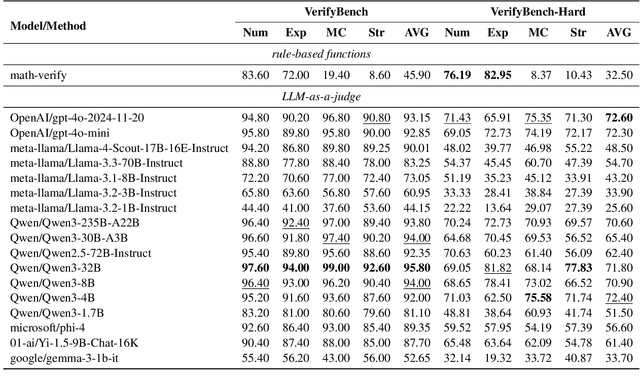
Large reasoning models such as OpenAI o1 and DeepSeek-R1 have achieved remarkable performance in the domain of reasoning. A key component of their training is the incorporation of verifiable rewards within reinforcement learning (RL). However, existing reward benchmarks do not evaluate reference-based reward systems, leaving researchers with limited understanding of the accuracy of verifiers used in RL. In this paper, we introduce two benchmarks, VerifyBench and VerifyBench-Hard, designed to assess the performance of reference-based reward systems. These benchmarks are constructed through meticulous data collection and curation, followed by careful human annotation to ensure high quality. Current models still show considerable room for improvement on both VerifyBench and VerifyBench-Hard, especially smaller-scale models. Furthermore, we conduct a thorough and comprehensive analysis of evaluation results, offering insights for understanding and developing reference-based reward systems. Our proposed benchmarks serve as effective tools for guiding the development of verifier accuracy and the reasoning capabilities of models trained via RL in reasoning tasks.
X-Fusion: Introducing New Modality to Frozen Large Language Models
Apr 29, 2025We propose X-Fusion, a framework that extends pretrained Large Language Models (LLMs) for multimodal tasks while preserving their language capabilities. X-Fusion employs a dual-tower design with modality-specific weights, keeping the LLM's parameters frozen while integrating vision-specific information for both understanding and generation. Our experiments demonstrate that X-Fusion consistently outperforms alternative architectures on both image-to-text and text-to-image tasks. We find that incorporating understanding-focused data improves generation quality, reducing image data noise enhances overall performance, and feature alignment accelerates convergence for smaller models but has minimal impact on larger ones. Our findings provide valuable insights into building efficient unified multimodal models.
Distributionally Robust Policy Evaluation and Learning for Continuous Treatment with Observational Data
Jan 18, 2025Using offline observational data for policy evaluation and learning allows decision-makers to evaluate and learn a policy that connects characteristics and interventions. Most existing literature has focused on either discrete treatment spaces or assumed no difference in the distributions between the policy-learning and policy-deployed environments. These restrict applications in many real-world scenarios where distribution shifts are present with continuous treatment. To overcome these challenges, this paper focuses on developing a distributionally robust policy under a continuous treatment setting. The proposed distributionally robust estimators are established using the Inverse Probability Weighting (IPW) method extended from the discrete one for policy evaluation and learning under continuous treatments. Specifically, we introduce a kernel function into the proposed IPW estimator to mitigate the exclusion of observations that can occur in the standard IPW method to continuous treatments. We then provide finite-sample analysis that guarantees the convergence of the proposed distributionally robust policy evaluation and learning estimators. The comprehensive experiments further verify the effectiveness of our approach when distribution shifts are present.
TransPixar: Advancing Text-to-Video Generation with Transparency
Jan 06, 2025



