 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Dataset Condensation for Diffusion Model Training
Jun 04, 2026Dataset condensation aims to construct compact datasets from real data via synthesis or selection. However, existing approaches are ill-suited for diffusion model training: synthetic data generation often yields low-fidelity samples unsuitable for authentic modeling, while real subset selection typically fails to preserve the distributional geometry required by diffusion likelihood objectives. To address this, we propose to reformulate real subset selection as a geometry-aware distribution alignment problem. By incorporating one-sided partial optimal transport, our method selectively aligns a compact subset with the full data distribution while allowing unmatched mass in low-density regions, ensuring the preserved geometric structure necessary for effective diffusion model training. To further ensure distributional fidelity, we complement geometric alignment with lightweight feature-statistics and semantic consistency regularization. An efficient two-stage discrete optimization strategy is proposed to achieve this alignment objective. Extensive experiments across diffusion variants, subset sizes, image resolutions, and training rounds show that our method achieves superior fidelity and distributional coverage in diffusion model training. Codes are available at https://github.com/2018cx/GADC.
Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
Dec 31, 2025Existing Large Language Model (LLM) agent frameworks face two significant challenges: high configuration costs and static capabilities. Building a high-quality agent often requires extensive manual effort in tool integration and prompt engineering, while deployed agents struggle to adapt to dynamic environments without expensive fine-tuning. To address these issues, we propose \textbf{Youtu-Agent}, a modular framework designed for the automated generation and continuous evolution of LLM agents. Youtu-Agent features a structured configuration system that decouples execution environments, toolkits, and context management, enabling flexible reuse and automated synthesis. We introduce two generation paradigms: a \textbf{Workflow} mode for standard tasks and a \textbf{Meta-Agent} mode for complex, non-standard requirements, capable of automatically generating tool code, prompts, and configurations. Furthermore, Youtu-Agent establishes a hybrid policy optimization system: (1) an \textbf{Agent Practice} module that enables agents to accumulate experience and improve performance through in-context optimization without parameter updates; and (2) an \textbf{Agent RL} module that integrates with distributed training frameworks to enable scalable and stable reinforcement learning of any Youtu-Agents in an end-to-end, large-scale manner. Experiments demonstrate that Youtu-Agent achieves state-of-the-art performance on WebWalkerQA (71.47\%) and GAIA (72.8\%) using open-weight models. Our automated generation pipeline achieves over 81\% tool synthesis success rate, while the Practice module improves performance on AIME 2024/2025 by +2.7\% and +5.4\% respectively. Moreover, our Agent RL training achieves 40\% speedup with steady performance improvement on 7B LLMs, enhancing coding/reasoning and searching capabilities respectively up to 35\% and 21\% on Maths and general/multi-hop QA benchmarks.
SmartSnap: Proactive Evidence Seeking for Self-Verifying Agents
Dec 26, 2025Agentic reinforcement learning (RL) holds great promise for the development of autonomous agents under complex GUI tasks, but its scalability remains severely hampered by the verification of task completion. Existing task verification is treated as a passive, post-hoc process: a verifier (i.e., rule-based scoring script, reward or critic model, and LLM-as-a-Judge) analyzes the agent's entire interaction trajectory to determine if the agent succeeds. Such processing of verbose context that contains irrelevant, noisy history poses challenges to the verification protocols and therefore leads to prohibitive cost and low reliability. To overcome this bottleneck, we propose SmartSnap, a paradigm shift from this passive, post-hoc verification to proactive, in-situ self-verification by the agent itself. We introduce the Self-Verifying Agent, a new type of agent designed with dual missions: to not only complete a task but also to prove its accomplishment with curated snapshot evidences. Guided by our proposed 3C Principles (Completeness, Conciseness, and Creativity), the agent leverages its accessibility to the online environment to perform self-verification on a minimal, decisive set of snapshots. Such evidences are provided as the sole materials for a general LLM-as-a-Judge verifier to determine their validity and relevance. Experiments on mobile tasks across model families and scales demonstrate that our SmartSnap paradigm allows training LLM-driven agents in a scalable manner, bringing performance gains up to 26.08% and 16.66% respectively to 8B and 30B models. The synergizing between solution finding and evidence seeking facilitates the cultivation of efficient, self-verifying agents with competitive performance against DeepSeek V3.1 and Qwen3-235B-A22B.
Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
Sep 26, 2025
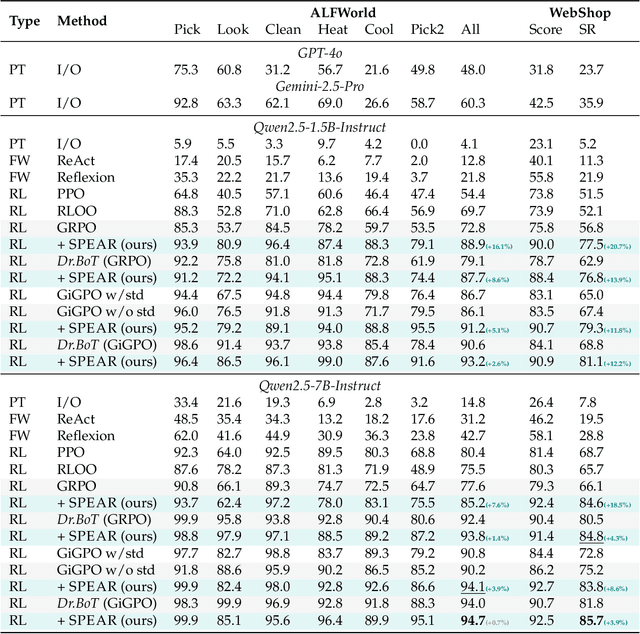
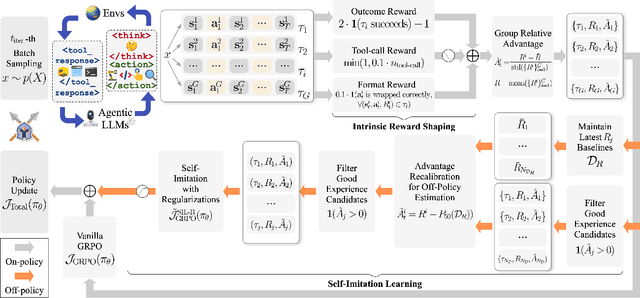
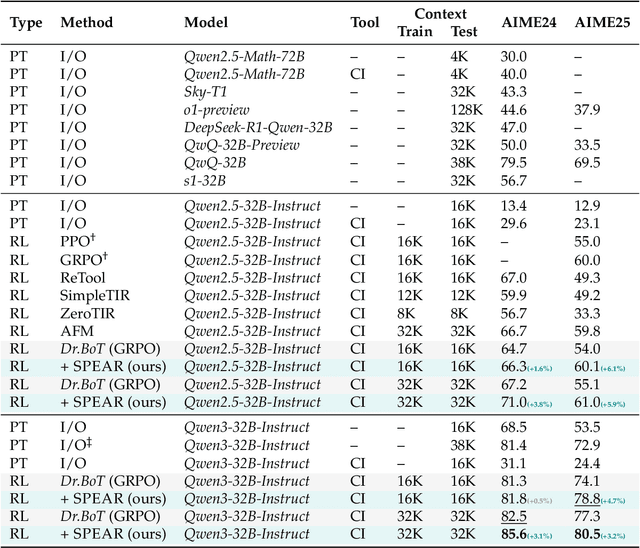
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL training instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a curriculum-based self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL framework, where a replay buffer stores self-generated promising trajectories for off-policy update, by gradually steering the policy evolution within a well-balanced range of entropy across stages. Specifically, our approach incorporates a curriculum to manage the exploration process, utilizing intrinsic rewards to foster skill-level exploration and facilitating action-level exploration through SIL. At first, the auxiliary tool call reward plays a critical role in the accumulation of tool-use skills, enabling broad exposure to the unfamiliar distributions of the environment feedback with an upward entropy trend. As training progresses, self-imitation gets strengthened to exploit existing successful patterns from replayed experiences for comparative action-level exploration, accelerating solution iteration without unbounded entropy growth. To further stabilize training, we recalibrate the advantages of experiences in the replay buffer to address the potential policy drift. Reugularizations such as the clipping of tokens with high covariance between probability and advantage are introduced to the trajectory-level entropy control to curb over-confidence.
