 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-LoRA: Efficient Sharpness-Aware Minimization for Fine-Tuning Large-Scale Models
Aug 27, 2025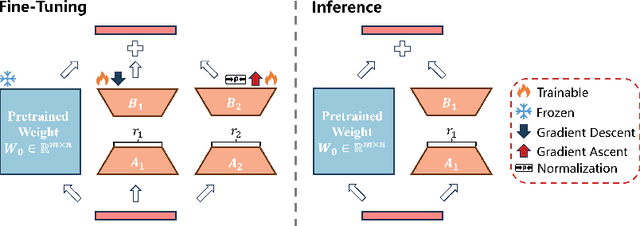

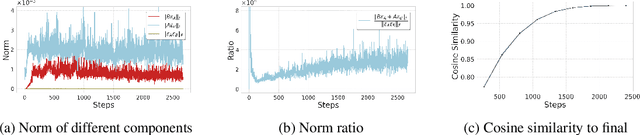

Fine-tuning large-scale pre-trained models with limited data presents significant challenges for generalization. While Sharpness-Aware Minimization (SAM) has proven effective in improving generalization by seeking flat minima, its substantial extra memory and computation overhead make it impractical for large models. Integrating SAM with parameter-efficient fine-tuning methods like Low-Rank Adaptation (LoRA) is a promising direction. However, we find that directly applying SAM to LoRA parameters limits the sharpness optimization to a restricted subspace, hindering its effectiveness. To address this limitation, we propose Bi-directional Low-Rank Adaptation (Bi-LoRA), which introduces an auxiliary LoRA module to model SAM's adversarial weight perturbations. It decouples SAM's weight perturbations from LoRA optimization: the primary LoRA module adapts to specific tasks via standard gradient descent, while the auxiliary module captures the sharpness of the loss landscape through gradient ascent. Such dual-module design enables Bi-LoRA to capture broader sharpness for achieving flatter minima while remaining memory-efficient. Another important benefit is that the dual design allows for simultaneous optimization and perturbation, eliminating SAM's doubled training costs. Extensive experiments across diverse tasks and architectures demonstrate Bi-LoRA's efficiency and effectiveness in enhancing generalization.
DDoS: Diffusion Distribution Similarity for Out-of-Distribution Detection
Sep 16, 2024



Out-of-Distribution (OoD) detection determines whether the given samples are from the training distribution of the classifier-under-protection, i.e., the In-Distribution (InD), or from a different OoD. Latest researches introduce diffusion models pre-trained on InD data to advocate OoD detection by transferring an OoD image into a generated one that is close to InD, so that one could capture the distribution disparities between original and generated images to detect OoD data. Existing diffusion-based detectors adopt perceptual metrics on the two images to measure such disparities, but ignore a fundamental fact: Perceptual metrics are devised essentially for human-perceived similarities of low-level image patterns, e.g., textures and colors, and are not advisable in evaluating distribution disparities, since images with different low-level patterns could possibly come from the same distribution. To address this issue, we formulate a diffusion-based detection framework that considers the distribution similarity between a tested image and its generated counterpart via a novel proper similarity metric in the informative feature space and probability space learned by the classifier-under-protection. An anomaly-removal strategy is further presented to enlarge such distribution disparities by removing abnormal OoD information in the feature space to facilitate the detection. Extensive empirical results unveil the insufficiency of perceptual metrics and the effectiveness of our distribution similarity framework with new state-of-the-art detection performance.
RESTORE: Towards Feature Shift for Vision-Language Prompt Learning
Mar 10, 2024



Prompt learning is effective for fine-tuning foundation models to improve their generalization across a variety of downstream tasks. However, the prompts that are independently optimized along a single modality path, may sacrifice the vision-language alignment of pre-trained models in return for improved performance on specific tasks and classes, leading to poorer generalization. In this paper, we first demonstrate that prompt tuning along only one single branch of CLIP (e.g., language or vision) is the reason why the misalignment occurs. Without proper regularization across the learnable parameters in different modalities, prompt learning violates the original pre-training constraints inherent in the two-tower architecture. To address such misalignment, we first propose feature shift, which is defined as the variation of embeddings after introducing the learned prompts, to serve as an explanatory tool. We dive into its relation with generalizability and thereafter propose RESTORE, a multi-modal prompt learning method that exerts explicit constraints on cross-modal consistency. To be more specific, to prevent feature misalignment, a feature shift consistency is introduced to synchronize inter-modal feature shifts by measuring and regularizing the magnitude of discrepancy during prompt tuning. In addition, we propose a "surgery" block to avoid short-cut hacking, where cross-modal misalignment can still be severe if the feature shift of each modality varies drastically at the same rate. It is implemented as feed-forward adapters upon both modalities to alleviate the misalignment problem. Extensive experiments on 15 datasets demonstrate that our method outperforms the state-of-the-art prompt tuning methods without compromising feature alignment.
