 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDive into Self-Supervised Learning for Medical Image Analysis: Data, Models and Tasks
Paper and Code
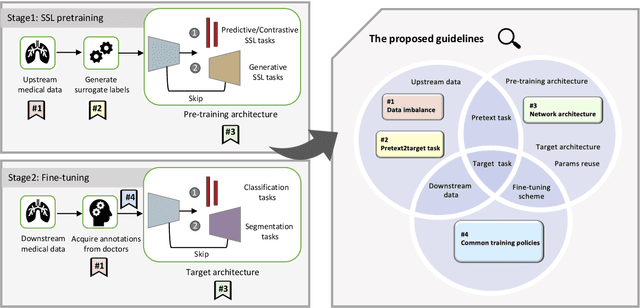
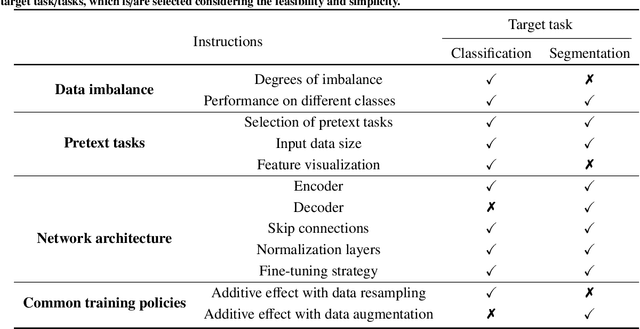
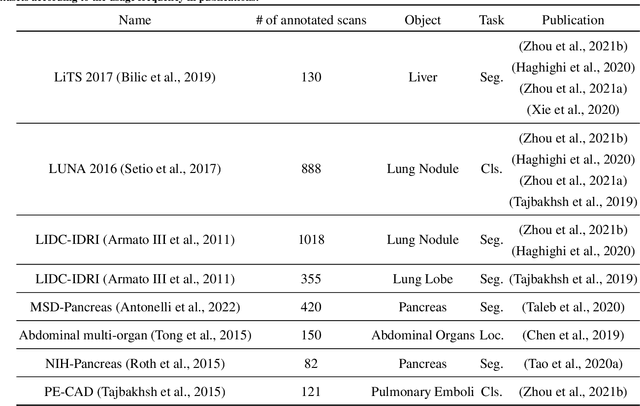
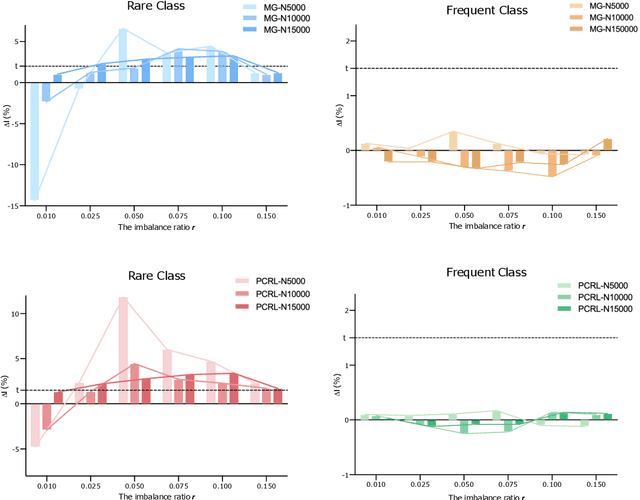
Self-supervised learning (SSL) has achieved remarkable performance on various medical imaging tasks by dint of priors from massive unlabeled data. However, for a specific downstream task, there is still a lack of an instruction book on how to select suitable pretext tasks and implementation details. In this work, we first review the latest applications of self-supervised methods in the field of medical imaging analysis. Then, we conduct extensive experiments to explore four significant issues in SSL for medical imaging, including (1) the effect of self-supervised pretraining on imbalanced datasets, (2) network architectures, (3) the applicability of upstream tasks to downstream tasks and (4) the stacking effect of SSL and commonly used policies for deep learning, including data resampling and augmentation. Based on the experimental results, potential guidelines are presented for self-supervised pretraining in medical imaging. Finally, we discuss future research directions and raise issues to be aware of when designing new SSL methods and paradigms.