Multi-Level Optimal Transport for Universal Cross-Tokenizer Knowledge Distillation on Language Models
Dec 19, 2024

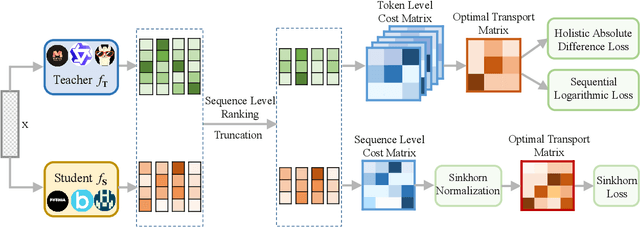

Knowledge distillation (KD) has become a prevalent technique for compressing large language models (LLMs). Existing KD methods are constrained by the need for identical tokenizers (i.e., vocabularies) between teacher and student models, limiting their versatility in handling LLMs of different architecture families. In this paper, we introduce the Multi-Level Optimal Transport (MultiLevelOT), a novel approach that advances the optimal transport for universal cross-tokenizer knowledge distillation. Our method aligns the logit distributions of the teacher and the student at both token and sequence levels using diverse cost matrices, eliminating the need for dimensional or token-by-token correspondence. At the token level, MultiLevelOT integrates both global and local information by jointly optimizing all tokens within a sequence to enhance robustness. At the sequence level, we efficiently capture complex distribution structures of logits via the Sinkhorn distance, which approximates the Wasserstein distance for divergence measures. Extensive experiments on tasks such as extractive QA, generative QA, and summarization demonstrate that the MultiLevelOT outperforms state-of-the-art cross-tokenizer KD methods under various settings. Our approach is robust to different student and teacher models across model families, architectures, and parameter sizes.
Leveraging Open Knowledge for Advancing Task Expertise in Large Language Models
Aug 28, 2024



The cultivation of expertise for large language models (LLMs) to solve tasks of specific areas often requires special-purpose tuning with calibrated behaviors on the expected stable outputs. To avoid huge cost brought by manual preparation of instruction datasets and training resources up to hundreds of hours, the exploitation of open knowledge including a wealth of low rank adaptation (LoRA) models and instruction datasets serves as a good starting point. However, existing methods on model and data selection focus on the performance of general-purpose capabilities while neglecting the knowledge gap exposed in domain-specific deployment. In the present study, we propose to bridge such gap by introducing few human-annotated samples (i.e., K-shot) for advancing task expertise of LLMs with open knowledge. Specifically, we develop an efficient and scalable pipeline to cost-efficiently produce task experts where K-shot data intervene in selecting the most promising expert candidates and the task-relevant instructions. A mixture-of-expert (MoE) system is built to make the best use of individual-yet-complementary knowledge between multiple experts. We unveil the two keys to the success of a MoE system, 1) the abidance by K-shot, and 2) the insistence on diversity. For the former, we ensure that models that truly possess problem-solving abilities on K-shot are selected rather than those blind guessers. Besides, during data selection, instructions that share task-relevant contexts with K-shot are prioritized. For the latter, we highlight the diversity of constituting experts and that of the fine-tuning instructions throughout the model and data selection process. Extensive experimental results confirm the superiority of our approach over existing methods on utilization of open knowledge across various tasks. Codes and models will be released later.
