 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLOW: Interpretable Low-Rank Frequency Magnitude Decomposition of Multiple Effects for Time Series Forecasting
Mar 19, 2026Separating multiple effects in time series is fundamental yet challenging for time-series forecasting (TSF). However, existing TSF models cannot effectively learn interpretable multi-effect decomposition by their smoothing-based temporal techniques. Here, a new interpretable frequency-based decomposition pipeline MLOW captures the insight: a time series can be represented as a magnitude spectrum multiplied by the corresponding phase-aware basis functions, and the magnitude spectrum distribution of a time series always exhibits observable patterns for different effects. MLOW learns a low-rank representation of the magnitude spectrum to capture dominant trending and seasonal effects. We explore low-rank methods, including PCA, NMF, and Semi-NMF, and find that none can simultaneously achieve interpretable, efficient and generalizable decomposition. Thus, we propose hyperplane-nonnegative matrix factorization (Hyperplane-NMF). Further, to address the frequency (spectral) leakage restricting high-quality low-rank decomposition, MLOW enables a flexible selection of input horizons and frequency levels via a mathematical mechanism. Visual analysis demonstrates that MLOW enables interpretable and hierarchical multiple-effect decomposition, robust to noises. It can also enable plug-and-play in existing TSF backbones with remarkable performance improvement but minimal architectural modifications.
Machine Unlearning in Low-Dimensional Feature Subspace
Jan 30, 2026Machine Unlearning (MU) aims at removing the influence of specific data from a pretrained model while preserving performance on the remaining data. In this work, a novel perspective for MU is presented upon low-dimensional feature subspaces, which gives rise to the potentials of separating the remaining and forgetting data herein. This separability motivates our LOFT, a method that proceeds unlearning in a LOw-dimensional FeaTure subspace from the pretrained model skithrough principal projections, which are optimized to maximally capture the information of the remaining data and meanwhile diminish that of the forgetting data. In training, LOFT simply optimizes a small-size projection matrix flexibly plugged into the pretrained model, and only requires one-shot feature fetching from the pretrained backbone instead of repetitively accessing the raw data. Hence, LOFT mitigates two critical issues in mainstream MU methods, i.e., the privacy leakage risk from massive data reload and the inefficiency of updates to the entire pretrained model. Extensive experiments validate the significantly lower computational overhead and superior unlearning performance of LOFT across diverse models, datasets, tasks, and applications. Code is anonymously available at https://anonymous.4open.science/r/4352/.
FIT: Defying Catastrophic Forgetting in Continual LLM Unlearning
Jan 29, 2026Large language models (LLMs) demonstrate impressive capabilities across diverse tasks but raise concerns about privacy, copyright, and harmful materials. Existing LLM unlearning methods rarely consider the continual and high-volume nature of real-world deletion requests, which can cause utility degradation and catastrophic forgetting as requests accumulate. To address this challenge, we introduce \fit, a framework for continual unlearning that handles large numbers of deletion requests while maintaining robustness against both catastrophic forgetting and post-unlearning recovery. \fit mitigates degradation through rigorous data \underline{F}iltering, \underline{I}mportance-aware updates, and \underline{T}argeted layer attribution, enabling stable performance across long sequences of unlearning operations and achieving a favorable balance between forgetting effectiveness and utility retention. To support realistic evaluation, we present \textbf{PCH}, a benchmark covering \textbf{P}ersonal information, \textbf{C}opyright, and \textbf{H}armful content in sequential deletion scenarios, along with two symmetric metrics, Forget Degree (F.D.) and Retain Utility (R.U.), which jointly assess forgetting quality and utility preservation. Extensive experiments on four open-source LLMs with hundreds of deletion requests show that \fit achieves the strongest trade-off between F.D. and R.U., surpasses existing methods on MMLU, CommonsenseQA, and GSM8K, and remains resistant against both relearning and quantization recovery attacks.