TD^2-Net: Toward Denoising and Debiasing for Dynamic Scene Graph Generation
Jan 23, 2024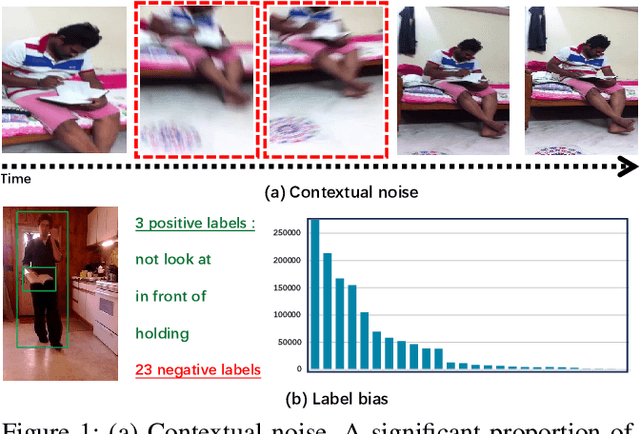
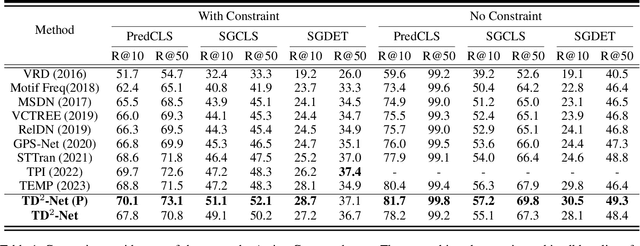
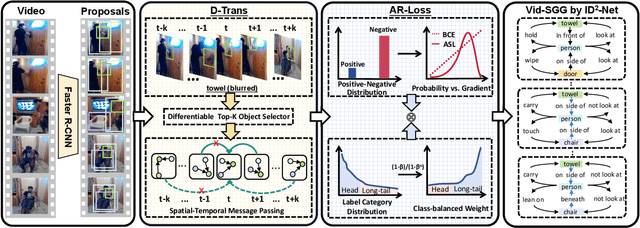
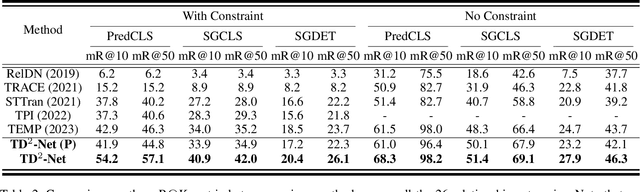
Dynamic scene graph generation (SGG) focuses on detecting objects in a video and determining their pairwise relationships. Existing dynamic SGG methods usually suffer from several issues, including 1) Contextual noise, as some frames might contain occluded and blurred objects. 2) Label bias, primarily due to the high imbalance between a few positive relationship samples and numerous negative ones. Additionally, the distribution of relationships exhibits a long-tailed pattern. To address the above problems, in this paper, we introduce a network named TD$^2$-Net that aims at denoising and debiasing for dynamic SGG. Specifically, we first propose a denoising spatio-temporal transformer module that enhances object representation with robust contextual information. This is achieved by designing a differentiable Top-K object selector that utilizes the gumbel-softmax sampling strategy to select the relevant neighborhood for each object. Second, we introduce an asymmetrical reweighting loss to relieve the issue of label bias. This loss function integrates asymmetry focusing factors and the volume of samples to adjust the weights assigned to individual samples. Systematic experimental results demonstrate the superiority of our proposed TD$^2$-Net over existing state-of-the-art approaches on Action Genome databases. In more detail, TD$^2$-Net outperforms the second-best competitors by 12.7 \% on mean-Recall@10 for predicate classification.
