 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Layered Image Generation for Real-World Editing
Jan 21, 2026Recent image generation models have shown impressive progress, yet they often struggle to yield controllable and consistent results when users attempt to edit specific elements within an existing image. Layered representations enable flexible, user-driven content creation, but existing approaches often fail to produce layers with coherent compositing relationships, and their object layers typically lack realistic visual effects such as shadows and reflections. To overcome these limitations, we propose LASAGNA, a novel, unified framework that generates an image jointly with its composing layers--a photorealistic background and a high-quality transparent foreground with compelling visual effects. Unlike prior work, LASAGNA efficiently learns correct image composition from a wide range of conditioning inputs--text prompts, foreground, background, and location masks--offering greater controllability for real-world applications. To enable this, we introduce LASAGNA-48K, a new dataset composed of clean backgrounds and RGBA foregrounds with physically grounded visual effects. We also propose LASAGNABENCH, the first benchmark for layer editing. We demonstrate that LASAGNA excels in generating highly consistent and coherent results across multiple image layers simultaneously, enabling diverse post-editing applications that accurately preserve identity and visual effects. LASAGNA-48K and LASAGNABENCH will be publicly released to foster open research in the community. The project page is https://rayjryang.github.io/LASAGNA-Page/.
Generative Image Layer Decomposition with Visual Effects
Nov 26, 2024



Recent advancements in large generative models, particularly diffusion-based methods, have significantly enhanced the capabilities of image editing. However, achieving precise control over image composition tasks remains a challenge. Layered representations, which allow for independent editing of image components, are essential for user-driven content creation, yet existing approaches often struggle to decompose image into plausible layers with accurately retained transparent visual effects such as shadows and reflections. We propose $\textbf{LayerDecomp}$, a generative framework for image layer decomposition which outputs photorealistic clean backgrounds and high-quality transparent foregrounds with faithfully preserved visual effects. To enable effective training, we first introduce a dataset preparation pipeline that automatically scales up simulated multi-layer data with synthesized visual effects. To further enhance real-world applicability, we supplement this simulated dataset with camera-captured images containing natural visual effects. Additionally, we propose a consistency loss which enforces the model to learn accurate representations for the transparent foreground layer when ground-truth annotations are not available. Our method achieves superior quality in layer decomposition, outperforming existing approaches in object removal and spatial editing tasks across several benchmarks and multiple user studies, unlocking various creative possibilities for layer-wise image editing. The project page is https://rayjryang.github.io/LayerDecomp.
Scaling White-Box Transformers for Vision
Jun 03, 2024



CRATE, a white-box transformer architecture designed to learn compressed and sparse representations, offers an intriguing alternative to standard vision transformers (ViTs) due to its inherent mathematical interpretability. Despite extensive investigations into the scaling behaviors of language and vision transformers, the scalability of CRATE remains an open question which this paper aims to address. Specifically, we propose CRATE-$\alpha$, featuring strategic yet minimal modifications to the sparse coding block in the CRATE architecture design, and a light training recipe designed to improve the scalability of CRATE. Through extensive experiments, we demonstrate that CRATE-$\alpha$ can effectively scale with larger model sizes and datasets. For example, our CRATE-$\alpha$-B substantially outperforms the prior best CRATE-B model accuracy on ImageNet classification by 3.7%, achieving an accuracy of 83.2%. Meanwhile, when scaling further, our CRATE-$\alpha$-L obtains an ImageNet classification accuracy of 85.1%. More notably, these model performance improvements are achieved while preserving, and potentially even enhancing the interpretability of learned CRATE models, as we demonstrate through showing that the learned token representations of increasingly larger trained CRATE-$\alpha$ models yield increasingly higher-quality unsupervised object segmentation of images. The project page is https://rayjryang.github.io/CRATE-alpha/.
ActionHub: A Large-scale Action Video Description Dataset for Zero-shot Action Recognition
Jan 22, 2024Zero-shot action recognition (ZSAR) aims to learn an alignment model between videos and class descriptions of seen actions that is transferable to unseen actions. The text queries (class descriptions) used in existing ZSAR works, however, are often short action names that fail to capture the rich semantics in the videos, leading to misalignment. With the intuition that video content descriptions (e.g., video captions) can provide rich contextual information of visual concepts in videos, we propose to utilize human annotated video descriptions to enrich the semantics of the class descriptions of each action. However, all existing action video description datasets are limited in terms of the number of actions, the semantics of video descriptions, etc. To this end, we collect a large-scale action video descriptions dataset named ActionHub, which covers a total of 1,211 common actions and provides 3.6 million action video descriptions. With the proposed ActionHub dataset, we further propose a novel Cross-modality and Cross-action Modeling (CoCo) framework for ZSAR, which consists of a Dual Cross-modality Alignment module and a Cross-action Invariance Mining module. Specifically, the Dual Cross-modality Alignment module utilizes both action labels and video descriptions from ActionHub to obtain rich class semantic features for feature alignment. The Cross-action Invariance Mining module exploits a cycle-reconstruction process between the class semantic feature spaces of seen actions and unseen actions, aiming to guide the model to learn cross-action invariant representations. Extensive experimental results demonstrate that our CoCo framework significantly outperforms the state-of-the-art on three popular ZSAR benchmarks (i.e., Kinetics-ZSAR, UCF101 and HMDB51) under two different learning protocols in ZSAR. We will release our code, models, and the proposed ActionHub dataset.
Multi-EuP: The Multilingual European Parliament Dataset for Analysis of Bias in Information Retrieval
Nov 03, 2023