Estimating quantum relative entropies on quantum computers
Jan 13, 2025



Quantum relative entropy, a quantum generalization of the well-known Kullback-Leibler divergence, serves as a fundamental measure of the distinguishability between quantum states and plays a pivotal role in quantum information science. Despite its importance, efficiently estimating quantum relative entropy between two quantum states on quantum computers remains a significant challenge. In this work, we propose the first quantum algorithm for estimating quantum relative entropy and Petz R\'{e}nyi divergence from two unknown quantum states on quantum computers, addressing open problems highlighted in [Phys. Rev. A 109, 032431 (2024)] and [IEEE Trans. Inf. Theory 70, 5653-5680 (2024)]. This is achieved by combining quadrature approximations of relative entropies, the variational representation of quantum f-divergences, and a new technique for parameterizing Hermitian polynomial operators to estimate their traces with quantum states. Notably, the circuit size of our algorithm is at most 2n+1 with n being the number of qubits in the quantum states and it is directly applicable to distributed scenarios, where quantum states to be compared are hosted on cross-platform quantum computers. We validate our algorithm through numerical simulations, laying the groundwork for its future deployment on quantum hardware devices.
Baichuan Alignment Technical Report
Oct 19, 2024



We introduce Baichuan Alignment, a detailed analysis of the alignment techniques employed in the Baichuan series of models. This represents the industry's first comprehensive account of alignment methodologies, offering valuable insights for advancing AI research. We investigate the critical components that enhance model performance during the alignment process, including optimization methods, data strategies, capability enhancements, and evaluation processes. The process spans three key stages: Prompt Augmentation System (PAS), Supervised Fine-Tuning (SFT), and Preference Alignment. The problems encountered, the solutions applied, and the improvements made are thoroughly recorded. Through comparisons across well-established benchmarks, we highlight the technological advancements enabled by Baichuan Alignment. Baichuan-Instruct is an internal model, while Qwen2-Nova-72B and Llama3-PBM-Nova-70B are instruct versions of the Qwen2-72B and Llama-3-70B base models, optimized through Baichuan Alignment. Baichuan-Instruct demonstrates significant improvements in core capabilities, with user experience gains ranging from 17% to 28%, and performs exceptionally well on specialized benchmarks. In open-source benchmark evaluations, both Qwen2-Nova-72B and Llama3-PBM-Nova-70B consistently outperform their respective official instruct versions across nearly all datasets. This report aims to clarify the key technologies behind the alignment process, fostering a deeper understanding within the community. Llama3-PBM-Nova-70B model is available at https://huggingface.co/PKU-Baichuan-MLSystemLab/Llama3-PBM-Nova-70B.
DDoS: Diffusion Distribution Similarity for Out-of-Distribution Detection
Sep 16, 2024



Out-of-Distribution (OoD) detection determines whether the given samples are from the training distribution of the classifier-under-protection, i.e., the In-Distribution (InD), or from a different OoD. Latest researches introduce diffusion models pre-trained on InD data to advocate OoD detection by transferring an OoD image into a generated one that is close to InD, so that one could capture the distribution disparities between original and generated images to detect OoD data. Existing diffusion-based detectors adopt perceptual metrics on the two images to measure such disparities, but ignore a fundamental fact: Perceptual metrics are devised essentially for human-perceived similarities of low-level image patterns, e.g., textures and colors, and are not advisable in evaluating distribution disparities, since images with different low-level patterns could possibly come from the same distribution. To address this issue, we formulate a diffusion-based detection framework that considers the distribution similarity between a tested image and its generated counterpart via a novel proper similarity metric in the informative feature space and probability space learned by the classifier-under-protection. An anomaly-removal strategy is further presented to enlarge such distribution disparities by removing abnormal OoD information in the feature space to facilitate the detection. Extensive empirical results unveil the insufficiency of perceptual metrics and the effectiveness of our distribution similarity framework with new state-of-the-art detection performance.
