 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirway Labeling Meets Clinical Applications: Reflecting Topology Consistency and Outliers via Learnable Attentions
Oct 31, 2024



Accurate airway anatomical labeling is crucial for clinicians to identify and navigate complex bronchial structures during bronchoscopy. Automatic airway anatomical labeling is challenging due to significant individual variability and anatomical variations. Previous methods are prone to generate inconsistent predictions, which is harmful for preoperative planning and intraoperative navigation. This paper aims to address these challenges by proposing a novel method that enhances topological consistency and improves the detection of abnormal airway branches. We propose a novel approach incorporating two modules: the Soft Subtree Consistency (SSC) and the Abnormal Branch Saliency (ABS). The SSC module constructs a soft subtree to capture clinically relevant topological relationships, allowing for flexible feature aggregation within and across subtrees. The ABS module facilitates the interaction between node features and prototypes to distinguish abnormal branches, preventing the erroneous aggregation of features between normal and abnormal nodes. Evaluated on a challenging dataset characterized by severe airway distortion and atrophy, our method achieves superior performance compared to state-of-the-art approaches. Specifically, it attains a 91.4% accuracy at the segmental level and an 83.7% accuracy at the subsegmental level, representing a 1.4% increase in subsegmental accuracy and a 3.1% increase in topological consistency. Notably, the method demonstrates reliable performance in cases with disease-induced airway deformities, ensuring consistent and accurate labeling.
PASS:Test-Time Prompting to Adapt Styles and Semantic Shapes in Medical Image Segmentation
Oct 02, 2024



Test-time adaptation (TTA) has emerged as a promising paradigm to handle the domain shifts at test time for medical images from different institutions without using extra training data. However, existing TTA solutions for segmentation tasks suffer from (1) dependency on modifying the source training stage and access to source priors or (2) lack of emphasis on shape-related semantic knowledge that is crucial for segmentation tasks.Recent research on visual prompt learning achieves source-relaxed adaptation by extended parameter space but still neglects the full utilization of semantic features, thus motivating our work on knowledge-enriched deep prompt learning. Beyond the general concern of image style shifts, we reveal that shape variability is another crucial factor causing the performance drop. To address this issue, we propose a TTA framework called PASS (Prompting to Adapt Styles and Semantic shapes), which jointly learns two types of prompts: the input-space prompt to reformulate the style of the test image to fit into the pretrained model and the semantic-aware prompts to bridge high-level shape discrepancy across domains. Instead of naively imposing a fixed prompt, we introduce an input decorator to generate the self-regulating visual prompt conditioned on the input data. To retrieve the knowledge representations and customize target-specific shape prompts for each test sample, we propose a cross-attention prompt modulator, which performs interaction between target representations and an enriched shape prompt bank. Extensive experiments demonstrate the superior performance of PASS over state-of-the-art methods on multiple medical image segmentation datasets. The code is available at https://github.com/EndoluminalSurgicalVision-IMR/PASS.
SLoRD: Structural Low-Rank Descriptors for Shape Consistency in Vertebrae Segmentation
Jul 11, 2024



Automatic and precise segmentation of vertebrae from CT images is crucial for various clinical applications. However, due to a lack of explicit and strict constraints, existing methods especially for single-stage methods, still suffer from the challenge of intra-vertebrae segmentation inconsistency, which refers to multiple label predictions inside a singular vertebra. For multi-stage methods, vertebrae detection serving as the first step, is affected by the pathology and mental implants. Thus, incorrect detections cause biased patches before segmentation, then lead to inconsistent labeling and segmentation. In our work, motivated by the perspective of instance segmentation, we try to label individual and complete binary masks to address this limitation. Specifically, a contour-based network is proposed based on Structural Low-Rank Descriptors for shape consistency, termed SLoRD. These contour descriptors are acquired in a data-driven manner in advance. For a more precise representation of contour descriptors, we adopt the spherical coordinate system and devise the spherical centroid. Besides, the contour loss is designed to impose explicit consistency constraints, facilitating regressed contour points close to vertebral boundaries. Quantitative and qualitative evaluations on VerSe 2019 demonstrate the superior performance of our framework over other single-stage and multi-stage state-of-the-art (SOTA) methods.
RESTORE: Towards Feature Shift for Vision-Language Prompt Learning
Mar 10, 2024



Prompt learning is effective for fine-tuning foundation models to improve their generalization across a variety of downstream tasks. However, the prompts that are independently optimized along a single modality path, may sacrifice the vision-language alignment of pre-trained models in return for improved performance on specific tasks and classes, leading to poorer generalization. In this paper, we first demonstrate that prompt tuning along only one single branch of CLIP (e.g., language or vision) is the reason why the misalignment occurs. Without proper regularization across the learnable parameters in different modalities, prompt learning violates the original pre-training constraints inherent in the two-tower architecture. To address such misalignment, we first propose feature shift, which is defined as the variation of embeddings after introducing the learned prompts, to serve as an explanatory tool. We dive into its relation with generalizability and thereafter propose RESTORE, a multi-modal prompt learning method that exerts explicit constraints on cross-modal consistency. To be more specific, to prevent feature misalignment, a feature shift consistency is introduced to synchronize inter-modal feature shifts by measuring and regularizing the magnitude of discrepancy during prompt tuning. In addition, we propose a "surgery" block to avoid short-cut hacking, where cross-modal misalignment can still be severe if the feature shift of each modality varies drastically at the same rate. It is implemented as feed-forward adapters upon both modalities to alleviate the misalignment problem. Extensive experiments on 15 datasets demonstrate that our method outperforms the state-of-the-art prompt tuning methods without compromising feature alignment.
AC-Norm: Effective Tuning for Medical Image Analysis via Affine Collaborative Normalization
Jul 28, 2023