MMoT: Mixture-of-Modality-Tokens Transformer for Composed Multimodal Conditional Image Synthesis
May 10, 2023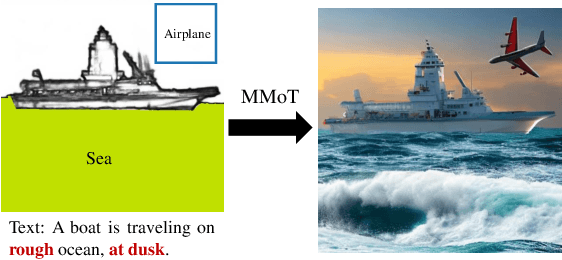
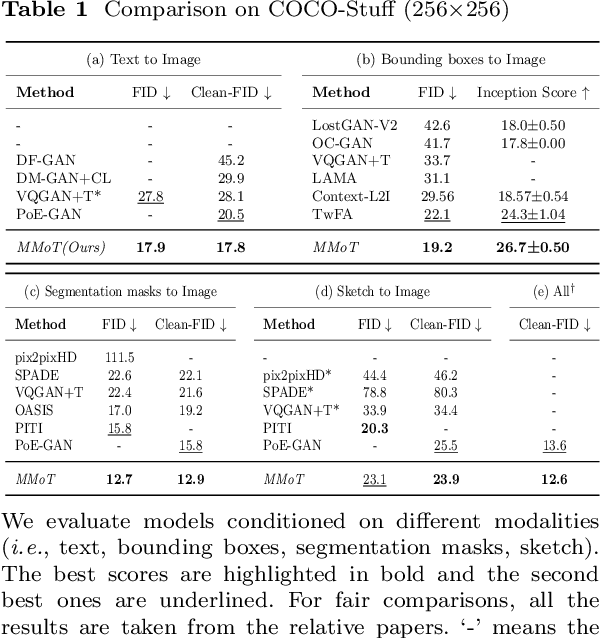
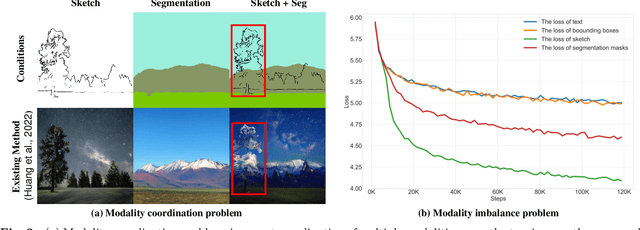
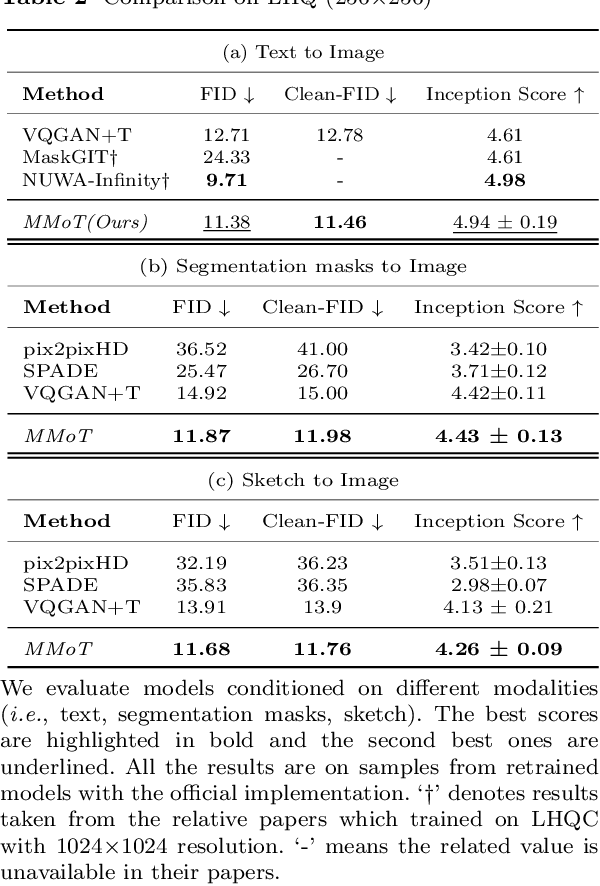
Existing multimodal conditional image synthesis (MCIS) methods generate images conditioned on any combinations of various modalities that require all of them must be exactly conformed, hindering the synthesis controllability and leaving the potential of cross-modality under-exploited. To this end, we propose to generate images conditioned on the compositions of multimodal control signals, where modalities are imperfectly complementary, i.e., composed multimodal conditional image synthesis (CMCIS). Specifically, we observe two challenging issues of the proposed CMCIS task, i.e., the modality coordination problem and the modality imbalance problem. To tackle these issues, we introduce a Mixture-of-Modality-Tokens Transformer (MMoT) that adaptively fuses fine-grained multimodal control signals, a multimodal balanced training loss to stabilize the optimization of each modality, and a multimodal sampling guidance to balance the strength of each modality control signal. Comprehensive experimental results demonstrate that MMoT achieves superior performance on both unimodal conditional image synthesis (UCIS) and MCIS tasks with high-quality and faithful image synthesis on complex multimodal conditions. The project website is available at https://jabir-zheng.github.io/MMoT.