PAS: Data-Efficient Plug-and-Play Prompt Augmentation System
Jul 11, 2024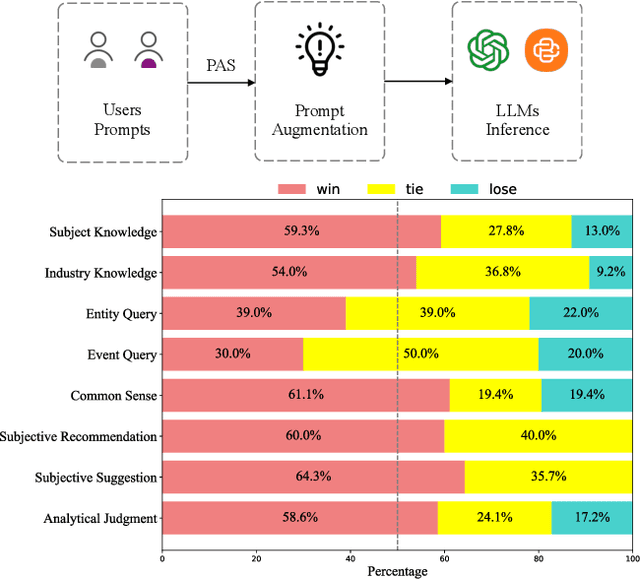
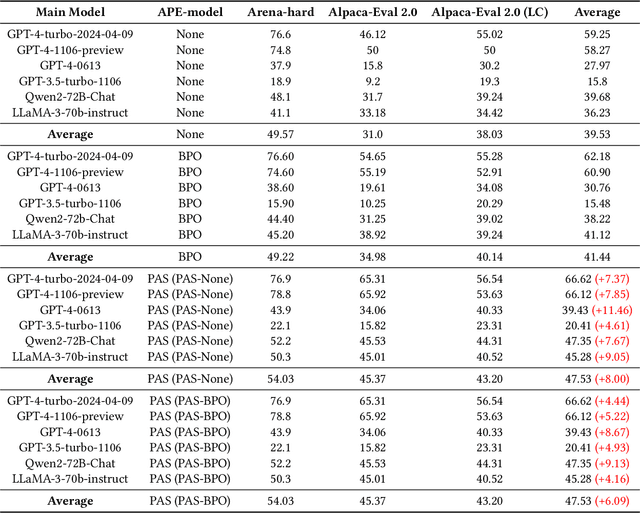

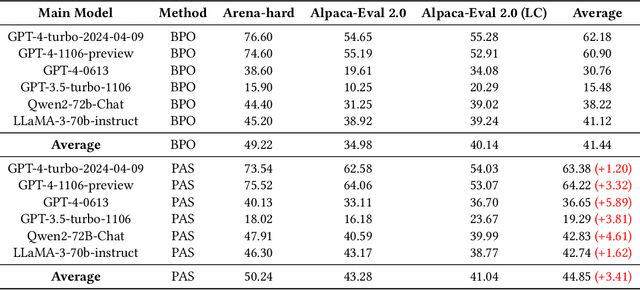
In recent years, the rise of Large Language Models (LLMs) has spurred a growing demand for plug-and-play AI systems. Among the various AI techniques, prompt engineering stands out as particularly significant. However, users often face challenges in writing prompts due to the steep learning curve and significant time investment, and existing automatic prompt engineering (APE) models can be difficult to use. To address this issue, we propose PAS, an LLM-based plug-and-play APE system. PAS utilizes LLMs trained on high-quality, automatically generated prompt complementary datasets, resulting in exceptional performance. In comprehensive benchmarks, PAS achieves state-of-the-art (SoTA) results compared to previous APE models, with an average improvement of 6.09 points. Moreover, PAS is highly efficient, achieving SoTA performance with only 9000 data points. Additionally, PAS can autonomously generate prompt augmentation data without requiring additional human labor. Its flexibility also allows it to be compatible with all existing LLMs and applicable to a wide range of tasks. PAS excels in human evaluations, underscoring its suitability as a plug-in for users. This combination of high performance, efficiency, and flexibility makes PAS a valuable system for enhancing the usability and effectiveness of LLMs through improved prompt engineering.
DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
Jun 09, 2024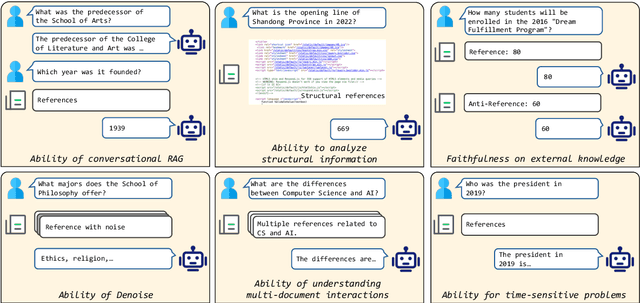
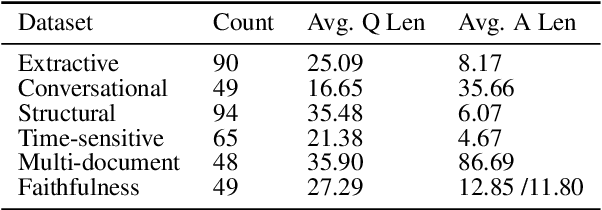
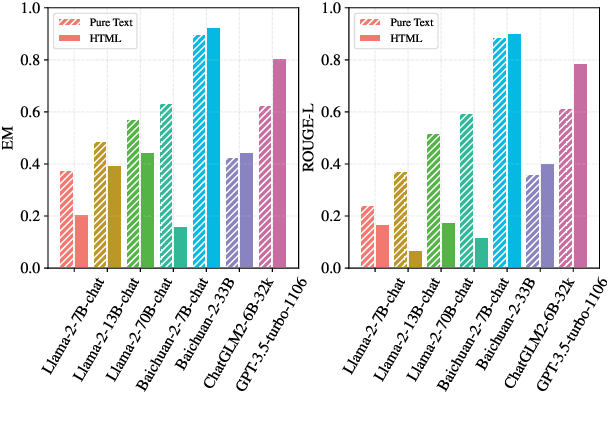
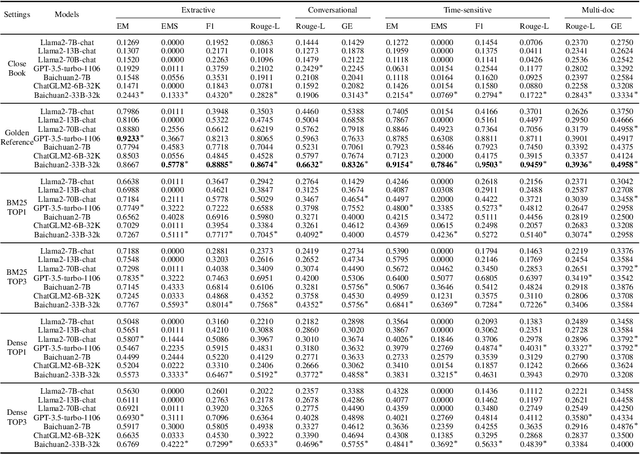
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.
Revisiting Random Weight Perturbation for Efficiently Improving Generalization
Mar 30, 2024



Improving the generalization ability of modern deep neural networks (DNNs) is a fundamental challenge in machine learning. Two branches of methods have been proposed to seek flat minima and improve generalization: one led by sharpness-aware minimization (SAM) minimizes the worst-case neighborhood loss through adversarial weight perturbation (AWP), and the other minimizes the expected Bayes objective with random weight perturbation (RWP). While RWP offers advantages in computation and is closely linked to AWP on a mathematical basis, its empirical performance has consistently lagged behind that of AWP. In this paper, we revisit the use of RWP for improving generalization and propose improvements from two perspectives: i) the trade-off between generalization and convergence and ii) the random perturbation generation. Through extensive experimental evaluations, we demonstrate that our enhanced RWP methods achieve greater efficiency in enhancing generalization, particularly in large-scale problems, while also offering comparable or even superior performance to SAM. The code is released at https://github.com/nblt/mARWP.
Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs
Feb 22, 2024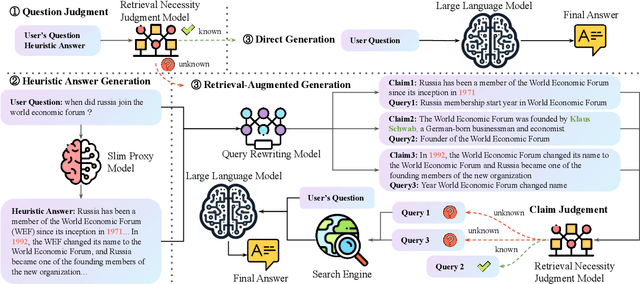
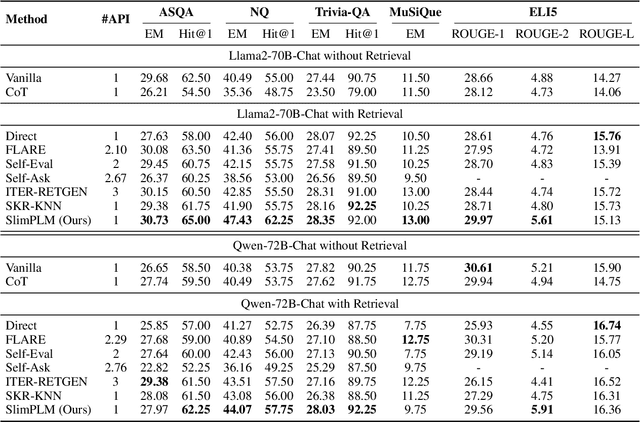
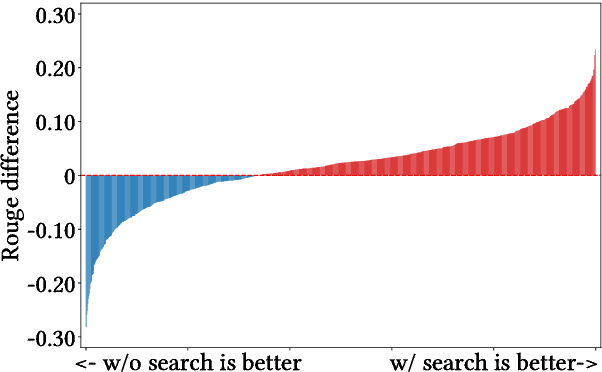
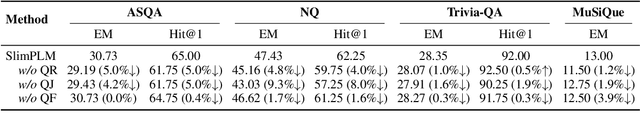
The integration of large language models (LLMs) and search engines represents a significant evolution in knowledge acquisition methodologies. However, determining the knowledge that an LLM already possesses and the knowledge that requires the help of a search engine remains an unresolved issue. Most existing methods solve this problem through the results of preliminary answers or reasoning done by the LLM itself, but this incurs excessively high computational costs. This paper introduces a novel collaborative approach, namely SlimPLM, that detects missing knowledge in LLMs with a slim proxy model, to enhance the LLM's knowledge acquisition process. We employ a proxy model which has far fewer parameters, and take its answers as heuristic answers. Heuristic answers are then utilized to predict the knowledge required to answer the user question, as well as the known and unknown knowledge within the LLM. We only conduct retrieval for the missing knowledge in questions that the LLM does not know. Extensive experimental results on five datasets with two LLMs demonstrate a notable improvement in the end-to-end performance of LLMs in question-answering tasks, achieving or surpassing current state-of-the-art models with lower LLM inference costs.