We present Multi-EuP, a new multilingual benchmark dataset, comprising 22K multi-lingual documents collected from the European Parliament, spanning 24 languages. This dataset is designed to investigate fairness in a multilingual information retrieval (IR) context to analyze both language and demographic bias in a ranking context. It boasts an authentic multilingual corpus, featuring topics translated into all 24 languages, as well as cross-lingual relevance judgments. Furthermore, it offers rich demographic information associated with its documents, facilitating the study of demographic bias. We report the effectiveness of Multi-EuP for benchmarking both monolingual and multilingual IR. We also conduct a preliminary experiment on language bias caused by the choice of tokenization strategy.
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Jul 02, 2023
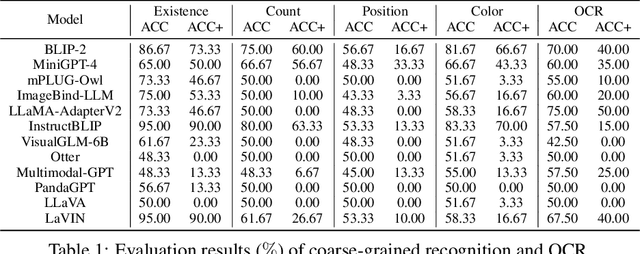
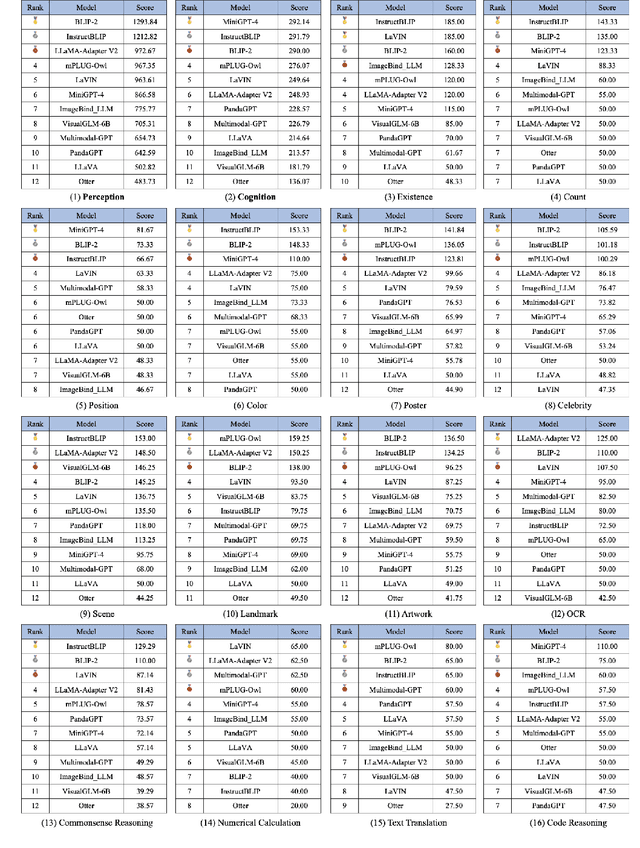
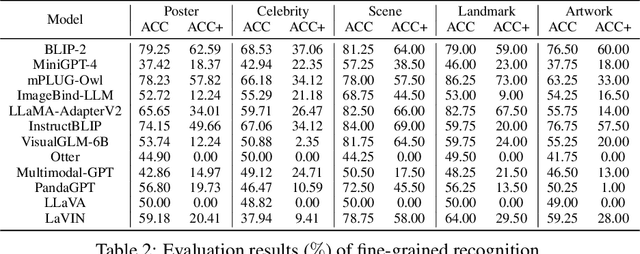
Multimodal Large Language Model (MLLM) relies on the powerful LLM to perform multimodal tasks, showing amazing emergent abilities in recent studies, such as writing poems based on an image. However, it is difficult for these case studies to fully reflect the performance of MLLM, lacking a comprehensive evaluation. In this paper, we fill in this blank, presenting the first MLLM Evaluation benchmark MME. It measures both perception and cognition abilities on a total of 14 subtasks. In order to avoid data leakage that may arise from direct use of public datasets for evaluation, the annotations of instruction-answer pairs are all manually designed. The concise instruction design allows us to fairly compare MLLMs, instead of struggling in prompt engineering. Besides, with such an instruction, we can also easily carry out quantitative statistics. A total of 12 advanced MLLMs are comprehensively evaluated on our MME, which not only suggests that existing MLLMs still have a large room for improvement, but also reveals the potential directions for the subsequent model optimization.