Eliminating Prior Bias for Semantic Image Editing via Dual-Cycle Diffusion
Feb 07, 2023The recent success of text-to-image generation diffusion models has also revolutionized semantic image editing, enabling the manipulation of images based on query/target texts. Despite these advancements, a significant challenge lies in the potential introduction of prior bias in pre-trained models during image editing, e.g., making unexpected modifications to inappropriate regions. To this point, we present a novel Dual-Cycle Diffusion model that addresses the issue of prior bias by generating an unbiased mask as the guidance of image editing. The proposed model incorporates a Bias Elimination Cycle that consists of both a forward path and an inverted path, each featuring a Structural Consistency Cycle to ensure the preservation of image content during the editing process. The forward path utilizes the pre-trained model to produce the edited image, while the inverted path converts the result back to the source image. The unbiased mask is generated by comparing differences between the processed source image and the edited image to ensure that both conform to the same distribution. Our experiments demonstrate the effectiveness of the proposed method, as it significantly improves the D-CLIP score from 0.272 to 0.283. The code will be available at https://github.com/JohnDreamer/DualCycleDiffsion.
Unified Discrete Diffusion for Simultaneous Vision-Language Generation
Nov 27, 2022



The recently developed discrete diffusion models perform extraordinarily well in the text-to-image task, showing significant promise for handling the multi-modality signals. In this work, we harness these traits and present a unified multimodal generation model that can conduct both the "modality translation" and "multi-modality generation" tasks using a single model, performing text-based, image-based, and even vision-language simultaneous generation. Specifically, we unify the discrete diffusion process for multimodal signals by proposing a unified transition matrix. Moreover, we design a mutual attention module with fused embedding layer and a unified objective function to emphasise the inter-modal linkages, which are vital for multi-modality generation. Extensive experiments indicate that our proposed method can perform comparably to the state-of-the-art solutions in various generation tasks.
Modeling Image Composition for Complex Scene Generation
Jun 02, 2022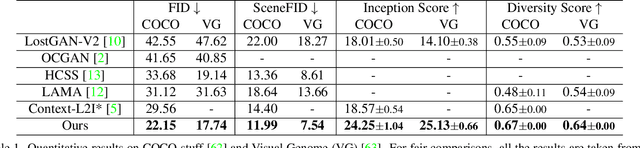
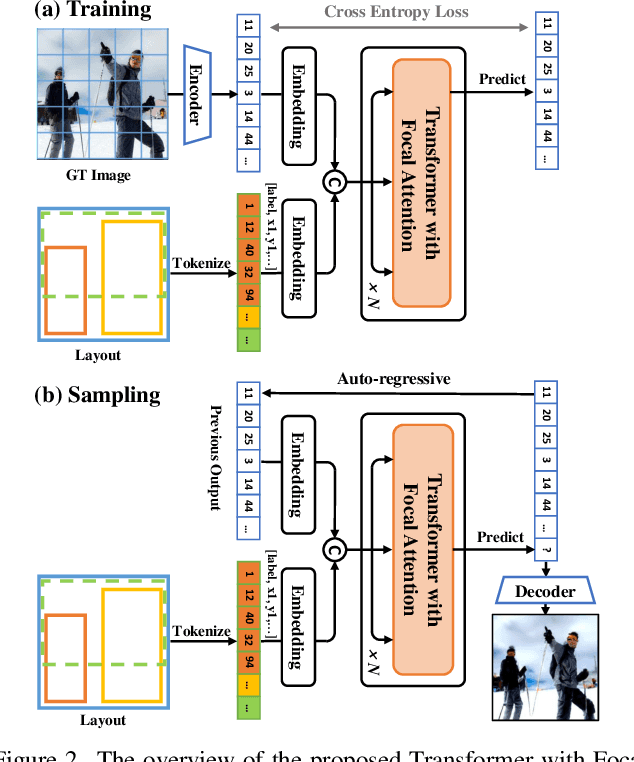

We present a method that achieves state-of-the-art results on challenging (few-shot) layout-to-image generation tasks by accurately modeling textures, structures and relationships contained in a complex scene. After compressing RGB images into patch tokens, we propose the Transformer with Focal Attention (TwFA) for exploring dependencies of object-to-object, object-to-patch and patch-to-patch. Compared to existing CNN-based and Transformer-based generation models that entangled modeling on pixel-level&patch-level and object-level&patch-level respectively, the proposed focal attention predicts the current patch token by only focusing on its highly-related tokens that specified by the spatial layout, thereby achieving disambiguation during training. Furthermore, the proposed TwFA largely increases the data efficiency during training, therefore we propose the first few-shot complex scene generation strategy based on the well-trained TwFA. Comprehensive experiments show the superiority of our method, which significantly increases both quantitative metrics and qualitative visual realism with respect to state-of-the-art CNN-based and transformer-based methods. Code is available at https://github.com/JohnDreamer/TwFA.