Driven by the latest trend towards self-supervised learning (SSL), the paradigm of "pretraining-then-finetuning" has been extensively explored to enhance the performance of clinical applications with limited annotations. Previous literature on model finetuning has mainly focused on regularization terms and specific policy models, while the misalignment of channels between source and target models has not received sufficient attention. In this work, we revisited the dynamics of batch normalization (BN) layers and observed that the trainable affine parameters of BN serve as sensitive indicators of domain information. Therefore, Affine Collaborative Normalization (AC-Norm) is proposed for finetuning, which dynamically recalibrates the channels in the target model according to the cross-domain channel-wise correlations without adding extra parameters. Based on a single-step backpropagation, AC-Norm can also be utilized to measure the transferability of pretrained models. We evaluated AC-Norm against the vanilla finetuning and state-of-the-art fine-tuning methods on transferring diverse pretrained models to the diabetic retinopathy grade classification, retinal vessel segmentation, CT lung nodule segmentation/classification, CT liver-tumor segmentation and MRI cardiac segmentation tasks. Extensive experiments demonstrate that AC-Norm unanimously outperforms the vanilla finetuning by up to 4% improvement, even under significant domain shifts where the state-of-the-art methods bring no gains. We also prove the capability of AC-Norm in fast transferability estimation. Our code is available at https://github.com/EndoluminalSurgicalVision-IMR/ACNorm.
Dive into Self-Supervised Learning for Medical Image Analysis: Data, Models and Tasks
Sep 25, 2022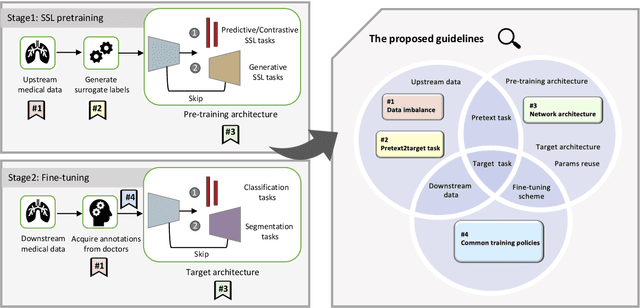
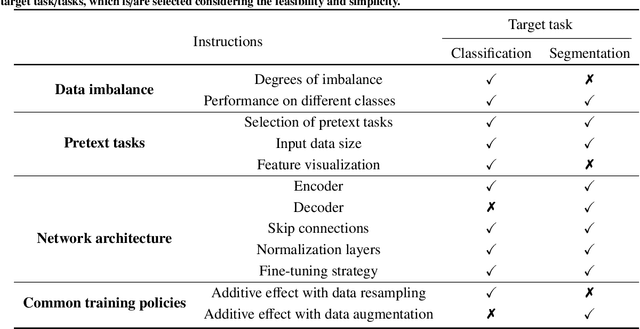
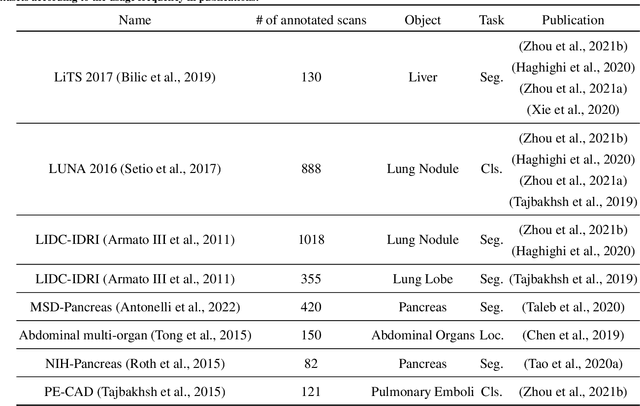
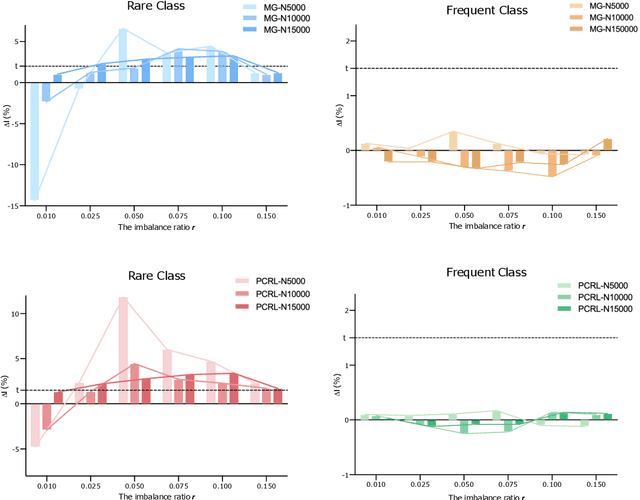
Self-supervised learning (SSL) has achieved remarkable performance on various medical imaging tasks by dint of priors from massive unlabeled data. However, for a specific downstream task, there is still a lack of an instruction book on how to select suitable pretext tasks and implementation details. In this work, we first review the latest applications of self-supervised methods in the field of medical imaging analysis. Then, we conduct extensive experiments to explore four significant issues in SSL for medical imaging, including (1) the effect of self-supervised pretraining on imbalanced datasets, (2) network architectures, (3) the applicability of upstream tasks to downstream tasks and (4) the stacking effect of SSL and commonly used policies for deep learning, including data resampling and augmentation. Based on the experimental results, potential guidelines are presented for self-supervised pretraining in medical imaging. Finally, we discuss future research directions and raise issues to be aware of when designing new SSL methods and paradigms.