 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierSearch: A Hierarchical Enterprise Deep Search Framework Integrating Local and Web Searches
Aug 11, 2025Recently, large reasoning models have demonstrated strong mathematical and coding abilities, and deep search leverages their reasoning capabilities in challenging information retrieval tasks. Existing deep search works are generally limited to a single knowledge source, either local or the Web. However, enterprises often require private deep search systems that can leverage search tools over both local and the Web corpus. Simply training an agent equipped with multiple search tools using flat reinforcement learning (RL) is a straightforward idea, but it has problems such as low training data efficiency and poor mastery of complex tools. To address the above issue, we propose a hierarchical agentic deep search framework, HierSearch, trained with hierarchical RL. At the low level, a local deep search agent and a Web deep search agent are trained to retrieve evidence from their corresponding domains. At the high level, a planner agent coordinates low-level agents and provides the final answer. Moreover, to prevent direct answer copying and error propagation, we design a knowledge refiner that filters out hallucinations and irrelevant evidence returned by low-level agents. Experiments show that HierSearch achieves better performance compared to flat RL, and outperforms various deep search and multi-source retrieval-augmented generation baselines in six benchmarks across general, finance, and medical domains.
Efficient Medical VIE via Reinforcement Learning
Jun 16, 2025Visual Information Extraction (VIE) converts unstructured document images into structured formats like JSON, critical for medical applications such as report analysis and online consultations. Traditional methods rely on OCR and language models, while end-to-end multimodal models offer direct JSON generation. However, domain-specific schemas and high annotation costs limit their effectiveness in medical VIE. We base our approach on the Reinforcement Learning with Verifiable Rewards (RLVR) framework to address these challenges using only 100 annotated samples. Our approach ensures dataset diversity, a balanced precision-recall reward mechanism to reduce hallucinations and improve field coverage, and innovative sampling strategies to enhance reasoning capabilities. Fine-tuning Qwen2.5-VL-7B with our RLVR method, we achieve state-of-the-art performance on medical VIE tasks, significantly improving F1, precision, and recall. While our models excel on tasks similar to medical datasets, performance drops on dissimilar tasks, highlighting the need for domain-specific optimization. Case studies further demonstrate the value of reasoning during training and inference for VIE.
DailyQA: A Benchmark to Evaluate Web Retrieval Augmented LLMs Based on Capturing Real-World Changes
May 22, 2025We propose DailyQA, an automatically updated dynamic dataset that updates questions weekly and contains answers to questions on any given date. DailyQA utilizes daily updates from Wikipedia revision logs to implement a fully automated pipeline of data filtering, query generation synthesis, quality checking, answer extraction, and query classification. The benchmark requires large language models (LLMs) to process and answer questions involving fast-changing factual data and covering multiple domains. We evaluate several open-source and closed-source LLMs using different RAG pipelines with web search augmentation. We compare the ability of different models to process time-sensitive web information and find that rerank of web retrieval results is critical. Our results indicate that LLMs still face significant challenges in handling frequently updated information, suggesting that DailyQA benchmarking provides valuable insights into the direction of progress for LLMs and RAG systems.
DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
Jun 09, 2024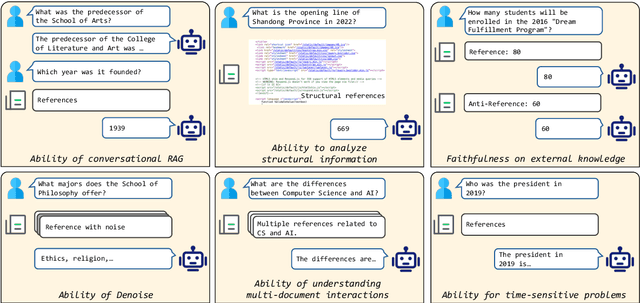
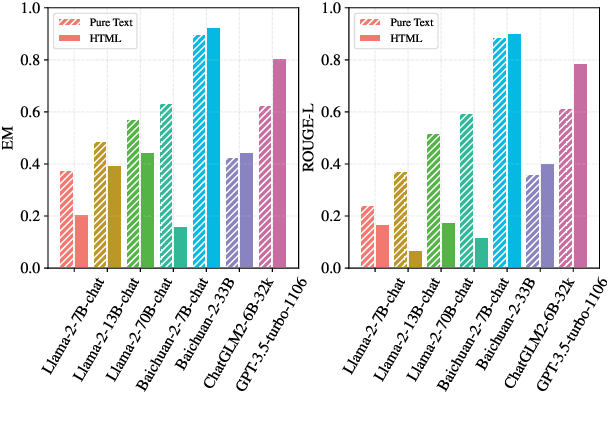
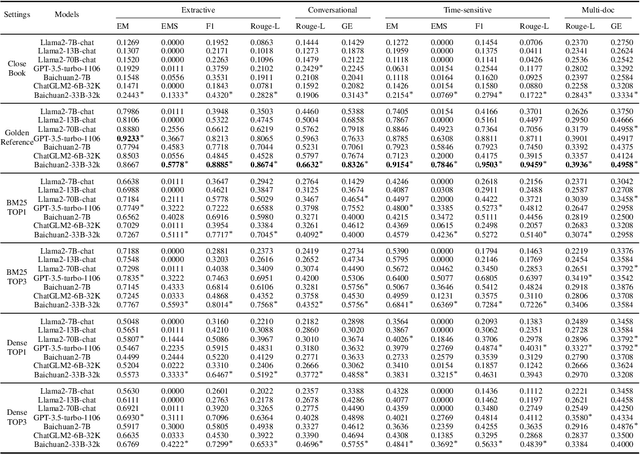
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.
RETA-LLM: A Retrieval-Augmented Large Language Model Toolkit
Jun 08, 2023

Although Large Language Models (LLMs) have demonstrated extraordinary capabilities in many domains, they still have a tendency to hallucinate and generate fictitious responses to user requests. This problem can be alleviated by augmenting LLMs with information retrieval (IR) systems (also known as retrieval-augmented LLMs). Applying this strategy, LLMs can generate more factual texts in response to user input according to the relevant content retrieved by IR systems from external corpora as references. In addition, by incorporating external knowledge, retrieval-augmented LLMs can answer in-domain questions that cannot be answered by solely relying on the world knowledge stored in parameters. To support research in this area and facilitate the development of retrieval-augmented LLM systems, we develop RETA-LLM, a {RET}reival-{A}ugmented LLM toolkit. In RETA-LLM, we create a complete pipeline to help researchers and users build their customized in-domain LLM-based systems. Compared with previous retrieval-augmented LLM systems, RETA-LLM provides more plug-and-play modules to support better interaction between IR systems and LLMs, including {request rewriting, document retrieval, passage extraction, answer generation, and fact checking} modules. Our toolkit is publicly available at https://github.com/RUC-GSAI/YuLan-IR/tree/main/RETA-LLM.