Unleashing the Power of Data Tsunami: A Comprehensive Survey on Data Assessment and Selection for Instruction Tuning of Language Models
Aug 07, 2024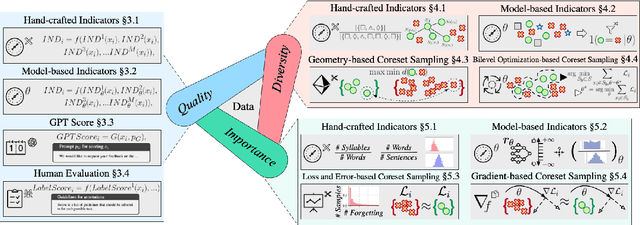
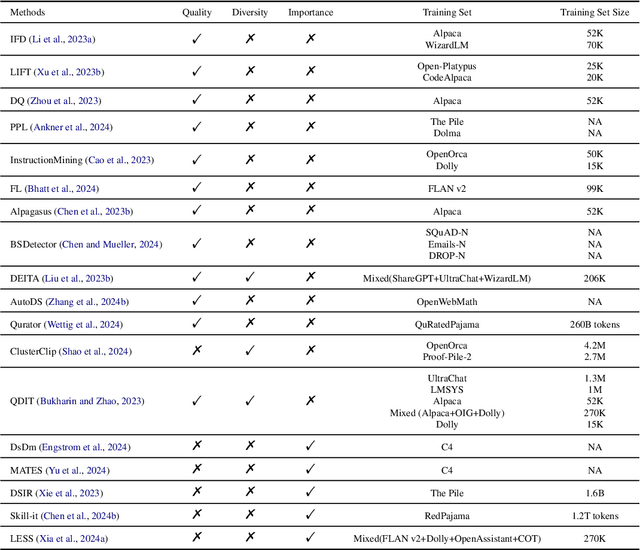
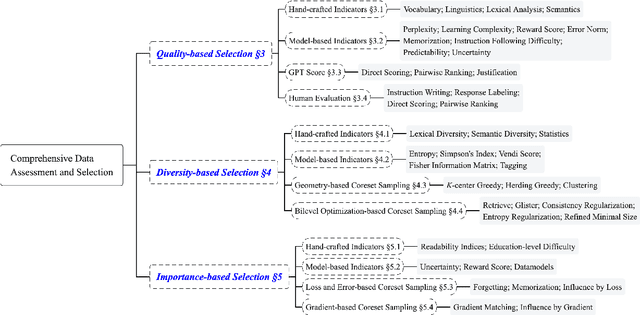
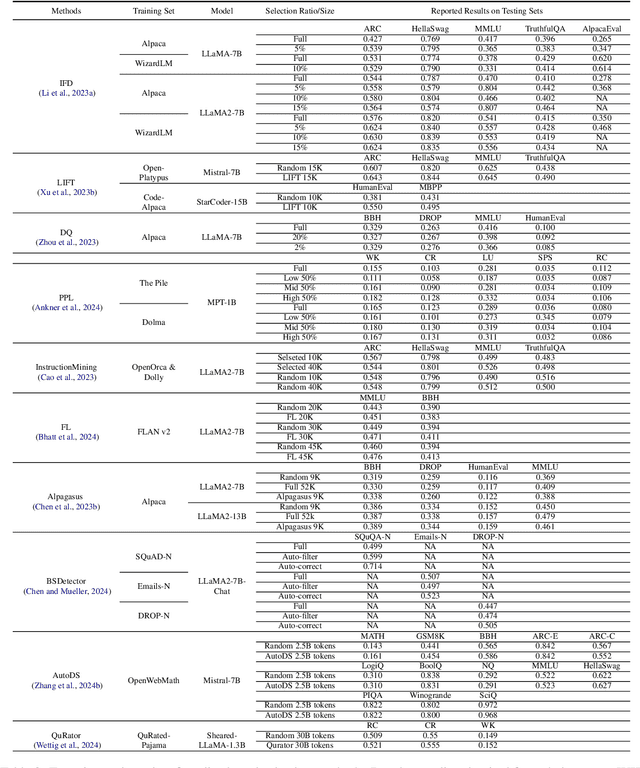
Instruction tuning plays a critical role in aligning large language models (LLMs) with human preference. Despite the vast amount of open instruction datasets, naively training a LLM on all existing instructions may not be optimal and practical. To pinpoint the most beneficial datapoints, data assessment and selection methods have been proposed in the fields of natural language processing (NLP) and deep learning. However, under the context of instruction tuning, there still exists a gap in knowledge on what kind of data evaluation metrics can be employed and how they can be integrated into the selection mechanism. To bridge this gap, we present a comprehensive review on existing literature of data assessment and selection especially for instruction tuning of LLMs. We systematically categorize all applicable methods into quality-based, diversity-based, and importance-based ones where a unified, fine-grained taxonomy is structured. For each category, representative methods are elaborated to describe the landscape of relevant research. In addition, comparison between latest methods is conducted on their officially reported results to provide in-depth discussions on their limitations. Finally, we summarize the open challenges and propose the promosing avenues for future studies. All related contents are available at https://github.com/yuleiqin/fantastic-data-engineering.