Text-to-video generative models have made significant strides, enabling diverse applications in entertainment, advertising, and education. However, generating RGBA video, which includes alpha channels for transparency, remains a challenge due to limited datasets and the difficulty of adapting existing models. Alpha channels are crucial for visual effects (VFX), allowing transparent elements like smoke and reflections to blend seamlessly into scenes. We introduce TransPixar, a method to extend pretrained video models for RGBA generation while retaining the original RGB capabilities. TransPixar leverages a diffusion transformer (DiT) architecture, incorporating alpha-specific tokens and using LoRA-based fine-tuning to jointly generate RGB and alpha channels with high consistency. By optimizing attention mechanisms, TransPixar preserves the strengths of the original RGB model and achieves strong alignment between RGB and alpha channels despite limited training data. Our approach effectively generates diverse and consistent RGBA videos, advancing the possibilities for VFX and interactive content creation.
Generative Video Propagation
Dec 27, 2024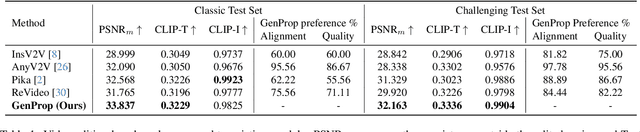
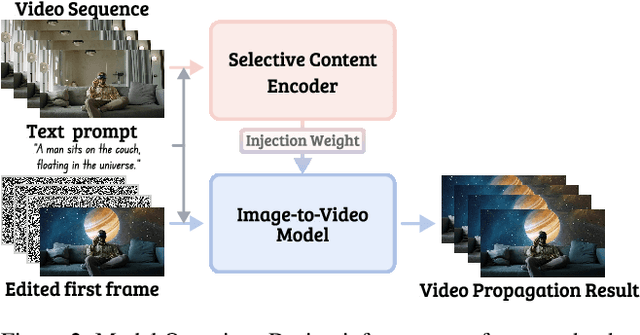
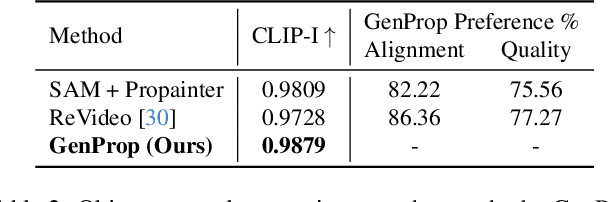
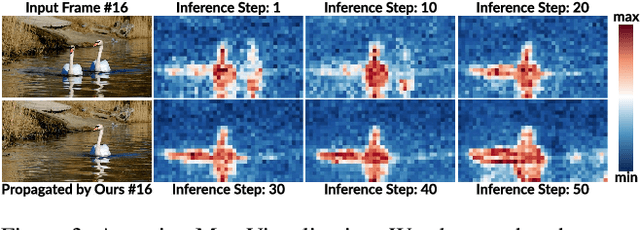
Large-scale video generation models have the inherent ability to realistically model natural scenes. In this paper, we demonstrate that through a careful design of a generative video propagation framework, various video tasks can be addressed in a unified way by leveraging the generative power of such models. Specifically, our framework, GenProp, encodes the original video with a selective content encoder and propagates the changes made to the first frame using an image-to-video generation model. We propose a data generation scheme to cover multiple video tasks based on instance-level video segmentation datasets. Our model is trained by incorporating a mask prediction decoder head and optimizing a region-aware loss to aid the encoder to preserve the original content while the generation model propagates the modified region. This novel design opens up new possibilities: In editing scenarios, GenProp allows substantial changes to an object's shape; for insertion, the inserted objects can exhibit independent motion; for removal, GenProp effectively removes effects like shadows and reflections from the whole video; for tracking, GenProp is capable of tracking objects and their associated effects together. Experiment results demonstrate the leading performance of our model in various video tasks, and we further provide in-depth analyses of the proposed framework.
UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
Dec 10, 2024



We introduce UniReal, a unified framework designed to address various image generation and editing tasks. Existing solutions often vary by tasks, yet share fundamental principles: preserving consistency between inputs and outputs while capturing visual variations. Inspired by recent video generation models that effectively balance consistency and variation across frames, we propose a unifying approach that treats image-level tasks as discontinuous video generation. Specifically, we treat varying numbers of input and output images as frames, enabling seamless support for tasks such as image generation, editing, customization, composition, etc. Although designed for image-level tasks, we leverage videos as a scalable source for universal supervision. UniReal learns world dynamics from large-scale videos, demonstrating advanced capability in handling shadows, reflections, pose variation, and object interaction, while also exhibiting emergent capability for novel applications.
LayerFusion: Harmonized Multi-Layer Text-to-Image Generation with Generative Priors
Dec 05, 2024
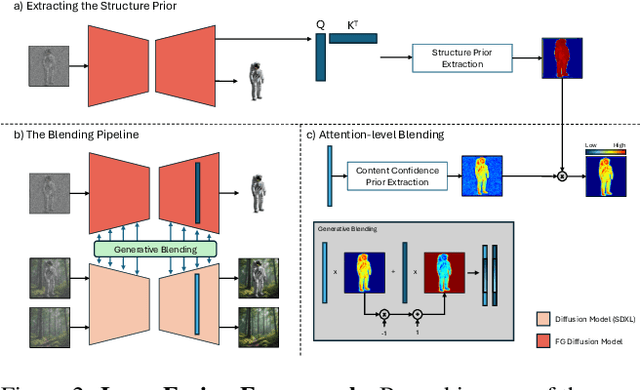

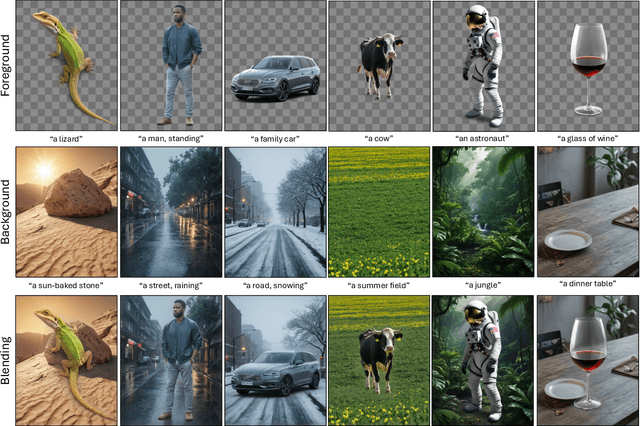
Large-scale diffusion models have achieved remarkable success in generating high-quality images from textual descriptions, gaining popularity across various applications. However, the generation of layered content, such as transparent images with foreground and background layers, remains an under-explored area. Layered content generation is crucial for creative workflows in fields like graphic design, animation, and digital art, where layer-based approaches are fundamental for flexible editing and composition. In this paper, we propose a novel image generation pipeline based on Latent Diffusion Models (LDMs) that generates images with two layers: a foreground layer (RGBA) with transparency information and a background layer (RGB). Unlike existing methods that generate these layers sequentially, our approach introduces a harmonized generation mechanism that enables dynamic interactions between the layers for more coherent outputs. We demonstrate the effectiveness of our method through extensive qualitative and quantitative experiments, showing significant improvements in visual coherence, image quality, and layer consistency compared to baseline methods.