Towards Open-Domain Topic Classification
Jun 29, 2023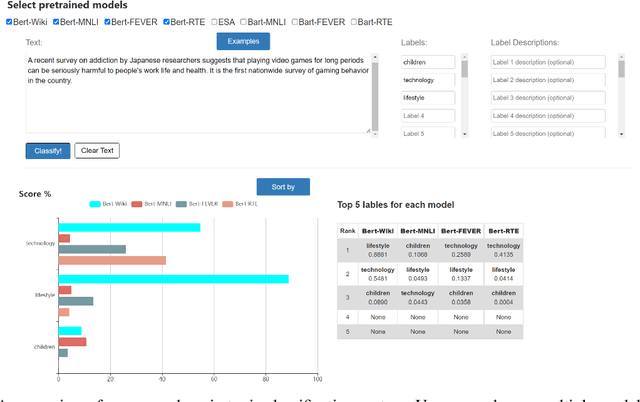



We introduce an open-domain topic classification system that accepts user-defined taxonomy in real time. Users will be able to classify a text snippet with respect to any candidate labels they want, and get instant response from our web interface. To obtain such flexibility, we build the backend model in a zero-shot way. By training on a new dataset constructed from Wikipedia, our label-aware text classifier can effectively utilize implicit knowledge in the pretrained language model to handle labels it has never seen before. We evaluate our model across four datasets from various domains with different label sets. Experiments show that the model significantly improves over existing zero-shot baselines in open-domain scenarios, and performs competitively with weakly-supervised models trained on in-domain data.
Professional Presentation and Projected Power: A Case Study of Implicit Gender Information in English CVs
Nov 17, 2022



Gender discrimination in hiring is a pertinent and persistent bias in society, and a common motivating example for exploring bias in NLP. However, the manifestation of gendered language in application materials has received limited attention. This paper investigates the framing of skills and background in CVs of self-identified men and women. We introduce a data set of 1.8K authentic, English-language, CVs from the US, covering 16 occupations, allowing us to partially control for the confound occupation-specific gender base rates. We find that (1) women use more verbs evoking impressions of low power; and (2) classifiers capture gender signal even after data balancing and removal of pronouns and named entities, and this holds for both transformer-based and linear classifiers.