RESTORE: Towards Feature Shift for Vision-Language Prompt Learning
Mar 10, 2024



Prompt learning is effective for fine-tuning foundation models to improve their generalization across a variety of downstream tasks. However, the prompts that are independently optimized along a single modality path, may sacrifice the vision-language alignment of pre-trained models in return for improved performance on specific tasks and classes, leading to poorer generalization. In this paper, we first demonstrate that prompt tuning along only one single branch of CLIP (e.g., language or vision) is the reason why the misalignment occurs. Without proper regularization across the learnable parameters in different modalities, prompt learning violates the original pre-training constraints inherent in the two-tower architecture. To address such misalignment, we first propose feature shift, which is defined as the variation of embeddings after introducing the learned prompts, to serve as an explanatory tool. We dive into its relation with generalizability and thereafter propose RESTORE, a multi-modal prompt learning method that exerts explicit constraints on cross-modal consistency. To be more specific, to prevent feature misalignment, a feature shift consistency is introduced to synchronize inter-modal feature shifts by measuring and regularizing the magnitude of discrepancy during prompt tuning. In addition, we propose a "surgery" block to avoid short-cut hacking, where cross-modal misalignment can still be severe if the feature shift of each modality varies drastically at the same rate. It is implemented as feed-forward adapters upon both modalities to alleviate the misalignment problem. Extensive experiments on 15 datasets demonstrate that our method outperforms the state-of-the-art prompt tuning methods without compromising feature alignment.
Sinkhorn Distance Minimization for Knowledge Distillation
Feb 27, 2024



Knowledge distillation (KD) has been widely adopted to compress large language models (LLMs). Existing KD methods investigate various divergence measures including the Kullback-Leibler (KL), reverse Kullback-Leibler (RKL), and Jensen-Shannon (JS) divergences. However, due to limitations inherent in their assumptions and definitions, these measures fail to deliver effective supervision when few distribution overlap exists between the teacher and the student. In this paper, we show that the aforementioned KL, RKL, and JS divergences respectively suffer from issues of mode-averaging, mode-collapsing, and mode-underestimation, which deteriorates logits-based KD for diverse NLP tasks. We propose the Sinkhorn Knowledge Distillation (SinKD) that exploits the Sinkhorn distance to ensure a nuanced and precise assessment of the disparity between teacher and student distributions. Besides, profit by properties of the Sinkhorn metric, we can get rid of sample-wise KD that restricts the perception of divergence in each teacher-student sample pair. Instead, we propose a batch-wise reformulation to capture geometric intricacies of distributions across samples in the high-dimensional space. Comprehensive evaluation on GLUE and SuperGLUE, in terms of comparability, validity, and generalizability, highlights our superiority over state-of-the-art methods on all kinds of LLMs with encoder-only, encoder-decoder, and decoder-only architectures.
Towards Robust Text Retrieval with Progressive Learning
Nov 20, 2023



Retrieval augmentation has become an effective solution to empower large language models (LLMs) with external and verified knowledge sources from the database, which overcomes the limitations and hallucinations of LLMs in handling up-to-date and domain-specific information. However, existing embedding models for text retrieval usually have three non-negligible limitations. First, the number and diversity of samples in a batch are too restricted to supervise the modeling of textual nuances at scale. Second, the high proportional noise are detrimental to the semantic correctness and consistency of embeddings. Third, the equal treatment to easy and difficult samples would cause sub-optimum convergence of embeddings with poorer generalization. In this paper, we propose the PEG, a progressively learned embeddings for robust text retrieval. Specifically, we increase the training in-batch negative samples to 80,000, and for each query, we extracted five hard negatives. Concurrently, we incorporated a progressive learning mechanism, enabling the model to dynamically modulate its attention to the samples throughout the entire training process. Additionally, PEG is trained on more than 100 million data, encompassing a wide range of domains (e.g., finance, medicine, and tourism) and covering various tasks (e.g., question-answering, machine reading comprehension, and similarity matching). Extensive experiments conducted on C-MTEB and DuReader demonstrate that PEG surpasses state-of-the-art embeddings in retrieving true positives, highlighting its significant potential for applications in LLMs. Our model is publicly available at https://huggingface.co/TownsWu/PEG.