 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
Jun 09, 2024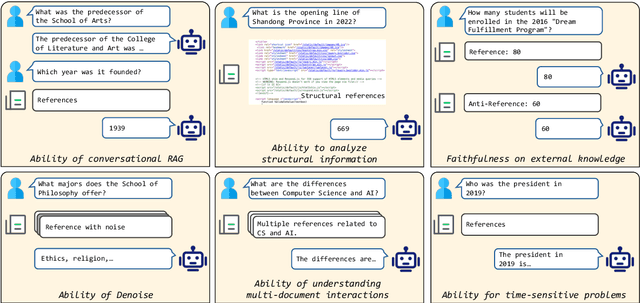
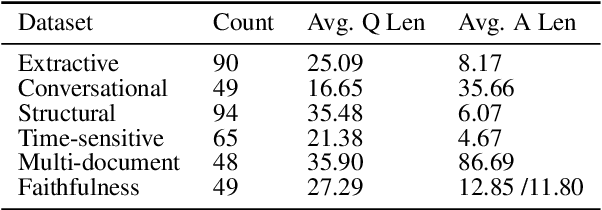
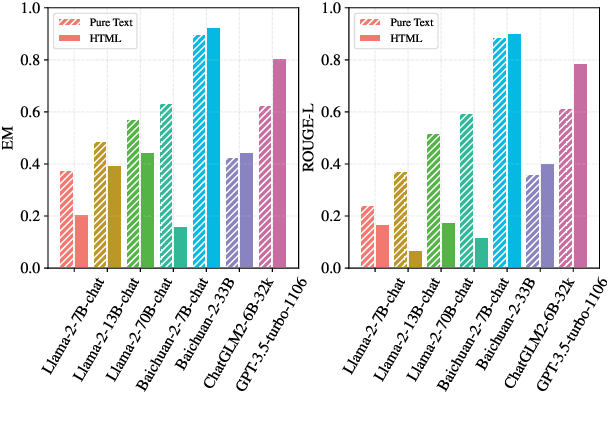
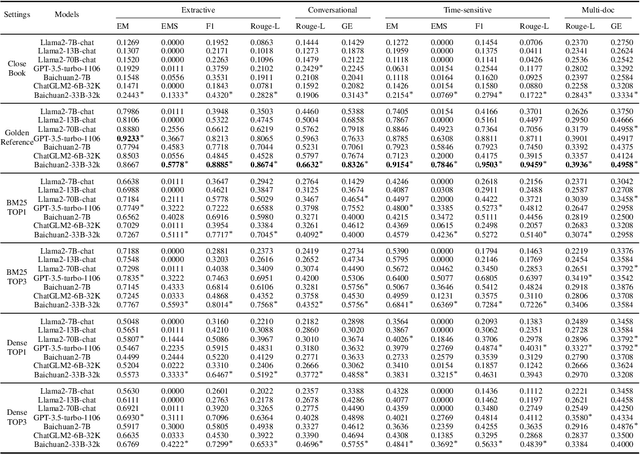
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.
Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs
Feb 22, 2024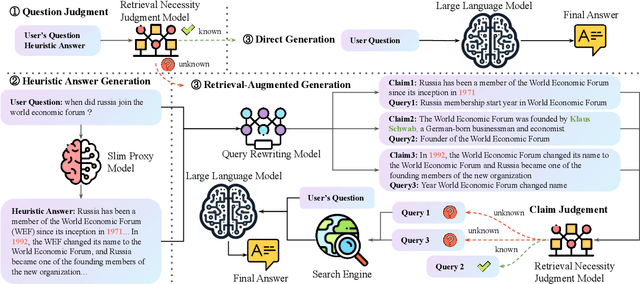
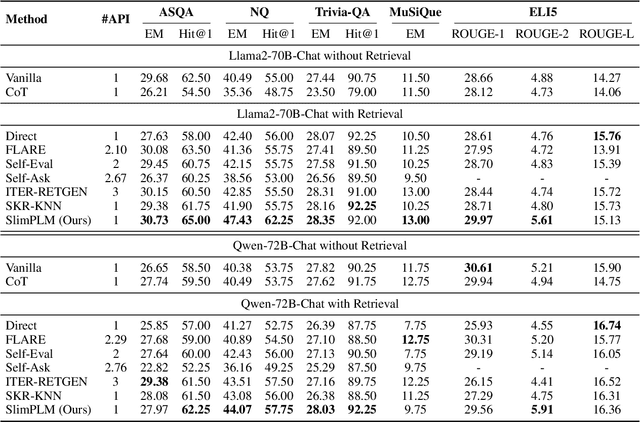
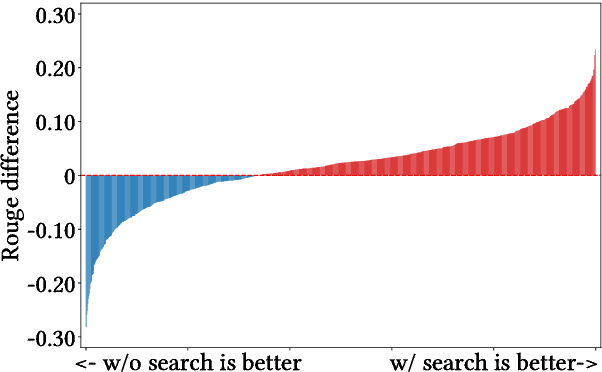
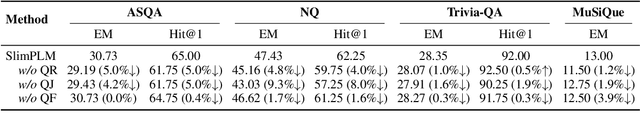
The integration of large language models (LLMs) and search engines represents a significant evolution in knowledge acquisition methodologies. However, determining the knowledge that an LLM already possesses and the knowledge that requires the help of a search engine remains an unresolved issue. Most existing methods solve this problem through the results of preliminary answers or reasoning done by the LLM itself, but this incurs excessively high computational costs. This paper introduces a novel collaborative approach, namely SlimPLM, that detects missing knowledge in LLMs with a slim proxy model, to enhance the LLM's knowledge acquisition process. We employ a proxy model which has far fewer parameters, and take its answers as heuristic answers. Heuristic answers are then utilized to predict the knowledge required to answer the user question, as well as the known and unknown knowledge within the LLM. We only conduct retrieval for the missing knowledge in questions that the LLM does not know. Extensive experimental results on five datasets with two LLMs demonstrate a notable improvement in the end-to-end performance of LLMs in question-answering tasks, achieving or surpassing current state-of-the-art models with lower LLM inference costs.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.